Defining Machine Learning
Machine Learning according to Tom Mitchell at Carnegie Mellon University, is a process when “A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E ”. In simple words, think of a task of predicting traffic patterns at a busy intersection (Task T), you can run the data of previous traffic patterns (Experience E) through a machine learning algorithm and upon successfully learning, the program will improve the future traffic pattern prediction (Measure P).
Machine Learning is the discipline of learning to improve performance measure task in the future, using the experience of the task in the past. This includes making accurate predictions, completing a task, etc. The learning always require some observations or data points. Below mentioned are some of the Machine Learning use cases:
- Recognizing and finding faces in images.
- Classifying articles in categories like sports, politics, entertainment, etc.
- Recognizing handwritten characters using the images of the letters.
- Natural Language Processing
- Medical Diagnosis of Diseases using image and other sensor based data

- Supervised Learning
Under the paradigm of Supervised Learning, the program is trained on a set of data points which are pre-defined training examples. This is done to facilitate the program to find a better prediction (performance measure) on a new test data set.
- Unsupervised Learning
In unsupervised learning, the training dataset doesn’t have well defined relationships and patterns laid out for program to learn.
The basis difference between the above mentioned learnings is that for supervised learning, a portion of output dataset is provided to train the model, in order to generate the desired outputs. On the other hand, in unsupervised learning no such dataset is provided for learning, rather the data is clustered into classes.
Learn Data Science by working on interesting Data Science Projects
- Reinforced Learning
Reinforced learning involves learning and updating the parameters of model based on the feedback and errors of the output. Any dataset would be divided into two categories, training set and test set. The program is trained using the well-defined training dataset and is then fine-tuned using feedback from the results of test dataset.
Get Closer To Your Dream of Becoming a Data Scientist with 70+ Solved End-to-End ML Projects
Introduction to Probability
Probability is the most common element across most of the machine learning algorithms. This section presents a basic introduction to probability, which will help in better understanding of machine learning algorithms. A random variable X represents outcomes or states of the world.
Probability (X=x) = p(x)
The super set of all possible outcomes (be it discrete, continuous or mixed).
p(x) stands for probability density functions. It assigns a number to all the points in the sample space. The value of p(x) is always non-negative and area of the contour (integration/sum) is 1.
Joint probability distribution is the probability density function jointly for two random variables. It is equals to the probability of X=x, Y=y; p(x,y).
Conditional probability distribution is Probability(X=x|Y=y), which stands for probability of X=x given Y=y.
- Summation rule for joint probabilities
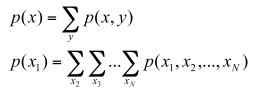
- Product/Chain rule for conditional probabilities
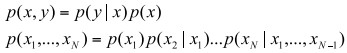

Bayesian Modelling
Bayes rule for conditional probability is as follows:
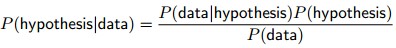

Bayes rule describes the probability of an event, based on conditions that might be related to the event. Bayes modelling can be expressed mathematically in the following equation:
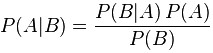

Here, P(A) and P(B) are the independent probabilities of event A and B. P(B|A) is the probability of event B, given that event A has happened and similarly P(A|B) is the probability of event A, given that event B has happened.
Recommended Tutorials:
What is Classification?
Classification is a machine learning discipline of identifying the elements to their set or categories, on the basis of a training set data, where the membership/categories of the elements are known. Classification problem is an instance of supervised learning, because the training set of identified data points is available. The mathematical function which implements classification is known as classification.
Classification can be primarily of two types; Binary classification and Multi-Class Classification. In case of binary classification, the elements are divided into two classes; on the other hand, as the name suggests multi-class classification involves assigning objects among several classes.
There are many classification algorithms and some of them are mentioned below:
- Fisher’s Linear Discriminant
- Naïve Bayes Classifier
- Logistic Regression
- Perceptron
- Support Vector Machines
- K-Nearest Neighbour
- Quadratic Classifier
- Decision
- Neural Network
Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization
What is Regression?
Given a set of 2 data, Regression aims to find the most suited mathematical relationship and represent the set of data. The purpose of Regression in machine learning is to predict the output value using the training data and the key difference between regression and classification is that; classifiers have dependent variables that are categorical, whereas Regression model have dependent variables that are continuous values.
Function: x->y
Here, if y is a categorical/discrete variable, then the function would be a classifier.
However, if y is a continuous/real number, then this will be a regression problem.
Explore More Data Science and Machine Learning Projects for Practice. Fast-Track Your Career Transition with ProjectPro
What is Clustering?
Clustering is the allocation of a set of data points into clusters, in order to make sure that data points in the clusters have some sort of resemblance in their property. Clustering is unsupervised learning, because there is not categorized training data set and because its objective is to estimate a structure in a collection of unlabelled data. Clustering algorithms can be classified in four categories as mentioned below:
- Exclusive Clustering
- Overlapping Clustering
- Hierarchical Clustering
- Probabilistic Clustering
