Neural Network Training Tutorial
Cost Functions
The cost function measures how far away a particular solution is from an optimal solution to the problem in hand. The goal of every machine learning model pertains to minimizing this very function, tuning the parameters and using the available functions in the solution space. In other words, a cost function, is a measure of “how good” a network did with respect to its training sample. As cost function is a function, it returns just a value of measure.
Feedforward Neural Network
A feedforward neural network is basically a multi-layer (of neurons) connected with each other. It takes an input, traverses through its hidden layer and finally reaches the output layer. Let 𝓪j(i) be the output of the jth neuron in the ith layer. In that sense, 𝓪j(1) is the jth neuron in the input layer. So, the subsequent layer’s inputs will be:
aij=σ(∑k(wijk⋅ai−1k)+bij)
Where:
σ is the activation function,
wijk is the weight from the kth neuron in the (i −1)th layer to the jth neuron in the ith layer,
bij is the bias of the jth neuron in the ith layer, and
aij represents the activation value of the jth neuron in the ith layer.
Sometimes, the input to the activation function, is written as zij
Bias
A bias value allows you to shift the activation function to the left or right. It plays the same role which a coefficient b plays in the following linear equation: y=ax+b. Essentially, it helps in shift the output of the activation function so as to fit the prediction with data better. In case sigmoid function is used as an activation function, bias is used to adjust the steepness of the curve.
Let’s go back to cost function. So the cost function of a neural network generally depends on weights, biases, inputs of the training samples and the desired output from the model. We will learn cost functions for both feedforward (classification) and regularized (logistic regression).

Regularized & feedforward cost function
In case of normal regularized or logistic regression, where we just have one output, the cost function is defined as:
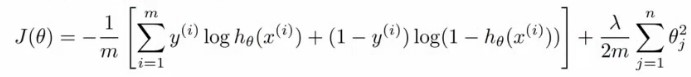
This cost function is derived from maximum likelihood estimation concept. 𝜭 is the parameter which we need to find such that J(𝜭) is minimized. The same is done using gradient descent. ( x i, y i) s are the inputs here.
For feedforward neural network, our cost function will be the generalization of this as it involves in multiple outputs, k, in the following function.
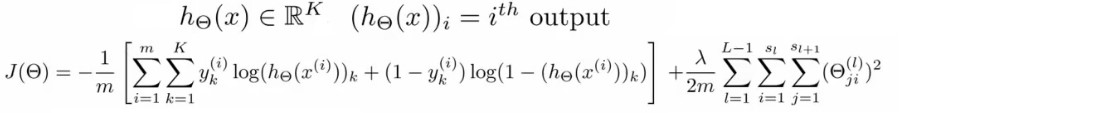
The first half of the sum is nothing but summation over the k output units that we had just one in case of logistic regression above. Because of multiple outputs, all the expressions are written in vectorised form now. The second half of the sum is a triple nested summation of the regularized term, also known as weight decay term. The ƛ here, adjusts the importance of the terms. We need to minimize this very cost function for the model to perform better. For the same, let’s discuss back-propagation algorithm.
Back propagation Learning
Back propagation basically compares the real value with the output of the network and checks the efficiency of the parameters. It “back-propagates” to the previous layers and calculates the error associated with each unit present in them, till it reaches the input layer, where there is no error. The errors measured at each unit is used to calculate partial derivatives which in turn is used by the gradient descent algorithm to minimize the cost function. Gradient descent uses these values to minimize and adjust the 𝜭 values till it converges.
Let 𝛅jl be the error for node j in layer l and ajl be the totally calculated activation value.
Then for any layer l, the error, 𝛅jl will be: 𝛅jl = ajl - yj
Where, yj is the actual value observed in the training sample. In terms of vector, the same can be re-written as: 𝛅l = al - y and so on..
So, for example, we have 𝛅4 calculated, then according to backpropagation algorithm, the error in previous layers can be calculated as:
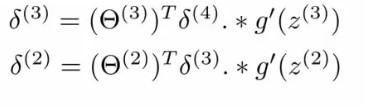
Where,
𝜭(i) is the vector of parameters for layer i to i+1,
𝛅4 is the error vector,
g is the activation function chosen, for simplicity, we will stick to sigmoid function in this case.
Z i are nothing but the product of activation values and parameter values of the previous layer, i-1
Here comes the stage, when we will see as to why choosing sigmoid function as activation function makes sense as its partial derivative calculation is simple. It can be proven that:
g’(z3)=a3.*(1-a3)
( .* is the element wise multiplication between the two vectors)
Following this procedure, we get all the 𝛅 values for our calculation. Now, straightforward, we can write:
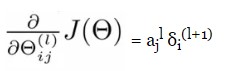
Quick Note: To find the activation values, we actually need to perform forward propagation.

Random Weights Initialization
First of all, let us see why we need random numbers as initial weights and why we shouldn’t use 0’s in place of them. It is anything but difficult to see instating weights with zero would for all intents and purposes "deactivate" the weights since weights by output of parent layer will be zero, subsequently, in the next learning steps, our information would not be perceived, the information would be neglected completely. So the learning would just have the information supplied by the bias in the input layer. What we should do to initialize these weights is, choose a decimal between 0 and 1 randomly and then scale it with a constant factor.
- Training Methods
Once the structure of a network is decided and weights are initialized randomly, we train the network next. There are many methods of training a neural network. Often, “training” is substituted as “learning”, but they are the same in essence. Training is the process by which our model learns on the already available data with results to align itself to predict on fresh data. Neural Networks have been a great area of research and a lot have been done and a lot is being done. Researchers have developed multiple techniques of training neural networks.
Essentially, there are two buckets in which these techniques are divided. Supervised and Unsupervised. As the name suggests, the former deals with those techniques in which there is some manual intervention or “supervision” in training the network or the model, and in the latter, the network has to learn itself. In other words, Supervised training involves a system of providing the expected output manually and evaluating the network’s performance or of simply providing the network with inputs and outputs. Let’s look at these techniques in detail.
Get Closer To Your Dream of Becoming a Data Scientist with 70+ Solved End-to-End ML Projects
- Supervised learning
As discussed, here, both inputs and outputs are provided to the network. The network then processes the inputs and matches the desired output with the computed outputs. The error in the output is then “back-propagated” in the system to adjust the weights and biases. The same set of “training data” is fed into the network again and again and the weights are refined and improved.
There is always a case when this technique won’t work. Even after refining the weights again and again do not give us the optimized solution. In that case, the modeller has to review the network architecture, the initial weights, the training functions, the number of layers and the number of nodes in them, etc. This is where, the ‘art’ of building a neural network comes into picture, which the reader can learn with experience. One more aspect of supervised training of neural network is that the modeller should not over train the model. On overtraining, the network starts ‘learning’ the data and tends to over fit.
Once the weights are trained and optimized, we are ready with our neural network model and can be put to use now. For industrial purposes, these coordinates are then frozen and turned into some user interface or hardware to be put to consumption and faster usage.
- Unsupervised learning
Unsupervised learning is also known as ‘adaptive’ learning or ‘self-organization’ sometimes as the network ‘adapts’ itself without any human intervention. Only inputs are provided to the network in this technique. The system itself decides what features to use to group the inputs.
For example, Robots are trained through unsupervised learning techniques. Unsupervised learning techniques are the ones which are making it possible for the robots to persistently learn all alone as they experience new circumstances and new situations.
Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization
Regression involving single or multiple Gaussian targets
Linear Regression is the simplest form of regression. We need to model our network to compute the linear combination of the inputs keeping weights and biases in context to get an output. The output is then compared with the desired output to get the error. Normally, the principal of least squares is used to calculate the error in regression. The challenge in this task is finding the most optimized weights that fits well in our data.
Quick fact: The simplest neural network actually performs least squares regression.
- How to train our network for this?
The network takes an input with one or multiple features, takes the product with corresponding weights and give its sum as the output.
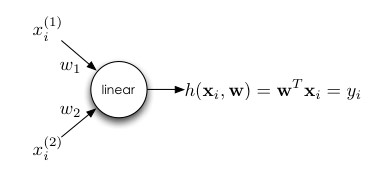
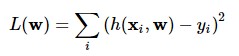
Here,
𝑥is are the features of an input,
𝔀is are the corresponding weights,
𝒉 is the activation function,
𝓨i is the output, and
L is the loss function calculated by the principle of least squares of the network’s calculated outputs on the entire training data.
Gradient descent is used to minimize this very loss function which refines and optimizes our system. For a particular weight corresponding to one connection, we find the gradient of the loss.
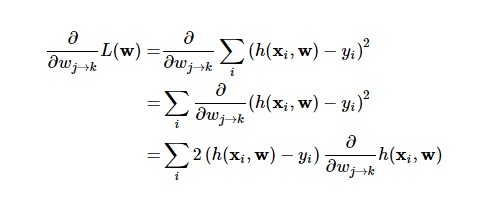
Learn Data Science by working on interesting Data Science Projects
Since the example at hand is simple enough, the gradient for the weights are simply the corresponding input features. So, the gradient is:
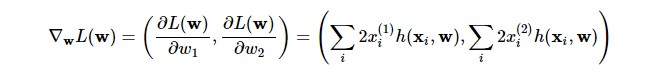
Thus, the weights are updated likewise. Now that we have seen this case of 1 layer neural network, this can be extended and generalized for multi-layer neural network. The reader is advised to try it out themselves.

XOR Logic function using using a 3 layered Neural Network
Boolean functions of two inputs are amongst the least complex of all functions, and the development of basic neural networks that figure out how to learn such functions is one of the main subjects talked about in records of neural processing. Of these functions, as it were two represent any trouble: these are XOR and its complement. A lot of problems in circuit design were solved with the advent of the XOR gate. XOR can be viewed as addition modulo 2. As a result, XOR gates are used to implement binary addition in computers. A half adder consists of an XOR gate and an AND gate. Other uses include subtractors, comparators, and controlled inverters.
Let’s understand XOR logic function to start with. XOR is also known as ‘exclusive OR’. In simple words, either A or B but not both. This function takes two input arguments with values in {-1,1} and returns one output in {-1,1}, as specified in the following truth table:
|
A |
B |
A XOR B |
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |
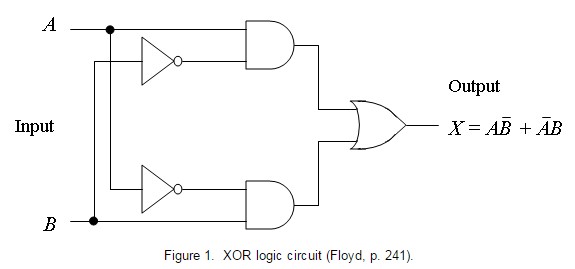
The task at hand is, we need to implement this very function using neural networks. Basically, it should take the inputs, A and B, in our context and output A XOR B, accordingly.
Explore More Data Science and Machine Learning Projects for Practice. Fast-Track Your Career Transition with ProjectPro
Whatever solution we will have to give should be efficient. We will try to implement this using 3 layers of neural network. One input, one hidden and one output. One of the most interesting features of neural network to recall now, is that the tweaking of the inputs is learned during the training process. Yes, we are talking about weights here. Once random weights are initialized, all other manipulations are done taking the performance on the training inputs into account. What, essentially, we have to create here is a network which takes input and gives an output. In case the output is not the desired one, we back-propagate the signal that there is an error. This should adjust the architecture to minimize the error. Let’s understand this further.
First, we should initialize weights other than in {-1,1}, reset the threshold of each node and initialize a bias. Just to recall, bias is a quantity that we add to the total input to calculate the activation at each node. Also, a node in a neural network becomes ‘active’ when the activation crosses a certain threshold. Now that we have reset the threshold, activation function must be chosen wisely.
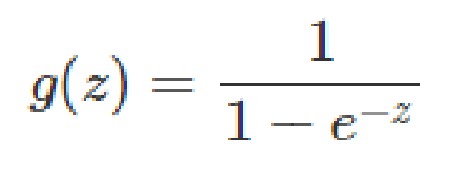
The activation function that we chose is “1 over 1 minus e raised to the power of negative net input”. Here, net input is sum of the products of inputs from the input layer and the corresponding weights of the connection. The next step is to train our neural network using the entries in the truth table.

The nodes in the hidden layer acts like a two-layer Perceptron. This is also called a 2-2-1 fully connected topology. In simple language, this is what we have to do:
- Initialize the network with random weights and biases.
- Apply the inputs x1 and x2 from the truth table and run the network.
- Compare the output of the network with the desired output mentioned in the truth table and calculate the error.
- Adjust the weights of the connections to the output nodes and biases. This is done by recursively computing the local gradient of each weight.
- The error is then back-propagated to the hidden layer and adjustment is done in the weights and biases corresponding to this particular layer.
This cycle repeats till the average error across the 4 entries in the truth table approaches zero. The activation function chosen is such that it can never reach 0 or 1, because of the presence of exponential e in the denominator. So, a workaround can be made as the activated value, if it is less than 0.1, we approximate it as 0 and if it is more than 0.9, we approximate it as 1.
The networks stops when a local minimum is reached. In the event that the system is by all accounts stuck, it has hit what is known as a 'local minima'. The bias of the hidden node will in the end head towards zero. As it approaches zero, the system will move on from the local minimum and will finish. This is a result of an 'momentum turn' that is used as a part of the estimation of the weights. We have seen, how beautifully back-propagation algorithm helps in implementing XOR logic function using neural nets. This can be further generalized for any logical function whose truth table is well defined. The reader should try and get their hands dirty on one other type of logic function and implement it using neural networks. But do remember, proposing an optimal solutions, i.e., the one which uses the minimum resources is always preferable.
The implementation of XOR logic functions using neural nets actually paved the way to the popularity of multi-layer perceptrons that we used in our explanation. And this actually led to many more interesting neural network and machine learning designs.
Recommended Tutorials:
