Python Interview questions for Data Science
This tutorial explains a python interview questions for a Data Science job role
Python Interview questions for Data Science
Hello there, Data Science aspirants! If you are looking for the most asked set of questions in interviews, then you have landed on the right place!
In this tutorial, we will be covering data science interview questions under two categories. They are
- Vanilla python based questions
- Library based questions
Lets begin with Vanilla python based questions
1. What are decorators in python? Illustrate with an example
Decorators is one of the important features in python which allows us to wrap and modify an existing object without changing its structure. For example, let us consider a function called welcome_msg which prints a welcome message. We can modify the result of this function without actually modifying it using the decorator 'uppercase_decorator'. The uppercase_decorator function takes a function as a parameter, executes it, and converts the result of that function to uppercase and then returns the new result. The welcome_msg function can be wrapped by the uppercase_decorator function using the @ symbol as follows


The output of the above code snippet would be 'HELLO WORLD'
2. What are generators in python? Illustrate with an example
Generators can be used to create user defined iterator functions. Unlike other functions, it does not return a single value but returns different values over different iterations of function call. Generally we use the yield statement rather than the return statement in generators to return values. We can define and call a generator like so.


The output of the above code snippet is
First item Second item Last item 10 20 30
3. What is the differentiate between %, /, and // in python?
- % Operator is used to obtain the modulus(i.e, remainder) of two numbers. For example 7%4 returns 3
- / Operator is used for division of two numbers. For example 7/4 returns 1.75
- // Operator is used to obtain the quotient while dividing two numbers. For example, 7//4 returns 1
4. What are lambda function in python?
Lambda functions are anonymous functions in python. These are generally used to define functions on the go especially in situations where we know that we might not use them later. These work exactly like any other function defined using the def keyword. These lambda functions are mostly used within the map and filter functions. The syntax to define a lambda function is
lambda arguments: expression
Now let us consider an example where we want to map each element of a list to a function which multiplies the element by 3. We can perform that using a lambda function like so


The output of the above function is [3, 15, 12, 18, 24, 33, 9, 36]
5. Explain the difference between map, reduce and filter functions in python
- Map function : The map method accepts a function and a sequence of iterables as parameters . It provides the output by applying the function over each iterable.
- Filter function : The filter method accepts a function and a sequence of iterables. It creates a list of elements for which the function returns true
- Reduce function : The reduce method does not return a list or sequence of values unlike map and filter methods. It takes a function (which should be performed on the first two elements of the list) and a sequence of iterables as parameters and returns a single value.
It can be easily understood with the following lines of code


The output of the above code snippet is
Map function Result : [3, 15, 12, 18, 24, 33, 9, 36] Filter function Result : [8, 11, 12] Reduce function Result : 50
I also came across a fun way to understand how these functions work. Hope this helps you understand better.

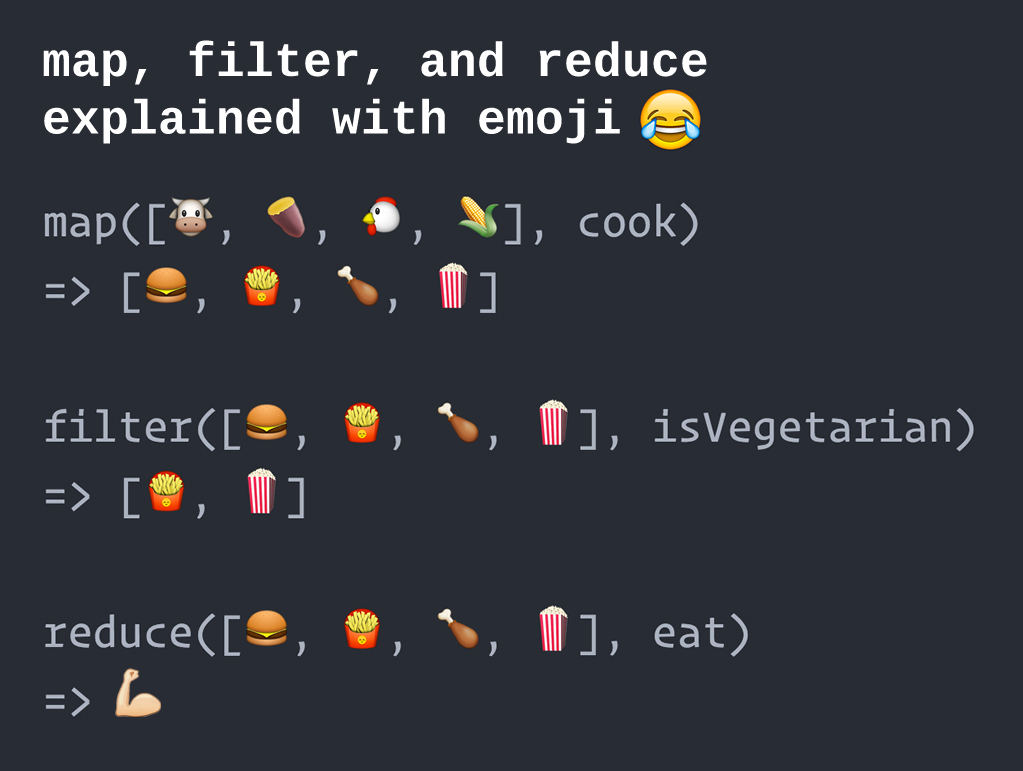
6. Explain the difference between range and xrange functions
- range : The range function returns an iterable within the specified lower ad upper bound. It has slower execution speed
- xrange : Unlike the range function, the xrange returns a generator object which can then be used by looping. Execution speed is faster if we use xrange. Although, it can be noted that this function has been renamed to range() from Python 3.
7. What do you know about list and dictionary comprehension?
List/dictionary/set comprehensions provide a short hand for the following way of writing expression code


The above 4 lines of code can be shortened to a single line like so

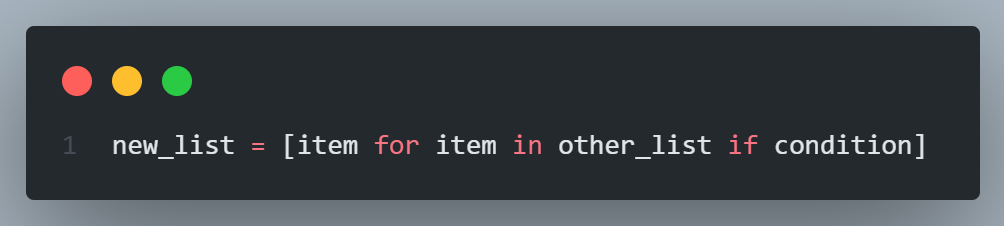
We can as well use the same kind of shorthand for dictionaries.


8. What is the difference between a list and a tuple
- The primary difference between a list and a tuple is that a list is mutable while a tuple is not mutable(i.e., immutable).
- Tuples are much more efficient than lists in terms of execution speed and memory consumption
- Lists are enclosed within square brackets while tuples are enclosed within parentheses.
9. How are negative indices used in Python?
Negative indices are generally used to access list elements from the end. In python, -1 points to the last element of the list, -2 indicates the second last element of the list and so on.
So far, we have been seeing questions from vanilla python. Now let us jump into questions that are specific to the most used libraries in python for data science.
Library based questions
a. Pandas
1. What is data aggregation in pandas?
Aggregation in pandas works similar to data aggregation in SQL. df.aggregate() can be used to perform any sort of aggregation function on a single or multiple columns of a dataframe. Take a look at the following lines of code to understand how aggregation works in pandas.
import pandas as pd
data = {'col_1': [3, 2, 1, 0], 'col_2': ['a', 'b', 'c', 'd']}
df = pd.DataFrame(data)
print(df.aggregate(sum))
The output of the above aggregate function can be

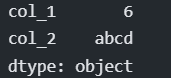
2. Differentiate series and dataframe in Pandas
Series are 1 dimensional data structure in pandas where the data has to be homogeneous. On the other hand, Dataframes are 2 dimensional data structures in pandas and the data can be heterogeneous. Series are immutable while dataframes are mutable data types in pandas.
3. Talk about vectorization in pandas
Vectorization is the process of implementing operations on the dataframe without using loops. We instead use the functions which are highly optimized. For example, if we want to calculate the sum of all the rows of a column in a dataframe, instead of looping over each row, we can use the aggregation functionality that pandas provides and calculate the sum.
4. What is the use of GroupBy in Pandas?
Groupby is used to divide the data into groups. It helps to organizes the data according to certain parameters. We can also use any other aggregation function on the separated groups.Let us understand groupby using the below example
import pandas as pd
df = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
print(df.groupby('variety').sum())
In the above code snippet, iris data is used as an example. The dataframe is grouped by different categories of the 'variety' column and then summing all the values under each category. The output looks like this.


5. What do you think are the most important features of pandas?
The important features of the library are Time series, reshaping, memory efficiency, time efficiency, vectorization, data alignment and so on.
6. What are the different ways of creating a dataframe in pandas
There are various ways of creating a dataframe in pandas. Please find the answers in this link.
b. Scikit learn
1. What happens when you call fit() multiple times on the same model do?
Calling the fit() method second time will start the training again using passed data and will remove the previously obtained results. The mmodel parameters such as the coefficients, weights and the intercepts are reset. To avoid overwriting, one can use the "warm_start" parameter, where it will initialize model parameters with the previous solution from fit().
2. How to overcome overfitting in random forest using sklearn?
In order to avoid over-fitting,we can optimize the tuning parameters that govern the number of features that are randomly chosen to grow each tree from the bootstrapped data. Obtaining more data is also a another way of overcoming this problem
3. How do you predict time series in time series in sklearn?
Generally Time Series is nothing but collection of data collected at constant time intervals . Time-series always assumes that the current value is somehow related to the past ones. Time series is based on two basic components Mean and Variance. In order to predict time series data, RNN or LSTM algorithm (Deep Learning) can been utilized, but as scikit does not provide the build-in algorithm of it, we can opt to Tensorflow or Pytorch framework which are common tools for building deep learning model. There are other libraries also like Prophet, statmodels and so on
4. What is ensemble learning?
Ensemble learning is a process that combines multiple machine learning models to create better models. There are many ensemble techniques but when aggregating multiple models there are two basic methods. They are:
- Bagging - where we take the training set and generate new training sets by creating subsets off of it.
- Boosting - where we optimize the best weighting scheme for a training set
For more machine learning interview questions, check out this tutorial!

What Users are saying..

Abhinav Agarwal
I come from Northwestern University, which is ranked 9th in the US. Although the high-quality academics at school taught me all the basics I needed, obtaining practical experience was a challenge.... Read More