Common Machine Learning Algorithms for Beginners
Read this list of basic machine learning algorithms for beginners to get started with machine learning and learn about the popular ones with examples.


Tensorflow Transfer Learning Model for Image Classification
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectTable of Contents
- Common Machine Learning Algorithms for Beginners in Data Science
- What are machine learning algorithms?
- Types of Machine Learning Algorithms
- List of Most Used Popular Machine Learning Algorithms Every Engineer must know
- Different Machine Learning Algorithms for Beginners
- Naive Bayes Classifier Algorithm
- K Means Clustering Algorithm
- Support Vector Machines
- Apriori Algorithm
- Linear Regression
- Logistic Regression
- Decision Tree
- Random Forest
- Artificial Neural Networks
- K-Nearest Neighbors
- Advanced Machine Learning Algorithms Examples
- Gradient Boosting
- Linear Discriminant Analysis
- Quadratic Discriminant Analysis
- Principal Component Analysis
- General Additive Models (GAMs)
- Polynomial Regression
- FAQs
Common Machine Learning Algorithms for Beginners in Data Science
According to a recent study, machine learning algorithms are expected to replace 25% of the jobs across the world in the next ten years. With the rapid growth of big data and the availability of programming tools like Python and R–machine learning (ML) is gaining mainstream presence for data scientists. Machine learning applications are highly automated and self-modifying improving over time with minimal human intervention as they learn with more data. For instance, Netflix’s recommendation algorithm learns more about the likes and dislikes of a viewer based on the shows every viewer watches. Specialized machine learning algorithms have been developed to perfectly address the complex nature of various real-world data problems. For beginners who are struggling to understand the basics of machine learning, here is a brief discussion on the top machine learning algorithms used by data scientists.
What are machine learning algorithms?
A machine learning algorithm can be related to any other algorithm in computer science. An ML algorithm is a procedure that runs on data and is used for building a production-ready machine learning model. If you think of machine learning as the train to accomplish a task, machine learning algorithms will seem like the engines driving its accomplishment. Which type of algorithm in machine learning works best depends on the business problem you are solving, the nature of the dataset, and the resources available.

Types of Machine Learning Algorithms
Machine Learning algorithms are classified as –
1) Supervised Machine Learning Algorithms
Machine learning algorithms that make predictions on a given set of samples. Supervised ML algorithm searches for patterns within the value labels assigned to data points. Some popular machine learning algorithms for Supervised Learning include SVM for classification problems, Linear Regression for regression problems, and Random forest for regression and classification problems. Supervised Learning is when the data set contains annotations with output classes that form the cardinal out classes. E.g., in sentiment analysis, the output classes are happy, sad, angry, etc.
Here's what valued users are saying about ProjectPro

Gautam Vermani
Data Consultant at Confidential

Anand Kumpatla
Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd
Not sure what you are looking for?
View All Projects2) Unsupervised Machine Learning Algorithms
There are no labels associated with data points. These machine learning algorithms organize the data into a group of clusters to describe its structure and make complex data look simple and organized for analysis. Unsupervised Learning is where the output variable classes are undefined. The best example of such a classification is clustering. Clustering groups similar objects/data together, thus forming segregated clusters. Clustering also helps in finding biases in the data set. Biases are inherent dependencies in the data set that links the occurrence of values in some way.
Unsupervised Learning is relatively harder, and sometimes the clusters obtained are difficult to understand because of the lack of labels or classes.
3) Reinforcement Machine Learning Algorithms
Reinforcement Learning steers through learning a real-world problem using rewards and punishments are reinforcements. Ideally, a job or activity needs to be discovered or mastered, and the model is rewarded if it completes the job and punished when it fails. The problem with Reinforcement Learning is to figure out what kind of rewards and punishment would be suited for the model.
These algorithms choose an action based on each data point and later learn how good the decision was. Over time, the algorithm changes its strategy to know better and achieve the best reward.
New Projects
List of Most Used Popular Machine Learning Algorithms Every Engineer must know
Here is a simple infographic to help you with the best machine learning algorithms examples frequently used by engineers in the artificial intelligence domain.

Different Machine Learning Algorithms for Beginners
Before jumping into the pool of advanced machine learning algorithms, explore these predictive algorithms that will help you master machine learning skills.
Naive Bayes Classifier Algorithm
It would be difficult and practically impossible to manually classify a web page, document, email, or any other lengthy text notes. That is where the Naive Bayes Classifier comes to the rescue. A classifier is a function that allocates a population’s element value from one of the available categories. For instance, Spam Filtering and weather forecast are some popular applications of the Naive Bayes algorithm. The spam filter here is a classifier that assigns a label “Spam” or “Not Spam” to all the emails.
Naïve Bayes Classifier is amongst the most popular learning method grouped by similarities, which works on the famous Bayes Theorem of Probability- to build machine learning models, particularly for disease prediction and document classification. It is a simple classification of words based on the Bayes Probability Theorem for subjective content analysis. This classification method uses probabilities using the Bayes theorem. The basic assumption for the Naive Bayes algorithm is that all the features are considered to be independent of each other. It is a straightforward algorithm, and it is easy to implement. It is beneficial for large datasets and can be implemented for text datasets.
Bayes theorem gives a way to calculate posterior probability P(A|B) from P(A), P(B), and P(B|A).
The formula is given by: P(A|B) = P(B|A) * P(A) / P(B)
Where P(A|B) is the posterior probability of A given B, P(A) is the prior probability, P(B|A) is the likelihood which is the probability of B given A, and P(B) is the prior probability of B.
When to use the Naive Bayes Classifier algorithm?
-
Naive Bayes is best in cases with a moderate or large training dataset.
-
It works well for dataset instances that have several attributes.
-
Given the classification parameter, attributes that describe the instances should be conditionally independent.
Applications of Naive Bayes Classifier

-
Sentiment Analysis- It is used by Facebook to analyze status updates expressing positive or negative emotions.
-
Document Categorization- Google uses document classification to index documents and finds relevancy scores, i.e., the PageRank. PageRank mechanism considers the pages marked as important in the databases parsed and classified using a document classification technique.
-
This algorithm is also used for classifying news articles about Technology, Entertainment, Sports, Politics, etc.
-
Email Spam Filtering- Google Mail uses the Naive Bayes algorithm to classify your emails as Spam or Not Spam.
-
Data Science Libraries in Python to implement Naive Bayes – Sci-Kit Learn
Advantages of the Naive Bayes Classifier Algorithm
-
The Naive Bayes Classifier algorithm performs well when the input variables are categorical.
-
A Naïve Bayes classifier converges faster, requiring relatively little training data set than other discriminative models like logistic regression when the Naïve Bayes conditional independence assumption holds.
-
With the Naive Bayes Classifier algorithm, predicting the class of the testing data set is more effortless. A good bet for multi-class predictions as well.
-
Though it requires conditional independence assumption, Naïve Bayes Classifier has performed well in various application domains.
K Means Clustering Algorithm
K-means is a popularly used unsupervised ML algorithm for cluster analysis. K-Means is a non-deterministic and iterative method. The algorithm operates on a given data set through a pre-defined number of clusters, k. The output of the K Means algorithm is k clusters with input data partitioned among the clusters. For instance, let’s consider K-Means Clustering for Wikipedia Search results. The search term “Jaguar” on Wikipedia will return all pages containing the word Jaguar which can refer to Jaguar as a Car, Jaguar as Mac OS version, and Jaguar as an Animal. K Means clustering algorithm can be applied to group the web pages that talk about similar concepts. So, the algorithm will group all the web pages that refer to Jaguar as an Animal into one cluster, Jaguar as a Car into another cluster, and so on.
For any new incoming data point, the data point is classified according to its proximity to the nearby classes. Datapoints inside a cluster will exhibit similar characteristics while the other clusters will have different properties. The primary example of clustering would be grouping the same customers in a particular class for any marketing campaign, and it is also a practical algorithm for document clustering.
The steps followed in the k means algorithm are as follows -
-
Specify the number of clusters as k
-
Randomly select k data points and assign them to the clusters
-
Cluster centroids will be calculated subsequently
-
Keep iterating from 1-3 steps until you find the optimal centroid, after which values won’t change.
i) The sum of the squared distance between the centroid and the data point is computed.
ii) Assign each data point to the cluster that is closer to the other cluster
iii) Compute the centroid for the cluster by taking the average of all the data points in the cluster
We can find the optimal number of clusters k by plotting the value of the sum squared distance which decreases gradually to reach an optimal number of k.
Advantages of using K-Means Clustering
-
In the case of globular clusters, K-Means produce tighter clusters than hierarchical clustering.
-
Given a smaller value of K, K-Means clustering computes faster than hierarchical clustering for many variables.
Applications of K-Means Clustering
Most search engines like Yahoo and Google use the K Means Clustering algorithm to cluster web pages by similarity and identify the ‘relevance rate’ of search results. This helps search engines reduce the computational time for the users.
Data Science Libraries in Python to implement K-Means Clustering – SciPy, Sci-Kit Learn, Python Wrapper
Data Science Libraries in R to implement K-Means Clustering – stats.
Support Vector Machines
Support Vector Machine is a supervised learning algorithm for classification or regression problems where the dataset teaches SVM about the classes so that SVM can classify any new data. It organizes the data into different categories by finding a line (hyperplane) separating the training data set into classes. As there are many such linear hyperplanes, the SVM algorithm tries to maximize the distance between the various classes involved, referred to as margin maximization. If the line that maximizes the distance between the classes is identified, the probability of generalizing well to unseen data is increased.
SVMs are classified into two categories
-
Linear SVMs – In linear SVMs, the training data i.e. classifiers, are separated by a hyperplane.
-
Non-Linear SVMs- In non-linear SVMs, it is impossible to separate the training data using a hyperplane. For example, the training data for Face detection consists of a group of images that are faces and another group of images that do not face (in other words, all other images in the world except faces). Under such conditions, the training data is too complex that it is impossible to find a representation for every feature vector. Separating the set of faces linearly from the set of non-face is a complicated task.
Advantages of Using SVM
-
SVM offers the best classification performance (accuracy) on the training dataset.
-
SVM renders more efficiency for the correct classification of future data.
-
The best thing about SVM is that it does not make strong assumptions about data.
-
It does not overfit the data.
Applications of Support Vector Machine
SVM is commonly used for stock market forecasting by various financial institutions. For instance, one can use it to compare the relative performance of the stocks to those of other stocks in the same sector. The close comparison of stocks helps manage investment-making decisions based on the classifications made by the SVM learning algorithm.
Explore Enterpirse-Grade Data Science Projects for Resume Building and Ace your Next Job Interview!
Apriori Algorithm
Apriori algorithm is an unsupervised ML algorithm that generates association rules from a given data set. The Association rule implies that if item A occurs, then item B also occurs with a certain probability. Most of the association rules generated are in the IF_THEN format. For example, IF people buy an iPad, they also buy an iPad Case to protect it. For the algorithm to derive such conclusions, it first observes the number of people who bought an iPad case while purchasing an iPad. This way a ratio is derived like out of the 100 people who purchased an iPad, 85 people also purchased an iPad case.
Principle on which Apriori Algorithm works
-
If an item set frequently occurs, then all the subsets of the item set also happen often.
-
If an item set occurs infrequently, then all the supersets of the item set have infrequent occurrences.
Advantages of Apriori Algorithm
-
It is easy to implement and can be parallelized easily.
-
Apriori implementation makes use of large item set properties.
Applications of Apriori Algorithm

-
Detecting Adverse Drug Reactions - Apriori algorithm is used for association analysis on healthcare data like the drugs taken by patients, characteristics of each patient, adverse ill-effects patients experience, initial diagnosis, etc. This analysis produces association rules that help identify the combination of patient characteristics and medications that lead to adverse side effects of the drugs
-
Market Basket Analysis - Many e-commerce giants like Amazon use Apriori to draw data on which products are likely to be purchased together and which are most responsive to promotion. For example, a retailer might use Apriori to predict that people who buy sugar and flour will likely buy eggs to bake a cake
-
Auto-Complete Applications - Google auto-complete is another popular application of Apriori wherein - when the user types a word, the search engine looks for other associated words that people usually type after a specific word.

Data Science Libraries in Python to implement Apriori Algorithm – There is a python implementation for Apriori in PyPi
Data Science Libraries in R to implement Apriori Algorithm – arules
Linear Regression
The linear Regression model shows the relationship between 2 variables and how the change in one variable impacts the other. The algorithm shows the impact of the dependent variable on changing the independent variable. The independent variables are referred to as explanatory variables, which explain the factors that impact the dependent variable. The dependent variable is often referred to as the factor of interest or predictor. The linear regression model is used for estimating fundamental continuous values. The most common linear regression examples are housing price predictions, sales predictions, weather predictions, employee salary estimations, etc. The primary goal for linear regression is to fit the best line amongst the predictions. The equation for simple linear regression is Y=a*x+b, where y is the dependent variable, x is the set of independent variables, a is the slope, and b is the intercept.
The best example from human lives would be how a child would solve a simple problem like - ordering the children in class height orderwise without asking the children's heights. The child will be able to solve this problem by visually looking at the heights of the children and subsequently arranging them height-wise. That is how you can perceive linear regression in a real-life scenario. The weights, which are the heights and the build of the children, have been learned by the child gradually. Looking back at the equation, a and b are the coefficients learned through the regression model by minimizing the sum of squared errors in the model values.
The graph below shows the relation between the number of umbrellas sold and the rainfall in a particular region -

Advantages of Linear Regression
-
It is one of the most interpretable machine learning algorithms, making it easy to explain to others.
-
It is easy to use as it requires minimal tuning.
-
It is the most widely used machine learning technique that runs fast.
Applications of Linear Regression
-
Estimating Sales
Linear Regression finds excellent use in business for sales forecasting based on trends. If a company observes a steady increase in sales every month - linear regression analysis of the monthly sales data helps the company forecast sales in upcoming months. -
Risk Assessment
Linear Regression helps assess the risk involved in the insurance or financial domain. A health insurance company can do a linear regression analysis on the number of claims per customer against age. This analysis helps insurance companies find that older customers tend to make more insurance claims. Such analysis results play a vital role in critical business decisions and are made to account for risk.
Data Science Libraries in Python to implement Linear Regression – stats model and SciKit
Data Science Libraries in R to implement Linear Regression – stats
Explanations about the top machine learning algorithms will continue, as it is a work in progress. Stay tuned to our blog to learn more about the popular machine learning algorithms and their applications!!!
Logistic Regression
The name of this algorithm could be a little confusing in the sense that this algorithm is used to estimate discrete values in classification tasks and not regression problems. The name ‘Regression’ here implies that a linear model is fit into the feature space. This algorithm applies a logistic function to a linear combination of features to predict the outcome of a categorical dependent variable based on predictor variables. The odds or probabilities that describe the result of a single trial are modeled as a function of explanatory variables. This algorithm helps estimate the likelihood of falling into a specific level of the categorical dependent variable based on the given predictor variables.

Suppose you want to predict if there will be a snowfall tomorrow in New York. Here the prediction outcome is not a continuous number because there will either be snowfall or no snowfall, so simple linear regression cannot be applied. Here the outcome variable is one of the several categories, and logistic regression helps.
Types of Logistic Regression
-
Binary Logistic Regression - The most commonly used logistic regression is when the categorical response has two possible outcomes, i.e., yes or not. Example –Predict whether a student will pass or fail an exam, whether a student will have low or high blood pressure, and whether a tumor is cancerous.
-
Multi-nominal Logistic Regression - Categorical response has three or more possible outcomes with no order. Example- Predicting what kind of search engine (Yahoo, Bing, Google, and MSN) is used by majority of US citizens.
-
Ordinal Logistic Regression - Categorical response has 3 or more possible outcomes with natural ordering. Example- How a customer rates the service and quality of food at a restaurant based on a scale of 1 to 10.
Let us consider a simple example where a cake manufacturer wants to find out if baking a cake at 160°C, 180°C and 200°C will produce a ‘hard’ or ‘soft’ variety of cake ( assuming the fact that the bakery sells both the varieties of cake with different names and prices). Logistic regression is a perfect fit in this scenario instead of other statistical techniques. For example, if the manufacturers produce 2 cake batches wherein the first batch contains 20 cakes (of which 7 were hard and 13 were soft ) and the second batch of cake produced consisted of 80 cakes (of which 41 were hard and 39 were soft cakes). Here in this case if a linear regression algorithm is used it will give equal importance to both the batches of cakes regardless of the number of cakes in each batch. Applying a logistic regression algorithm will consider this factor and give the second batch of cakes more weightage than the first batch.
When to Use Logistic Regression
-
Use logistic regression algorithms when there is a requirement to model the probabilities of the response variable as a function of some other explanatory variable. For example, the probability of buying a product X as a function of gender
-
Use logistic regression algorithms when there is a need to predict probabilities that categorical dependent variables will fall into two categories of the binary response as a function of some explanatory variables. For example, what is the probability that a customer will buy a perfume given that the customer is a female?
-
Logistic regression algorithms is also best suited when the need is to classify elements into two categories based on the explanatory variable. For example-classify females into ‘young’ or ‘old’ group based on their age.
Advantages of Using Logistic Regression
-
Easier to inspect and less complex.
-
Robust algorithm as the independent variables need not have equal variance or normal distribution.
-
These algorithms do not assume a linear relationship between the dependent and independent variables and hence can also handle non-linear effects.
-
Controls confounding and tests interaction.
-
It is one the best machine learning approaches for solving binary classification problems.
Drawbacks of Using Logistic Regression
-
When the training dataset is sparse and high dimensional, in such situations a logistic model may overfit the training dataset.
-
This algorithm cannot predict continuous outcomes. For instance, it cannot be applied when the goal is to determine how heavily it will rain because the scale of measuring rainfall is continuous. Data scientists can predict heavy or low rainfall but this would make some compromises with the precision of the dataset.
-
This algorithm requires more data to achieve stability and meaningful results. These algorithms require a minimum of 50 data points per predictor to achieve stable outcomes.
-
It predicts outcomes depending on a group of independent variables and if a data scientist or a machine learning expert goes wrong in identifying the independent variables then the developed model will have minimal or no predictive value.
-
It is not robust to outliers and missing values.
Applications of Logistic Regression
-
This algorithm is applied in the field of epidemiology to identify risk factors for diseases and plan accordingly for preventive measures.
-
It is used to predict whether a candidate will win or lose a political election or whether a voter will vote for a particular candidate.
-
It is used to classify a set of words as nouns, pronouns, verbs, adjectives.
-
It is used in weather forecasting to predict the probability of rain.
-
It is used in credit scoring systems for risk management to predict the defaulting of an account.
The Data Science libraries in Python language to implement Logistic Regression Algorithm is Sci-Kit Learn.
The Data Science libraries in R language to implement Logistic Regression Algorithm is stats package (glm () function)
Decision Tree

You are making a weekend plan to visit the best restaurant in town as your parents are visiting but you are hesitant in making a decision on which restaurant to choose. Whenever you want to visit a restaurant you ask your friend Tyrion if he thinks you will like a particular place. To answer your question, Tyrion first has to find out the kind of restaurants you like. You give him a list of restaurants that you have visited and tell him whether you liked each restaurant or not (giving a labeled training dataset). When you ask Tyrion that whether you will like a particular restaurant R or not, he asks you various questions like “Is “R” a rooftop restaurant?” , “Does restaurant “R'' serve Italian cuisine?”, “Does R have live music?”, “Is restaurant R open till midnight?” and so on. Tyrion asks you several informative questions to maximize the information gain and gives you YES or NO answer based on your answers to the questionnaire. Here Tyrion is a decision tree for your favourite restaurant preferences.
A decision tree is a graphical representation that makes use of branching methodology to exemplify all possible outcomes of a decision, based on certain conditions. In a decision tree, the internal node represents a test on the attribute, each branch of the tree represents the outcome of the test and the leaf node represents a particular class label i.e. the decision made after computing all of the attributes. The classification rules are represented through the path from root to the leaf node.
Types of Decision Trees
Classification Trees- These are considered as the default kind of decision trees used to separate a dataset into different classes, based on the response variable. These are one of the highly sophisticated classification methods for cases where the response variable is categorical in nature.
Regression Trees-When the response or target variable is continuous or numerical, regression trees are used.
Decision trees can also be classified into two types, based on the type of target variable- Continuous Variable Decision Trees and Binary Variable Decision Trees. It is the target variable that helps decide what kind of decision tree would be required for a particular problem.

Why should you use the Decision Tree algorithm?
-
These machine learning algorithms help make decisions under uncertainty and help you improve communication, as they present a visual representation of a decision situation.
-
Decision tree helps a data scientist capture the idea that if a different decision was taken, then how the operational nature of a situation or model would have changed intensely.
-
Decision tree algorithms help make optimal decisions by allowing a data scientist to traverse through forward and backward calculation paths.
When to use Decision Tree
-
Decision trees are robust to errors and if, the training dataset contains errors- decision tree algorithms will be best suited to address such problems.
-
They are best suited for problems where instances are represented by attribute value pairs.
-
If the training dataset has missing value then decision trees can be used, as they can handle missing values nicely by looking at the data in other columns.
-
They are best suited when the target function has discrete output values.
Advantages of Using Decision Tree
-
Decision trees are very instinctual and can be explained to anyone with ease. People from a non-technical background can also decipher the hypothesis drawn from a decision tree, as they are self-explanatory.
-
When using this algorithm, data type is not a constraint as they can handle both categorical and numerical variables.
-
Decision tree machine learning algorithms do not require making any assumption on the linearity in the data and hence can be used in circumstances where the parameters are non-linearly related. These machine learning algorithms do not make any assumptions on the classifier structure and space distribution.
-
These algorithms are useful in data exploration. Decision trees implicitly perform feature selection which is very important in predictive analytics. When a decision tree is fit to a training dataset, the nodes at the top on which the tree is split, are considered as important variables within a given dataset and feature selection is completed by default.
-
Decision trees help save data preparation time, as they are not sensitive to missing values and outliers. Missing values will not stop you from splitting the data for building a decision tree. Outliers will also not affect the decision trees as data splitting happens based on some samples within the split range and not on exact absolute values.
Drawbacks of Using Decision Tree
-
The more the number of decisions in a tree, less is the accuracy of any expected outcome.
-
A major drawback of this machine learning algorithm is that the outcomes may be based on expectations. When decisions are made in real-time, the payoffs and resulting outcomes might not be the same as expected or planned. There are chances that this could lead to unrealistic decision trees leading to bad decision making. Any irrational expectations could lead to major errors and flaws in decision tree analysis, as it is not always possible to plan for all eventualities that can arise from a decision.
-
Decision Trees do not fit well for continuous variables and result in instability and classification plateaus.
-
Decision trees are easy to use when compared to other decision making models but creating large decision trees that contain several branches is a complex and time consuming task.
-
Decision tree considers only one attribute at a time and might not be best suited for actual data in the decision space.
-
Large sized decision trees with multiple branches are not comprehensible and pose several presentation difficulties.
Applications of Decision Tree
-
Decision trees are among the popular machine learning algorithms that find great use in finance for option pricing.
-
Remote sensing is an application area for pattern recognition based on decision trees.
-
Decision tree algorithms are used by banks to classify loan applicants by their probability of defaulting payments.
-
Gerber Products, a popular baby product company, used decision tree algorithm to decide whether they should continue using the plastic PVC (Poly Vinyl Chloride) in their products.
-
Rush University Medical Centre has developed a tool named Guardian that uses a decision tree algorithm to identify at-risk patients and disease trends.
The Data Science libraries in Python language to implement Decision Tree are – SciPy and Sci-Kit Learn.
The Data Science libraries in R language to implement Decision Tree is caret.

Random Forest
Let’s continue with the same example we used in decision trees, to explain how Random Forest Algorithm works. Tyrion is a decision tree for your restaurant preferences. However, Tyrion being a human being does not always generalize your restaurant preferences with accuracy. To get more accurate restaurant recommendation, you ask a couple of your friends and decide to visit the restaurant R, if most of them say that you will like it. Instead of just asking Tyrion, you would like to ask Jon Snow, Sandor, Bronn and Bran who vote on whether you will like the restaurant R or not. This implies that you have built an ensemble classifier of decision trees - also known as a forest.
You don’t want all your friends to give you the same answer - so you provide each of your friends with slightly varying data. You are also not sure of your restaurant preferences and are in a dilemma.You told Tyrion that you like Open RoofTop restaurants but maybe, just because it was summer when you visited the restaurant you could have liked it then. You may not be a fan of the restaurant during the chilly winters. Thus, all your friends should not make use of the data point that you like open rooftop restaurants, to make their recommendations for your restaurant preferences.
By providing your friends with slightly different data on your restaurant preferences, you make your friends ask you different questions at different times. In this case just by slightly altering your restaurant preferences, you are injecting randomness at model level (unlike randomness at data level in case of decision trees). Your group of friends now form a random forest of your restaurant preferences.
Random Forest is the go to algorithm that uses a bagging approach to create a bunch of decision trees with random subset of the data. A model is trained several times on random sample of the dataset to achieve good prediction performance from the random forest algorithm.In this ensemble learning method, the output of all the decision trees in the random forest is combined to make the final prediction. The final prediction of the random forest algorithm is derived by polling the results of each decision tree or just by going with a prediction that appears the most times in the decision trees.
For instance, in the above example - if 5 friends decide that you will like restaurant R but only 2 friends decide that you will not like the restaurant then the final prediction is that, you will like restaurant R as majority always wins.
Why use Random Forest Algorithm?
-
There are many good open source, free implementations of the algorithm available in Python and R.
-
It maintains accuracy when there is missing data and is also resistant to outliers.
-
Simple to use as the basic random forest algorithm can be implemented with just a few lines of code.
-
Random Forest machine learning algorithms help data scientists save data preparation time, as they do not require any input preparation and can handle numerical, binary and categorical features, without scaling, transformation or modification.
-
Implicit feature selection as it gives estimates on what variables are important in the classification.
Advantages of Using Random Forest
-
Overfitting is less of an issue with Random Forests. Unlike decision tree machine learning algorithms, there is no need of pruning the random forest.
-
These algorithms are fast but not in all cases. A random forest algorithm, when run on an 800 MHz machine with a dataset of 100 variables and 50,000 cases produced 100 decision trees in 11 minutes.
-
Random Forest is one of the most influential and versatile algorithm for wide variety of classification and regression tasks, as they are more robust to noise.
-
It is difficult to build a bad random forest. In the implementation of Random Forest Machine Learning algorithms, it is easy to determine which parameters to use because they are not sensitive to the parameters that are used to run the algorithm. One can easily build a decent model without much tuning.
-
Random Forest machine learning algorithms can be grown in parallel.
-
This algorithm runs efficiently on large databases.
-
Has higher classification accuracy.
Drawbacks of Using Random Forest
-
They might be easy to use but analysing them theoretically, is difficult.
-
Large number of decision trees in the random forest can slow down the algorithm in making real-time predictions.
-
If the data consists of categorical variables with different number of levels, then the algorithm gets biased in favour of those attributes that have more levels. In such situations, variable importance scores do not seem to be reliable.
-
When using RandomForest algorithm for regression tasks, it does not predict beyond the range of the response values in the training data.
Applications of Random Forest
-
Random Forest algorithms are used by banks to predict if a loan applicant is a likely high risk.
-
They are used in the automobile industry to predict the failure or breakdown of a mechanical part.
-
These algorithms are used in the healthcare industry to predict if a patient is likely to develop a chronic disease or not.
-
They can also be used for regression tasks like predicting the average number of social media shares and performance scores.
-
Recently, the algorithm has also made way into predicting patterns in speech recognition software and classifying images and texts.
Data Science libraries in Python language to implement Random Forest is Sci-Kit Learn.
What makes Python one of the best programming languages for ML Projects? The answer lies in these solved and end-to-end Machine Learning Projects in Python. Check them out now!
Data Science libraries in R language to implement Random Forest is randomForest.

Artificial Neural Networks
The human brain has a highly complex and non-linear parallel computer that can organize the structural constituents i.e. the neurons interconnected in a complex manner between each other. Let us take a simple example of face recognition-whenever we meet a person, a person who is known to us can be easily recognized with his name or he works at XYZ place or based on his relationship with you. We may be knowing thousands of people, the task requires the human brain to immediately recognize the person (face recognition). Now, suppose instead of the human brain doing it, if a computer is asked to perform this task. It is not going to be an easy computation for the machine as it does not know the person. You have to teach the computer that there are images of different people. If you know 10,000 people then you have to feed all the 10,000 photographs into the computer. Now, whenever you meet a person you capture an image of the person and feed it to the computer. The computer matches this photograph with all the 10,000 photographs that you have already fed into the database. At the end of all the computations-it gives the result with the photograph that best resembles the person. This could take several hours or more depending on the number of images present in the database. The complexity of the task will increase with the increase in the number of images in the database. However, a human brain can recognize it instantly.
Can we recognize this instantly using a computer? Is it that the computation capability that exists in humans is different from that of computers? If you consider the processing speed of a silicon IC it is of the order of 10-9 (order of nanoseconds) whereas the processing speed of a human neuron is 6 times slower than typical IC’s i.e. 10-3 (order of milliseconds). In that case, there is a puzzling question: how is the processing time of the human brain faster than that of a computer. Typically, there are 10 billion neurons with approximately 60 trillion interconnections inside the human brain but still, it processes faster than the computer. That is because the network of neurons in the human brain is massively parallel.
Now the question is that is it possible to mimic the massively parallel nature of the human brain using computer software. It is not that easy as we cannot really think of putting so many processing units and realizing them in a massively parallel fashion. All that can be done within a limitation is interconnecting a network of processors. Instead of considering the structure of a human brain in totality, only a very small part of the human brain can be mimicked to do a very specific task. We can make neurons but they will be different from the biological neuron of the human brain. This can be achieved using Artificial Neural Networks (ANNs). By artificial we inherently mean something that is different from the biological neurons. ANNs are nothing but simulated brains that can be programmed the way we want. By defining rules to mimic the behavior of the human brain, data scientists can solve real-world problems that could have never been considered before.
How do Artificial Neural Network algorithms work?
It is a subfield of artificial intelligence which is modeled after the brain. It is a computational network consisting of neurons interconnected to each other. This interconnected structure is used for making various predictions for both regressions as well as classification problems. The ANN consists of various layers - the input layer, the hidden layer, and the output layers. The hidden layers could be more than 1 in number. The hidden layer is the place where all the mathematics of the neural network takes place. The basic formulas of weights and biases are added here, along with the application of the activation functions. These activation functions are responsible for delivering the output in a structured and trimmed manner. It is majorly used for solving non-linear problems - handwriting recognition, traveling salesman problems, etc. ANNs involves complex mathematical calculations and are highly compute-intensive in nature.
Imagine you are walking on a walkway and you see a pillar (assume that you have never seen a pillar before). You walk into the pillar and hit it. Now, the next time you see a pillar you stay a few meters away from the pillar and continue walking on the side. This time your shoulder hits the pillar and you are hurt again. Again when you see the pillar you ensure that you don’t hit it but this time on your path you hit a letter-box (assuming that you have never seen a letter-box before). You walk into it and the complete process repeats again. This is how an artificial neural network works, it is given several examples and it tries to get the same answer. Whenever it is wrong, an error is calculated. So, next time for a similar example the value at the synapse (weighted values through which neurons are connected in the network) and neuron is propagated backward i.e. back propagation takes place. Thus, an ANN requires lots of examples and learning and they can be in millions or billions for real-world applications.
Recommended Reading: Types of Neural Networks
Why use ANNs?
-
ANN’s have interconnection of non-linear neurons thus these machine learning algorithms can exploit non-linearity in a distributed manner.
-
They can adapt free parameters to the changes in the surrounding environment.
-
Learns from its mistakes and takes better decisions through backpropagation.
Advantages of Using ANNs
-
Easy to understand for professionals who do not want to dig deep into math-related complex machine learning algorithms. If you are trying to sell a model to an organization which would you rather say Artificial Neural Networks (ANN) or Support Vector Machine (SVM). We guess the answer obviously is going to be ANN because you can easily explain to them that they just work like the neurons in your brain.
-
They are easy to conceptualize.
-
They have the ability to identify all probable interactions between predictor variables.
-
They have the ability to subtly identify complex nonlinear relationships that exists between independent and dependent variables.
-
It is relatively easy to add prior knowledge to the model.
Disadvantages of Using ANNs
-
It is very difficult to reverse engineer ANN algorithms. If your ANN learns that the image of a dog is actually a cat then it is very difficult to determine “why”. All than can be done is continuously tweak or train the ANN further.
-
ANN algorithms are not probabilistic meaning if the output of the algorithm is a continuous number it is difficult to translate it into a probability.
-
They are not magic wands and cannot be applied to solve any kind of ML algorithm.
-
ANNs in native implementation are not highly effective at practical problem-solving. However, this can be improved with the use of deep learning techniques.
-
Multi-layered ANN algorithms are hard to train and require tuning a lot of parameters.
Applications of ANNs
ANNs are among the hottest machine learning algorithms in use today, solving classification problems to pattern recognition. They are extensively used in research and other application areas like –
-
Financial Institutions use ANNs machine learning algorithms to enhance their performance in evaluating loan applications, bond rating, target marketing, and credit scoring. They are also used to identify instances of fraud in credit card transactions.
-
Buzzfeed uses artificial neural network algorithms to organize and search videos or photos for image recognition.
-
Many bomb detectors at US airports use ANNs to analyze airborne trace elements and identify the presence of explosive chemicals.
-
Google uses ANNs for Speech Recognition, Image Recognition, and other pattern recognition (handwriting recognition) applications. ANNs are used at Google to sniff out spam and for many different applications.
-
ANNs find tremendous applications in robotic factories for adjusting temperature settings, controlling machinery, diagnose malfunctions.
Evolution of Machine Learning Applications in Finance : From Theory to Practice
K-Nearest Neighbors
KNN is the most straightforward classification algorithm. It is also used for the prediction of continuous values like regression. Distance-based measures are used in K Nearest Neighbors to get the correct prediction. The final prediction value is chosen based on the k neighbors. The various distance measures used are Euclidean, Manhattan, Minkowski, and Hamming distances. The first three are continuous functions, while Hamming distance is used for categorical variables. Choosing the value of K is the most essential task in this algorithm. It is often referred to as the lazy learner algorithm.

Image Credit: medium.com
As shown in the diagram above, the distances from the new point are calculated with each of the classes. Lesser the distance, the new point will be assigned to the class closer to the point.
Advantages of Using K-Nearest Neighbors
-
High accuracy but better algorithms exist.
-
It's very useful for non-linear data as there are no assumptions here.
Disadvantages of Using K-Nearest Neighbors
-
Computationally expensive requires high memory storage.
-
Sensitive to scaling of data.
Advanced Machine Learning Algorithms Examples
The blog will now discuss some of the most popular and slightly more technical algorithms with machine learning applications.
Gradient Boosting
Gradient Boosting Classifier uses the boosting methodology where the trees which are created follow the decision tree method with minor changes. The weak learners from every tree are subsequently given more weightage and given to the next tree in succession so that the predictions for the trees are improved versions from the previous ones. It uses the weighted average for calculating the final predictions. Boosting is used when we have a large amount of data with high predictions.
XgBoost
XgBoost is an advanced implementation of gradient boosting algorithms. It is different from gradient boosting in its calculations as it applies the regularization technique internally. Xgboost is referred to as a regularized boosting technique.
Pros
-
It is much faster than the gradient boosting mechanism.
-
XGBoost allows users to define custom optimization objectives and evaluation criteria.
-
XgBoost has techniques to handle missing values
Cons
-
Difficult interpretation
-
Overfitting is possible
-
Harder to tune
CatBoost
CatBoost is an open-source gradient boosting library used to train large amounts of data using ML. It supports the direct usage of categorical variables. It gives a very high performance in comparison to the other boosting algorithms. It is straightforward to implement and run. It is a model developed by Yandex. It provides support for out-of-the-box descriptive data formats and does not require much training. It gives a good performance with a lesser number of training iterations.
Light GBM
LightGBM is a gradient boosting framework that uses a decision tree algorithm. As the name suggests, its training speed is very fast and can be used for training large datasets.
Pros
-
Faster training speed and accuracy
-
Lower memory usage
-
Parallel GPU support
-
Higher efficiency and performance
Cons
-
Narrow user base
Linear Discriminant Analysis
Linear Discriminant Analysis or LDA is an algorithm that provides an indirect approach to solve a classification machine learning problem. To predict the probability, Pn(X) that a given feature, X belongs to a given class Yn or not, it assumes a density function of all the features that belong to that class. It then uses this density function, fn(X) to predict the probability Pn(X) using
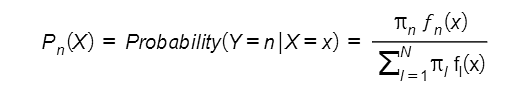
where πn is the overall or prior probability that a randomly picked observation belongs to nth class.
Let the dataset have only feature variable, then the LDA assumes a Gaussian distribution function for fn(X) having a class-specific mean vector (ðÂœ‡n) and a covariance matrix that is applicable for all N classes. After that to assign a class to an observation from the testing data set, it evaluates the discriminant function

The LDA classifier then predicts the class of the test variable for which the value of the discriminant function is the largest. We call this algorithm as “linear” discriminant analysis because, in the discriminant function, the component functions are all linear functions of x.
Note: In the case of more than one variable, LDA assumes a multivariate gaussian function and the discriminant function is scaled accordingly.
Advantages of Linear Discriminant Analysis
1. It works well for machine learning problems where the classes to be assigned are well-separated.
2. The LDA provides stable results if the number of feature variables in the given dataset is small and fits the normal distribution well.
3. It is easy to understand and simple to use.
Disadvantages of Linear Discriminant Analysis
1. It requires the feature variables to follow the Gaussian distribution and thus has limited applications.
2. It does not perform very well on datasets having a small number of target variables.
Applications of Linear Discriminant Analysis
Classifying the Iris Flowers: The famous Iris Dataset contains four features (sepal length, petal length, sepal width, petal width) of three types of Iris flowers. You can use LDA to classify these flowers based on the given four features.
Quadratic Discriminant Analysis
This algorithm is similar to the LDA algorithm that we discussed above. Similar to LDA, the QDA algorithm assumes that feature variables belonging to a particular class obey the gaussian distribution function and utilizes Bayes’ theorem for predicting the covariance matrix.
However, in contrast to LDA, QDA presumes that each class in the target variables has its covariance matrix. And, if one implements this assumption to evaluate the word linear is replaced by quadratic. Learn how to implement this algorithm.
Advantages of Quadratic Discriminant Analysis
1. It performs well for machine learning problems where the size of the training set is large.
2. QDA advises for machine learning problems where the feature variables in the given dataset clearly don’t seem to have a common covariance matrix for N classes.
3. It helps in deducing the quadratic decision boundary.
4. It servers as a good compromise between the KNN, LDA, and Logistic regression machine learning algorithms.
5. It gives better results when there is non-linearity in the feature variables.
Disadvantages of Quadratic Discriminant Analysis
1. The results are greatly affected if the feature variables do not obey the gaussian distribution function.
2. It performs very well on datasets having feature variables that are uncorrelated.
Applications of Quadratic Discriminant Analysis
Classification of Wine: Yes, one can use the QDA algorithm to learn how to classify wine with Python’s sklearn library. Check out our free recipe: How to classify wine using sklearn LDA and QDA model? know more.
Perform QDA on Iris Dataset: You can use the Iris Dataset to understand the LDA algorithm and the QDA algorithm. To explore how to do that in detail, check How does Quadratic Discriminant Analysis work?
Principal Component Analysis
Principal components are the selected feature variables in a large dataset that allow the presentation of almost all the essential information through a smaller number of feature variables.
And principal component analysis (PCA) is the method by which these principal components are evaluated and used to understand the data better. It is an unsupervised algorithm and thus doesn’t require the input data to have target values. Here is a complete PCA (Principal Component Analysis) Machine Learning Tutorial that you can go through if you want to learn how to implement PCA to solve machine learning problems.
Advantages of Principal Component Analysis
-
It can be used for visualizing the dataset and can thus be implemented while performing Exploratory Data Analysis.
-
It is an excellent unsupervised learning method when working with large datasets as it removes correlated feature variables.
-
It assists in saving on computation power.
-
It is one of the commonly used dimensionality reduction algorithms.
-
It reduces the chances of overfitting a dataset.
-
It is also used for factor analysis in statistical learning.
Disadvantages of Principal Component Analysis
1. PCA requires users to normalize their feature variables before implementing them to solve data science problems.
2. As only a subset of feature variables is selected to understand the dataset, the information obtained will likely be incomplete.
Applications of Principal Component Analysis
Below, we have listed two easy applications of PCA for you to practice.
Perform PCA on Digits Dataset: Python’s sklearn library has an inbuilt dataset, ‘digits’, that you can use to understand the implementation of the PCA. Check out our free recipe: How to reduce dimensionality using PCA in Python? to know more.
Apply PCA on Breast Cancer Dataset: Python’s sklearn library has another breast cancer dataset. Check out our free recipe: How to extract features using PCA in Python? To learn how to implement PCA on the breast cancer dataset.
General Additive Models (GAMs)
GAMs is a more polished and flexible version of the multiple linear regression machine learning model. That is because they support using non-linear functions of each feature variable and still reflect additivity.
For regression problems, GAMs include the use of formulae like the one given below for predicting target variable, y given the feature variable (xi) :
yi = êžµ0 + f1|(xi1) + f2(xi2) + f3(xi3) + …+ fp(xip) + ðÂœ–i
Where ðÂœ–i represents the error terms. GAMs are additive as separate functions are evaluated for each feature variable and are then added together. For classification problems, GAMs extend logistic regression to evaluate the probability,
p(x) of whether a given feature variable (xi) is an instance of a class (yi) or not.The formula is given by,
log(p(x) / (1-p(x)) = êžµ0 + f1(x1) + f2(x2) + f3(x3) + …+ fp(xip) + ðÂœ–i
Advantages of General Additive Models
1. GAMs can be used for both classification and regression problems.
2. They allow modeling of non-linear relationships easily as they require users to manually carry out different transformations on each variable individually manually.
3. Non-linear predictions made using GAMs are relatively accurate.
4. Individual transformations on each feature variable lead to insightful conclusions about each variable in the dataset.
5. They are a practical compromise between linear and fully nonparametric models.
Disadvantages of General Additive Models
1. The model is restricted to be additive and does not support complex interactions among feature variables.
Applications of General Additive Models
You can use the pyGAM library in Python to explore GAMs.
Polynomial Regression
This algorithm is an extension of the linear regression machine learning model. Instead of assuming a linear relation between feature variables (xi) and the target variable (yi), it uses a polynomial expression to describe the relationship. The polynomial term used is given by

where ðÂœ–i represents the error term and d is the polynomial degree. If one uses a large value for d, this algorithm supports estimating non-linear relationships between the feature and target variables.
Advantages of Polynomial Regression
1. It offers a simple method to fit non-linear data.
2. It is easy to implement and is not computationally expensive
3. It can fit a varied range of curvatures.
4. It makes the pattern in the dataset more interpretable.
Disadvantages of Polynomial Regression
1. Using higher values for the degree of the polynomial supports overly flexible predictions and overfitting.
2. It has a high sensitivity for outliers.
3. It is difficult to predict what degree of the polynomial should be chosen for fitting a given dataset.
Applications of Polynomial Regression
Use Polynomial Regression for Boston Dataset: Python’s sklearn library has the Boston Housing dataset with 13 feature variables and one target variable. One can use Polynomial regression to use the 13 variables to predict the median value of the price of the houses in Boston. If you are curious about how to realize this in Python, check How and when to use polynomial regression?
FAQs
What are the three types of Machine Learning?
The three types of machine learning are:
-
Unsupervised Machine Learning Algorithms
-
Supervised Machine Learning Algorithms
-
Reinforcement Learning
Which language is the best for machine learning?
Python is considered one of the best programming languages for machine learning as it contains many libraries for efficiently implementing various algorithms in machine learning.
What is the simplest machine learning algorithm?
The simplest machine learning algorithm is linear regression. It is a simple algorithm that spans different domains. For example, it is used in Physics to evaluate the spring constant of a spring using Hooke’s law.
What are algorithms in machine learning?
Algorithms in machine learning are the mathematical equations that help understand the relationship between a given set of feature variables and dependent variables. Using these equations, one can predict the value of the dependent variable.
Which algorithm is best for machine learning?
The best algorithms in machine learning are the algorithms that help you understand your data the best and draw efficient predictions from it.
What are the common machine learning algorithms?
The common machine learning algorithms are:
-
Random Forest
-
Decision trees
-
Neural networks
-
Logistic regression
-
Linear regression

About the Author

ProjectPro
ProjectPro is the only online platform designed to help professionals gain practical, hands-on experience in big data, data engineering, data science, and machine learning related technologies. Having over 270+ reusable project templates in data science and big data with step-by-step walkthroughs,