Data Scientist, Boeing

Head of Data Science, Slated

Global Data Community Lead | Lead Data Scientist, Thoughtworks

Senior Applied Scientist, Amazon
Learn how to build an Incremental ETL Pipeline with AWS CDK using Cryptocurrency data
Get started today
Request for free demo with us.










Schedule 60-minute live interactive 1-to-1 video sessions with experts.
Unlimited number of sessions with no extra charges. Yes, unlimited!
Give us 72 hours prior notice with a problem statement so we can match you to the right expert.
Schedule recurring sessions, once a week or bi-weekly, or monthly.
If you find a favorite expert, schedule all future sessions with them.
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
250+ end-to-end project solutions
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
15 new projects added every month
New projects every month to help you stay updated in the latest tools and tactics.
500,000 lines of code
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
600+ hours of videos
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
Cloud Lab Workspace
New projects every month to help you stay updated in the latest tools and tactics.
Unlimited 1:1 sessions
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
Technical Support
Chat with our technical experts to solve any issues you face while building your projects.
7 Days risk-free trial
We offer an unconditional 7-day money-back guarantee. Use the product for 7 days and if you don't like it we will make a 100% full refund. No terms or conditions.
Payment Options
0% interest monthly payment schemes available for all countries.
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic was "Credit Risk Modelling". To understand other domains, it is important to wear a thinking cap and that's where ProjectPro helped me. I also got a chance to talk to experts who have worked on these domains - they helped me by walking through the project. Kudos to the ProjectPro team!
Gautam Vermani
Data Consultant at Confidential
I am the Director of Data Analytics with over 10+ years of IT experience. I have a background in SQL, Python, and Big Data working with Accenture, IBM, and Infosys. I am looking to enhance my skills in Data Engineering/Science and hoping to find real-world projects fortunately, I came across Project Pro. Project Pro helped me by providing an in-depth explanation of the end-to-end real-world data engineering projects. From data extraction, transformation, and storage up to data visualization. I learned more about Kafka, AWS, NI-FI, and Spark. Thru the help of the knowledge I gained from Project Pro, I was able to do well in the coding exams, interview and helped me land a job at EY. I will recommend every aspiring data professional as well as existing data science/engineer expert to try Project Pro to enhance their knowledge.
Ed Godalle
Director Data Analytics at EY / EY Tech
I come from Northwestern University, which is ranked 9th in the US. Although the high-quality academics at school taught me all the basics I needed, obtaining practical experience was a challenge. This is when I was introduced to ProjectPro, and the fact that I am on my second subscription year only goes to prove that the ROI is satisfactory. I managed to switch to analytics companies, only because of the relevant practical experience this product served me with. I now work at a leading healthcare startup as a Senior Analytics Consultant. I am a customer who is not only satisfied with ProjectPro but also mighty impressed by how Dezyre bends over backward to ensure customer satisfaction. I have had a couple of interactions with Binny and each time I was left happy and content. I also had a conversation with their investors, and I was really glad to articulate my appreciation of the product. They not only have enterprise-grade projects, but also set up 1:1 sessions with seasoned experts in case we get stuck, or are having trouble understanding a certain concept. As the cherry on the icing, there are experts to guide you with resume writing and interview preparation as well, to culminate the whole process of making you job-ready. Kudos to ProjectPro!
Abhinav Agarwal
Graduate Student at Northwestern University
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of them too, and that's when I came across ProjectPro while watching one of the SQL videos on the E-Learning Bridge YouTube channel. One of the standout features was that it featured real projects on topics I just read about, across different job descriptions at the time. The main issue was the right path to guide us in using these tools and adding to the resume, and that's exactly what ProjectPro got me through. The fact that I can have a reliable route and videos explaining each tool in detail really motivated me to continue with the platform. Another thing we all struggle with is how to really connect with someone if we're stuck somewhere because there are so many solutions. But this has also been solved by experts we can chat with and believe me when I say this they will do whatever it takes to solve your problem even if it takes longer than expected. In my sophomore year of college and getting hands-on exposure to technologies like PySpark, NLP, Kafka, etc, and being able to really apply the theory and work on a project from start to finish really boosted my confidence in general!
Savvy Sahai
Data Science Intern, Capgemini
Data Scientist, Boeing
Head of Data Science, Slated
Global Data Community Lead | Lead Data Scientist, Thoughtworks
Senior Applied Scientist, Amazon
Data Scientist, Credit Suisse
Data Engineer - Capacity Supply Chain and Provisioning, Microsoft India CoE
Principal Software Engineer, Afiniti
Chief Science Officer at DataPrime, Inc.
Data Scientist, SwissRe
Senior Data Engineer, National Bank of Belgium
Senior Data Engineer, Hogan Assessment Systems
Data Engineering Manager, Microsoft Corporation
Big Data Engineer, Beyond Limits
Senior Data Scientist, Mawdoo3 Ltd
Data Engineering Lead - Uber
Head of Data science, OutFund
Senior Data Engineer, Slintel-6sense company
Dev Advocate, Pinecone and Freelance ML
Director of Data Science & AnalyticsDirector, ZipRecruiter
NLP Engineer, Speechkit
Chief Scientific Officer, Machine Medicine Technologies
Principal Data Scientist - Cyber Security Risk Management, Verizon
Data and Blockchain Professional
Big Data & Analytics architect, Amazon
Senior Data Engineer, Publicis Sapient
Data Scientist, Inmobi
Data Science Consultant, Fractal Analytics
Data Engineer, Microsoft
Machine Learning Manager, Adobe
Director of Business Intelligence , CouponFollow
Data Science, Yelp
University of Economics and Technology, Instructor
Senior Data Platform Engineer, GoodRx
Business Overview
Cryptocurrency refers to digital or virtual currencies that use cryptography for secure financial transactions, control the creation of additional units, and verify the transfer of assets. Cryptocurrencies leverage decentralized technology called blockchain, which is a distributed ledger maintained by a network of computers.
The most well-known and widely used cryptocurrency is Bitcoin, which was introduced in 2009. Bitcoin was the first decentralized cryptocurrency and remains the largest by market capitalization. Since the creation of Bitcoin, thousands of other cryptocurrencies, often referred to as altcoins (alternative coins), have been developed.
Cryptocurrency data analytics refers to the analysis and interpretation of data related to cryptocurrencies and their markets. With the increasing popularity and complexity of the cryptocurrency market, data analytics plays a crucial role in understanding trends, making informed decisions, and identifying opportunities within the crypto space.
Here are some key aspects of cryptocurrency data analytics:
Market Data Analysis: This involves analyzing historical and real-time market data, including price movements, trading volumes, liquidity, market capitalization, and order book data. By examining these data points, analysts can identify patterns, trends, and market sentiment to gain insights into the market's behavior.
Blockchain Analysis: Since most cryptocurrencies operate on blockchain technology, blockchain analysis is essential for understanding transaction flows, addresses, and network behavior. It can help identify key addresses, track fund movements, and detect anomalies or suspicious activities.
Sentiment Analysis: Sentiment analysis involves examining social media posts, news articles, and other textual data to gauge the sentiment and public perception surrounding specific cryptocurrencies. This analysis helps understand market sentiment, public opinion, and the impact of news events on cryptocurrency prices.
Trading Strategies and Predictive Modeling: Advanced data analytics techniques, such as machine learning and predictive modeling, can be applied to cryptocurrency data to develop trading strategies and forecasting models. These models aim to predict future price movements, identify trading opportunities, and manage risk.
Risk Assessment and Security: Data analytics can help assess and quantify the risks associated with cryptocurrencies, such as market volatility, liquidity risk, and cybersecurity vulnerabilities. It enables the development of risk management strategies and the identification of potential threats.
Cryptocurrency data analytics can be performed using a variety of tools and platforms that provide access to historical and real-time data, as well as specialized analytics capabilities. These tools often include charting platforms, data visualization tools, sentiment analysis tools, and machine learning libraries.
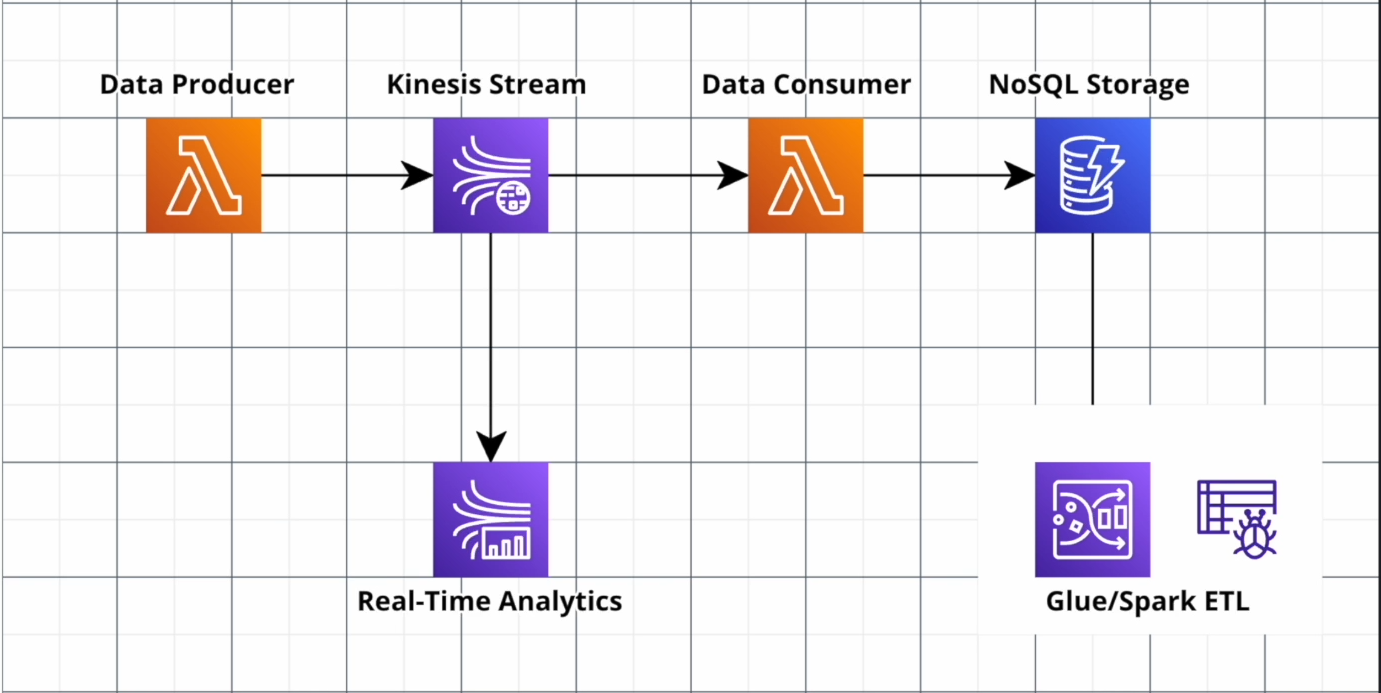
We aim to develop an incremental Extract, Transform, Load (ETL) solution utilizing AWS CDK to analyze cryptocurrency data. This will involve constructing a serverless pipeline in which lambda functions are utilized to retrieve data from an API and stream it into Kinesis streams. Additionally, we will create another lambda function to consume the data from the Kinesis stream, apply necessary transformations, and store it in DynamoDB.
To perform data analytics on the incoming data within the Kinesis streams, we will leverage Apache Flink and Apache Zeppelin. These tools will enable us to extract insights and derive valuable information from the data. AWS serverless technologies, such as Amazon Lambda and Amazon Glue, will be employed to efficiently process and transform the data from the three different data sources.
Furthermore, we will utilize Amazon Athena, a query service, to analyze the transformed data stored in DynamoDB. This will facilitate efficient querying and exploration of the data, enabling us to extract meaningful insights and make informed decisions based on the cryptocurrency data.
By combining these AWS services and technologies, we aim to create a robust and scalable solution for analyzing cryptocurrency data, allowing for comprehensive data processing, transformation, and analytics.
Dataset Description
Alpha Vantage offers enterprise-grade financial market data via a collection of robust and developer-friendly data APIs and spreadsheets. Alpha Vantage is your one-stop shop for real-time and historical global market data delivered through REST stock APIs, Excel, and Google Sheets, ranging from traditional asset classes (e.g., stocks, ETFs, commodities) to economic metrics, foreign exchange rates to cryptocurrencies, fundamental data to technical indicators.
Tech Stack
➔ Language: Python
➔ Services: AWS S3, Amazon Lambda, AWS Kinesis,Amazon Aurora, AWS Glue, Amazon Athena, Quicksight, AWS CDK
AWS CDK:
The AWS Cloud Development Kit (AWS CDK) is an open-source software development platform for defining cloud architecture in code and provisioning it using AWS CloudFormation. It provides a high-level object-oriented framework for defining AWS resources with the capability of current programming languages. You can quickly include AWS best practices in your infrastructure definition and publish it without worrying about boilerplate logic using CDK's library of infrastructure components.
Note: For text-based approach, please note that a comprehensive CookBook is provided for the execution of this project as an alternate to the videos.
Architecture Diagram:
Recommended
Projects
Evolution of Data Science: From SAS to LLMs
Explore the evolution of data science from early SAS to cutting-edge LLMs and discover industry-transforming use cases with insights from an industry expert.
How to Learn Tableau for Data Science in 2024?
Wondering how to learn Tableau for Data Science? This blog offers easy-to-follow tips to help you master Tableau for visualizing & analyzing data. ProjectPro
Data Products-Your Blueprint to Maximizing ROI
Explore ProjectPro's Blueprint on Data Products for Maximizing ROI to Transform your Business Strategy.
Get a free demo
ProjectPro
![]()
![]()
![]()