What is Apache Spark?
Before we learn about Apache Spark or its use cases or how we use it, let’s see the reason behind its invention.
- Exploding Data
We are aware that today we have huge data being generated everywhere from various sources. This data is either being stored intentionally in a structured way or getting generated by machines. But data is of no use until we mine it and try to do some kind of analysis on it, in order to come up with actions based on the analysis outcomes. The act of gathering and storing information for eventual analysis is ages old but it had never been based on such a large amount of data, which is there today. There is a specific term for such voluminous data i.e. “Big Data”.

Big data is a term that describes the huge volume of data which can be structured and unstructured or semi-structured. But it’s not the amount of data which is a concern for the organizations since it is just a storage problem which can be easily addressed by the cheap storage available today. It’s what Business get out of the data matters.Big data can be analyzed for insights that lead to better decisions and strategic business moves.
This problem can be solved if we have a framework which not only gives a solution to store all kinds of data (structured, semi-structured or unstructured) but an efficient way of analyzing it according to business needs. One of such framework which is widely used is known as Hadoop. But Hadoop has several limitation (which will be discussed in later sections), because of which Apache Spark was created.
- Data Manipulation speed
Now we have a solution for our storage and also an efficient way of analyzing data of any size. That means we can make business decisions after analyzing data. But there is another challenge, which is that the decision based on the analysis insight on a huge data might not be relevant after some time. Any decision is useful if we take the action on time, but doing any analysis on huge data takes time, sometimes more than the deadline on which that action had to be performed. So in such cases such insights are of no use because the deadline for action has passed.
Learn Hadoop by working on interesting Big Data and Hadoop Projects
Processing larger scale of data with Hadoop’s processing framework i.e. MapReduce (MR) is far better than our traditional system but still not good enough for organizations to take all its decision on time, because Hadoop operates on batch processing of data leading to high latency.
Several other shortcomings of Hadoop are:
- Adherence to its MapReduce programming model
- Limited programming language API options
- Not a good fit for iterative algorithms like Machine Learning Algorithms
- Pipelining of tasks is not easy
Apache spark was developed as a solution to the above mentioned limitations of Hadoop.
What is Spark
Apache Spark is an open source data processing framework for performing Big data analytics on distributed computing cluster.
Spark was initially started by Matei Zaharia at UC Berkeley's AMPLab in 2009. It was an academic project in UC Berkley. Initially the idea was to build a cluster management tool, which can support different kind of cluster computing systems. The cluster management tool which was built as a result is Mesos. After Mesos was created, developers built a cluster computing framework on top of it, resulting in the creating of Spark.
Spark was meant to target interactive iterative computations like machine learning. In the year 2013, the spark project was passed on to the Apache Software Foundation.

Spark Features
Spark has several advantages when compared to other big data and MapReduce technologies like Hadoop and Storm. Spark is faster than MaReduce and offers low latency due to reduced disk input and output operation. Spark has the capability of in memory computation and operations, which makes the data processing really fast than other MapReduce.
Unlike Hadoop spark maintains the intermediate results in memory rather than writing every intermediate output to disk. This hugely cuts down the execution time of the operation, resulting in faster execution of task, as more as 100X time a standard MapReduce job. Apache Spark can also hold data onto the disk. When data crosses the threshold of the memory storage it is spilled to the disk. This way spark acts as an extension of MapReduce. Spark doesn’t execute the tasks immediately but maintains a chain of operations as meta-data of the job called DAG. The action on the DAG happens only when an action operation is called on to the transformation DAG. This process is called as lazy evaluation. This allows optimized execution of the queries on Big Data.
Apache Spark has other features, such as:
- Supports wide variety of operations, compared to Map and Reduce functions.
- Provides concise and consistent APIs in Scala, Java and Python.
- Spark is written in Scala Programming Language and runs in JVM.
- It currently has support in the following programming languages to develop applications in Spark:
- Scala
- Java
- Python
- R
- Features interactive shell for Scala and Python. This is not available in Java yet.
- It leverages the distributed cluster memory for doing computations for increased speed and data processing.
- Spark enables applications in Hadoop clusters to run up to as much as 100 times faster in memory and 10 times faster even when running in disk.
- It is most suitable for real time decision making with big data.
- It runs on top of existing Hadoop cluster and access Hadoop data store (HDFS), it can also process data stored by HBase structure. It can also run without Hadoop with apache Mesos or alone in standalone mode.
- Apache Spark can be integrated with various data sources like SQL, NoSQL, S3, HDFS, local file system etc.
- Good fit for iterative tasks like Machine Learning (ML) algorithms.
- In addition to Map and Reduce operations, it supports SQL like queries, streaming data, machine learning and data processing in terms of graph.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization
Hadoop and Apache Spark
Hadoop as a big data processing technology has proven to be the go to solution for processing large data sets. MapReduce is a great solution for computations, which needs one-pass to complete, but not very efficient for use cases that require multi-pass for computations and algorithms. Each stage in the data processing workflow has one Map and one Reduce phase .To leverage MapReduce solution we need to convert our use case into MapReduce pattern. The Job's output data between each step has to be stored in the file system before the next step can begin. Hence, this approach is slow, due to replication & disk Input/output operations. Also, Hadoop ecosystem doesn’t have every component to complete a big data use case. It also requires the integration of several other tools for different big data use cases (like Mahout for Machine Learning and Storm for streaming data processing, Flume for log aggregation).
If you want to do an iterative job, you would have to stitch together a sequence of MapReduce jobs and execute them in sequence. Each of those jobs has high-latency, and each depends upon the completion of previous stages. Spark allows programmers to employ complex, multi-step data pipelines using directed acyclic graph (DAG) pattern. It allows in-memory data sharing across DAGs, so that different jobs can work with the same data without going to disk.
Spark can run on top of Hadoop’s distributed file system Hadoop Distributed File System (HDFS) to leverage the distributed replicated storage. Spark can be used along with MapReduce in the same Hadoop cluster or can be used alone as a processing framework. Apache Spark is an alternative to Hadoop MapReduce rather than a replacement of Hadoop. It’s not intended to replace Hadoop but it can regarded as an extension to it. In many use cases MapReduce and Spark can be used together where MapReduce job can be used for batch processing and spark can be used for real-time processing.

Apache Spark Components and Architecture
SparkContext is an independent process through which spark application runs over a cluster. It gives the handle to the distributed mechanism/cluster so that you may use the resources of the distributed machines in your job. Your application program which will use SparkContext object would be known as driver program. Specifically, to run on a cluster, the SparkContext connects to several types of cluster managers (like Spark’s own standalone cluster manager, apache Mesos or Hadoop's YARN), which allocate resources across applications. Once connected, Spark takes over executors on distributed nodes in the cluster, which are processes in the distributed nodes that run computations and store data for your application. Next, it sends your application code to the executors through SparkContext. Finally tasks are sent to the executors to run and complete it.
Cluster overview
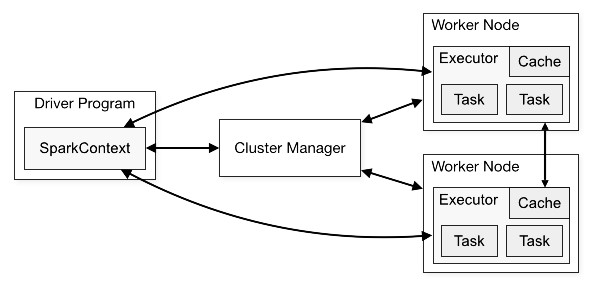
Source : spark.apache.org
Following are most important takeaways of the architecture:
- Each application gets its own executor processes, which remains in memory up to the duration of the complete application and run tasks in multiple threads. This means each application is independent from the other, on both the scheduling side since each driver schedules its own tasks and executor side as tasks from different applications run in different JVMs.
- Spark is independent of cluster managers that implies, it can be coupled with any cluster manager and then leverage that cluster.
- Because the driver schedules tasks on the cluster, it should be run as close to the worker nodes as possible.
Recommended Tutorials:
Spark Eco-sytem components

Spark Core
Spark Core is the base of an overall spark project. It is responsible for distributed task dispatching, parallelism, scheduling, and basic I/O functionalities. All the basic functionality of spark core are exposed through an API (for Java, Python, Scala, and R) centered on the RDD abstraction. A ‘driver’ program starts parallel operations such as map, filter or reduce on any RDD by passing a function to SparkCore, which further schedules the function's execution in parallel on the cluster.
Other than Spark Core API, there are additional useful and powerful libraries that are part of the Spark ecosystem and adds powerful capabilities in Big Data analytics and Machine Learning areas. These libraries include:
- Spark Streaming
Spark Streaming is a useful addition to the core Spark API. It enables high-throughput, fault-tolerant stream processing of live data streams. It is used for processing real-time streaming data. This is based on micro batch style of computing and processing. The fundamental stream unit is DStream. DStream is basically a series of RDDs, to process the real-time data.

Source : spark.apache.org
Get More Practice, More Big Data and Analytics Projects, and More guidance.Fast-Track Your Career Transition with ProjectPro
Spark SQL, DataFrames and Datasets:
- SQL
Spark SQL exposes spark APIs to run SQL query like computation on large data. A spark user can perform ad-hoc query and perform near real time ETL on a different types of data like (like JSON, Parquet, Database).
- DataFrames
A DataFrame can be considered as a distributed set of data which has been organized into many named columns. It can be compared with a relational table, CSV file or a data frame in R or Python. The DataFrame functionality is made available as API in Scala, Java, Python, and R.
- Dataset
A Dataset is a new addition in the list of spark libraries. It is an experimental interface added in Spark 1.6 that tries to provide the benefits of RDDs with the benefits of Spark SQL’s optimized execution engine.
- Spark MLlib And ML
MLlib is collective bunch few handy and useful machine learning algorithms and data cleaning and processing approaches which includes classification, clustering, regression, feature extraction, dimensionality reduction, etc. as well as underlying optimization primitives like SGD and BFGS.
- Spark GraphX
GraphX is the Spark API for graphs and graph-parallel computation. GraphX enhances the Spark RDD by introducing the Resilient Distributed Property Graph.
A RDD property graph is a directed multi-graph with properties attached with each of its vertex and edge. GraphX has a set of basic operators (like subgraph, joinVertices, aggregateMessages, etc.).Along with operators it has an optimized variant of the Pregel API. GraphX is still under development and many developers are working towards simplification of graph related tasks.
Build an Awesome Job Winning Project Portfolio with Solved End-to-End Big Data Projects
