










































Chief Science Officer at DataPrime, Inc.

Big Data & Analytics architect, Amazon

Senior Data Engineer, Hogan Assessment Systems

Data Scientist, Inmobi
Hadoop Project- Perform basic big data analysis on airline dataset using big data tools -Pig, Hive and Athena.
Get started today
Request for free demo with us.










Schedule 60-minute live interactive 1-to-1 video sessions with experts.
Unlimited number of sessions with no extra charges. Yes, unlimited!
Give us 72 hours prior notice with a problem statement so we can match you to the right expert.
Schedule recurring sessions, once a week or bi-weekly, or monthly.
If you find a favorite expert, schedule all future sessions with them.
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
250+ end-to-end project solutions
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
15 new projects added every month
New projects every month to help you stay updated in the latest tools and tactics.
500,000 lines of code
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
600+ hours of videos
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
Cloud Lab Workspace
New projects every month to help you stay updated in the latest tools and tactics.
Unlimited 1:1 sessions
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
Technical Support
Chat with our technical experts to solve any issues you face while building your projects.
7 Days risk-free trial
We offer an unconditional 7-day money-back guarantee. Use the product for 7 days and if you don't like it we will make a 100% full refund. No terms or conditions.
Payment Options
0% interest monthly payment schemes available for all countries.
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data. In each learning path, there are many customized projects with all the details from the beginner to the expert. As a new data science learner, you can just follow these projects to master the important techniques quickly. It is really helpful for both my research and job searching. Hope you can come and join ProjectPro to win a great future for yourself.
Jingwei Li
Graduate Research assistance at Stony Brook University
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic was "Credit Risk Modelling". To understand other domains, it is important to wear a thinking cap and that's where ProjectPro helped me. I also got a chance to talk to experts who have worked on these domains - they helped me by walking through the project. Kudos to the ProjectPro team!
Gautam Vermani
Data Consultant at Confidential
I think that they are fantastic. I attended Yale and Stanford and have worked at Honeywell,Oracle, and Arthur Andersen(Accenture) in the US. I have taken Big Data and Hadoop,NoSQL, Spark, Hadoop Admin, Hadoop projects. I have been happy with every project. They have really brought me into the forefront of Data Science and Big data. I would recommend this to everyone. It is more than worth the price. After working with them I feel so much more employable for current projects.
Ray han
Tech Leader | Stanford / Yale University
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of them too, and that's when I came across ProjectPro while watching one of the SQL videos on the E-Learning Bridge YouTube channel. One of the standout features was that it featured real projects on topics I just read about, across different job descriptions at the time. The main issue was the right path to guide us in using these tools and adding to the resume, and that's exactly what ProjectPro got me through. The fact that I can have a reliable route and videos explaining each tool in detail really motivated me to continue with the platform. Another thing we all struggle with is how to really connect with someone if we're stuck somewhere because there are so many solutions. But this has also been solved by experts we can chat with and believe me when I say this they will do whatever it takes to solve your problem even if it takes longer than expected. In my sophomore year of college and getting hands-on exposure to technologies like PySpark, NLP, Kafka, etc, and being able to really apply the theory and work on a project from start to finish really boosted my confidence in general!
Savvy Sahai
Data Science Intern, Capgemini
Chief Science Officer at DataPrime, Inc.
Big Data & Analytics architect, Amazon
Senior Data Engineer, Hogan Assessment Systems
Data Scientist, Inmobi
Machine Learning Manager, Adobe
Head of Data science, OutFund
Data and Blockchain Professional
NLP Engineer, Speechkit
Principal Data Scientist - Cyber Security Risk Management, Verizon
Data Engineering Manager, Microsoft Corporation
Senior Data Platform Engineer, GoodRx
Director of Data Science & AnalyticsDirector, ZipRecruiter
Chief Scientific Officer, Machine Medicine Technologies
Senior Applied Scientist, Amazon
Senior Data Scientist, Mawdoo3 Ltd
Data Engineering Lead - Uber
Data Scientist, Boeing
Senior Data Engineer, Slintel-6sense company
Data Engineer - Capacity Supply Chain and Provisioning, Microsoft India CoE
Dev Advocate, Pinecone and Freelance ML
Data Science, Yelp
Principal Software Engineer, Afiniti
Data Science Consultant, Fractal Analytics
Data Scientist, SwissRe
Senior Data Engineer, Publicis Sapient
Big Data Engineer, Beyond Limits
Data Engineer, Microsoft
Senior Data Engineer, National Bank of Belgium
Director of Business Intelligence , CouponFollow
Global Data Community Lead | Lead Data Scientist, Thoughtworks
Data Scientist, Credit Suisse
Head of Data Science, Slated
University of Economics and Technology, Instructor
Airline data analysis involves extracting meaningful insights and patterns from the vast amount of data collected by airlines during their operations. This analysis helps airlines make informed decisions, optimize processes, enhance efficiency, improve customer experiences, and ultimately increase profitability. Here are some key areas where data analysis plays a crucial role in the airline industry:
Flight Performance Analysis: Airlines analyze data related to flight schedules, on-time performance, delays, and cancellations. This analysis helps identify the root causes of delays, assess the efficiency of flight routes, and make adjustments to improve overall performance.
Demand Forecasting: By analyzing historical booking data, airlines can predict passenger demand for different routes and time periods. Accurate demand forecasting helps optimize flight schedules, set ticket prices, and allocate resources efficiently.
Route Profitability: Data analysis allows airlines to assess the profitability of various routes by considering factors such as passenger load, operating costs, and ticket prices. This insight helps airlines make informed decisions about route expansion or reduction.
Customer Segmentation: Airlines analyze passenger data to segment customers based on their travel behavior, preferences, and demographics. This segmentation enables personalized marketing strategies and tailor-made services for different customer groups.
Revenue Management: Airlines use data analysis to implement effective revenue management strategies. By adjusting ticket prices dynamically based on demand and booking patterns, airlines can maximize their revenue and fill available seats more efficiently.
Crew Performance and Scheduling: Data analysis helps evaluate crew performance, track their working hours, and optimize crew scheduling. This ensures compliance with regulations, improves crew satisfaction, and reduces operational inefficiencies.
Maintenance Predictions: Airlines analyze maintenance data to predict potential issues with aircraft components. This proactive approach helps prevent unplanned maintenance and reduces aircraft downtime.
Operational Efficiency: Data analysis is used to assess the efficiency of various operational processes, such as baggage handling, boarding procedures, and turnaround times. Identifying bottlenecks and areas for improvement can lead to smoother operations.
Customer Experience Enhancement: By analyzing customer feedback and survey data, airlines can identify areas where they can enhance the passenger experience. This may include improving in-flight services, airport facilities, and customer service interactions.
Safety and Security Analysis: Airlines analyze safety and security-related data to identify patterns and trends that may impact operations. This allows airlines to implement measures to enhance safety and mitigate risks effectively.
To perform these analyses, airlines utilize data analytics tools, machine learning algorithms, and other advanced technologies. Data visualization techniques are also commonly used to present the findings in a clear and actionable format for decision-makers. It is essential for airlines to have robust data governance practices in place to ensure data quality, security, and compliance with relevant regulations.
Aim:
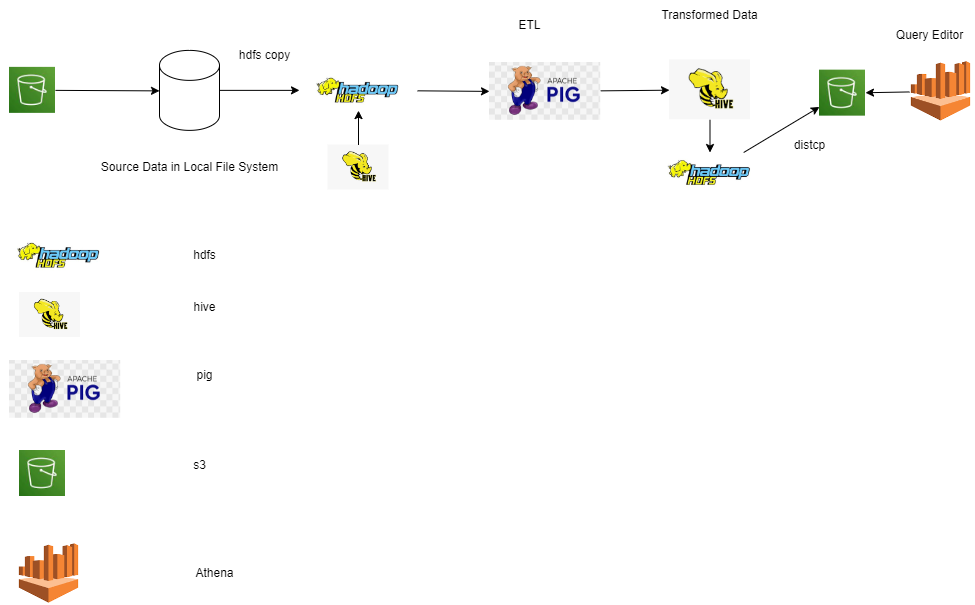
The main objective of this project is to showcase the implementation of Airline Data Processing using open source technologies like Hadoop, Hive, Pig, HDFS, and Athena. The project aims to process and analyze large volumes of airline-related data efficiently and effectively. Hadoop and HDFS provide a distributed storage and processing framework, enabling the handling of massive datasets. Hive and Pig serve as query languages and data processing tools that simplify data manipulation tasks. Additionally, Athena offers a serverless query service, facilitating interactive analysis of data stored in Amazon S3. By utilizing these technologies, the project aims to demonstrate how airlines can leverage big data solutions to extract valuable insights, optimize operations, and improve overall performance within the industry.
Tech Stack:
Language: Python, SQL
Services: AWS EMR, Apache Hadoop, Apache Hive, Pig, AWS Athena
Architecture:
Recommended
Projects
Using CookieCutter for Data Science Project Templates
Explore simplicity, versatility, and efficiency of Cookiecutter for Data science project templating and collaboration
How to Ace Databricks Certified Data Engineer Associate Exam?
Prepare effectively and maximize your chances of success with this guide to master the Databricks Certified Data Engineer Associate Exam. | ProjectPro
Data Science vs Data Engineering:Choosing Your Career Path
Data Science vs Data Engineering-Learn key differences, and career tips to seamlessly transition from data engineer to data scientist with ProjectPro
Get a free demo
ProjectPro
![]()
![]()
![]()



































