Do you need to know machine learning in order to be able to use Apache Spark?
Apache Spark is a distributed computing platform for managing large datasets and is oftenly assoicated with machine learning. However, machine learning is not the only use case for Apache Spark , it is an excellent framework for lambda architecture applications, MapReduce applications, Streaming applications, graph based applications and for ETL.Working with a Spark instance requires no machine learning knowledge.
What are the differences between Apache Storm and Apache Spark?
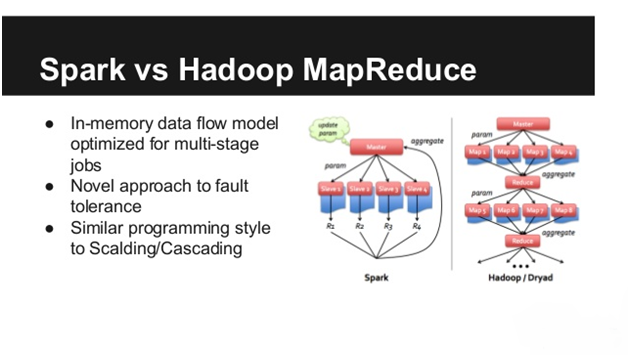
Apache Spark is an in-memory distributed data analysis platform, which is required for interative machine learning jobs, low latency batch analysis job and processing interactive graphs and queries. Apache Spark uses Resilient Distributed Datasets (RDDs). RDDs are immutable and are preffered option for pipelining parallel computational operators. Apache Spark is fault tolerant and executes Hadoop MapReduce jobs much faster.
Apache Storm on the other hand focuses on stream processing and complex event processing. Storm is generally used to transform unstructured data as it is processed into a system in a desired format.
Spark and Storm have different applications, but a fair comparison can be made between Storm and Spark streaming. In Spark streaming incoming updates are batched and get transformed to their own RDD. Individual computations are then performed on these RDDs by Spark's parallel operators. In one sentence, Storm performs Task-Parallel computations and Spark performs Data Parallel Computations.
How to read multiple text files into a single Resilient Distributed Dataset?
The objective here is to read data from multiple text files after extracting them from a HDFS location and process them as a single Resilient Distributed Dataset for further MapReduce implementation. Some of the ways to accomplish this task are mentioned below:
1. The command 'sc.textFile' can mention entire directories of HDFS, as well as multiple directories and wildcards separated by commas.
sc.textFile("/system/directory1,/system/paths/file1,/secondary_system/directory2")
2. A union function can be used to create a centralized Resilient Distributed Dataset.
var file1 = sc.textFile("/address/file1")
var file2 = sc.textFile("/address/file2")
var file3 = sc.textFile("/address/file3")
val rdds = Seq(file1, file2, file3)
var sc = new SparkContext(...)
val unifiedRDD = sc.union(rdds)
How to setup Apache Spark on Windows?
This short tutorial will help you setup Apache Spark on Windows7 in standalone mode. The prerequisites to setup Apache Spark are mentioned below:
- Scala 2.10.x
- Java 6+
- Spark 1.2.x
- Python 2.6+
- GIT
- SBT
The installation steps are as follows:
- Install Java 6 or later versions(if you haven't already). Set PATH and JAVE_HOME as environment variables.
- Download Scala 2.10.x (or 2.11) and install. Set SCALA_HOME and add %SCALA_HOME%\bin in the PATH environmental variable.
- The next step is install Spark, which can be done in either of two ways:
- Building Spark from SBT
- Using pre-built Spark package
In oder to build Spark with SBT, follow the below mentioned steps:
- Download SBT and install. Similarly as we did for Java, set PATH AND SBT_HOME as environment variables.
- Download the source code of Apache Spark suitable with your current version of Hadoop.
- Run SBT assembly and command to build the Spark package. If Hadoop is not setup, you can do that in this step.
sbt -Pyarn -pHadoop 2.3 assembly
- If you are using prebuilt package of Spark, then go through the following steps:
- Download and extract any compatible Spark prebuilt package.
- Set SPARK_HOME and add %SPARK_HOME%\bin in PATH for environment variables.
- Run this command in the prompt:
bin\spark-shell
How to save MongoDB data to parquet file format using Apache Spark?
The objective of this questions is to extract data from local MongoDB database, to alter save it in parquet file format with the hadoop-connector using Apache Spark. The first step is to convert MongoRDD variable to Spark DataFrame, which can be done by following the steps mentioned below:
1. A Case class needs to be created to represent the data saved in the DBObject.
case class Data(x: Int, s: String)
2. This is to be follwed by mapping vaues of RDD instances to the respective Case Class
val dataRDD = mongoRDD.value.map {obj => Data(obj.get("x", obj.get("s")))}
3. Using sqlContext RDD data can be converted to DataFrame
val SampleDF = sqlContext.createDataFrae(dataRDD)
What kinds of things can one do with Apache Spark Streaming?
Apache Spark Streaming is particularly meant for real-time predictions and recommendations.Spark streaming lets users run their code over a small piece of incoming stream in a scale. Few Spark use cases where Spark Streaming plays a vital role -
- You just walk by the Walmart store and the Walmart app sends you a push notification with a 20% discount on your favorite clothing brand.
- Spark streaming can also be used to get the top most visited pages of a website.
- For a stream of weblogs, fi you want to get alerts within seconds-Spark Streaming is helpful.
Load More
-
![Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem]() Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem
Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem -
![Hadoop MapReduce vs. Apache Spark Who Wins the Battle?]() Hadoop MapReduce vs. Apache Spark Who Wins the Battle?
Hadoop MapReduce vs. Apache Spark Who Wins the Battle? -
![Top 50 Hadoop Interview Questions]() Top 50 Hadoop Interview Questions
Top 50 Hadoop Interview Questions -
![5 Job Roles Available for Hadoopers]() 5 Job Roles Available for Hadoopers
5 Job Roles Available for Hadoopers -
![Top 6 Hadoop Vendors providing Big Data Solutions in Open Data Platform]() Top 6 Hadoop Vendors providing Big Data Solutions in Open Data Platform
Top 6 Hadoop Vendors providing Big Data Solutions in Open Data Platform -
![Big Data Analytics- The New Player in ICC World Cup Cricket 2015]() Big Data Analytics- The New Player in ICC World Cup Cricket 2015
Big Data Analytics- The New Player in ICC World Cup Cricket 2015 -
![5 Reasons why Java professionals should learn Hadoop]() 5 Reasons why Java professionals should learn Hadoop
5 Reasons why Java professionals should learn Hadoop