










































Data Science, Yelp

Senior Data Scientist, Mawdoo3 Ltd

Big Data Engineer, Beyond Limits

Chief Scientific Officer, Machine Medicine Technologies
In this hive project, you will design a data warehouse for e-commerce application to perform Hive analytics on Sales and Customer Demographics data using big data tools such as Sqoop, Spark, and HDFS.
Get started today
Request for free demo with us.
Schedule 60-minute live interactive 1-to-1 video sessions with experts.
Unlimited number of sessions with no extra charges. Yes, unlimited!
Give us 72 hours prior notice with a problem statement so we can match you to the right expert.
Schedule recurring sessions, once a week or bi-weekly, or monthly.
If you find a favorite expert, schedule all future sessions with them.
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
250+ end-to-end project solutions
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
15 new projects added every month
New projects every month to help you stay updated in the latest tools and tactics.
500,000 lines of code
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
600+ hours of videos
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
Cloud Lab Workspace
New projects every month to help you stay updated in the latest tools and tactics.
Unlimited 1:1 sessions
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
Technical Support
Chat with our technical experts to solve any issues you face while building your projects.
7 Days risk-free trial
We offer an unconditional 7-day money-back guarantee. Use the product for 7 days and if you don't like it we will make a 100% full refund. No terms or conditions.
Payment Options
0% interest monthly payment schemes available for all countries.
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of them too, and that's when I came across ProjectPro while watching one of the SQL videos on the E-Learning Bridge YouTube channel. One of the standout features was that it featured real projects on topics I just read about, across different job descriptions at the time. The main issue was the right path to guide us in using these tools and adding to the resume, and that's exactly what ProjectPro got me through. The fact that I can have a reliable route and videos explaining each tool in detail really motivated me to continue with the platform. Another thing we all struggle with is how to really connect with someone if we're stuck somewhere because there are so many solutions. But this has also been solved by experts we can chat with and believe me when I say this they will do whatever it takes to solve your problem even if it takes longer than expected. In my sophomore year of college and getting hands-on exposure to technologies like PySpark, NLP, Kafka, etc, and being able to really apply the theory and work on a project from start to finish really boosted my confidence in general!
Savvy Sahai
Data Science Intern, Capgemini
ProjectPro is a unique platform and helps many people in the industry to solve real-life problems with a step-by-step walkthrough of projects. A platform with some fantastic resources to gain hands-on experience and prepare for job interviews. I would highly recommend this platform to anyone looking to upskill and stay updated with the latest projects and solutions. Overall this platform is awesome and worth the money spent as we get a lot of value out of it and helps soar our career to greater heights.
Anand Kumpatla
Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data. In each learning path, there are many customized projects with all the details from the beginner to the expert. As a new data science learner, you can just follow these projects to master the important techniques quickly. It is really helpful for both my research and job searching. Hope you can come and join ProjectPro to win a great future for yourself.
Jingwei Li
Graduate Research assistance at Stony Brook University
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic was "Credit Risk Modelling". To understand other domains, it is important to wear a thinking cap and that's where ProjectPro helped me. I also got a chance to talk to experts who have worked on these domains - they helped me by walking through the project. Kudos to the ProjectPro team!
Gautam Vermani
Data Consultant at Confidential
Data Science, Yelp
Senior Data Scientist, Mawdoo3 Ltd
Big Data Engineer, Beyond Limits
Chief Scientific Officer, Machine Medicine Technologies
Data Engineer - Capacity Supply Chain and Provisioning, Microsoft India CoE
Senior Data Engineer, Publicis Sapient
Senior Data Engineer, Hogan Assessment Systems
Data Scientist, Boeing
Senior Data Engineer, Slintel-6sense company
Data Scientist, Credit Suisse
NLP Engineer, Speechkit
Principal Software Engineer, Afiniti
Data Science Consultant, Fractal Analytics
Data and Blockchain Professional
Senior Applied Scientist, Amazon
Director of Business Intelligence , CouponFollow
Big Data & Analytics architect, Amazon
Principal Data Scientist - Cyber Security Risk Management, Verizon
Data Engineering Lead - Uber
Senior Data Platform Engineer, GoodRx
Chief Science Officer at DataPrime, Inc.
Data Scientist, SwissRe
Data Scientist, Inmobi
Head of Data Science, Slated
Head of Data science, OutFund
Machine Learning Manager, Adobe
Data Engineering Manager, Microsoft Corporation
Data Engineer, Microsoft
Senior Data Engineer, National Bank of Belgium
University of Economics and Technology, Instructor
Dev Advocate, Pinecone and Freelance ML
Global Data Community Lead | Lead Data Scientist, Thoughtworks
Director of Data Science & AnalyticsDirector, ZipRecruiter
We will dig deeper into some of the Hive's analytical features for this hive project. Using SQL is still highly popular, and it will be for the foreseeable future. Most big data technologies have been modified to allow users to interact with them using SQL. This is due to the years of experience and expertise put into training, acceptance, tooling, standard development, and re-engineering. So, in many circumstances, employing these excellent SQL tools to access data may answer many analytical queries without resorting to machine learning, business intelligence, or data mining.
This big data project will look at Hive's capabilities to run analytical queries on massive datasets. We will use the Adventure works dataset in a MySQL dataset for this project, and we'll need to ingest and modify the data. We'll use Adventure works sales and Customer demographics data to perform analysis and answer the following questions:
Which age group of customers contribute to more sales?
To find the upper and lower discount limits offered for any product
Sales contributions by customer
To Understand customer persona purchasing pattern based on gender, education and yearly income
To find the sales contribution by customers on the overall year to date sales belong to categorized by same gender, yearly income.
To identify the top performing territory based on sales
To find the territory-wise sales and their adherence to the defined sales quota.
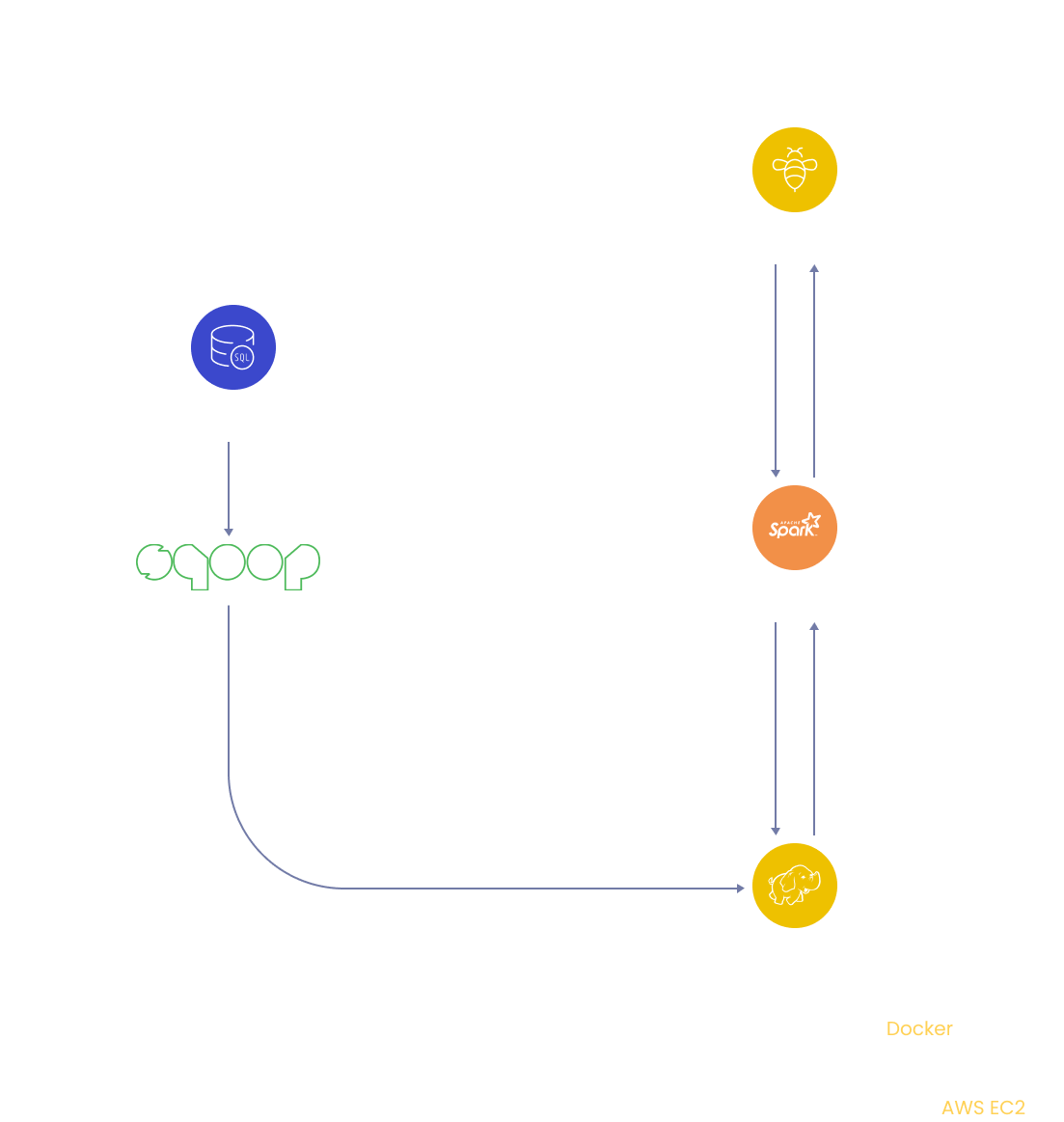
To perform Hive analytics on Sales and Customer Demographics data using big data tools such as Sqoop, Spark, and HDFS.
Adventure Works is a free sample database of retail sales data. In this project, we will be only using Customer test, Individual test, Credit card, Sales order details, Store, Sales territory, Salesperson, Sales order header, Special offer tables from this database.
➔ Language: SQL, Scala
➔ Services: AWS EC2, Docker, MySQL, Sqoop, Hive, HDFS, Spark
Amazon EC2 instance is a virtual server on Amazon's Elastic Compute Cloud (EC2) for executing applications on the Amazon Web Services (AWS) architecture. Corporate customers can use the Amazon Elastic Compute Cloud (EC2) service to run applications in a computer environment. Amazon EC2 eliminates the need for upfront hardware investment, allowing customers to design and deploy projects quickly. Users can launch up to 10 virtual servers, configure security and networking, and manage storage on Amazon EC2.
Docker is a free and open-source containerization platform, and it enables programmers to package programs into containers. These standardized executable components combine application source code with the libraries and dependencies required to run that code in any environment.
MySQL is a SQL (Structured Query Language) based relational database management system. The platform can be used for data warehousing, e-commerce, logging applications, etc.
Sqoop is a data transfer mechanism for Hadoop and relational database servers. It is used to import data from relational databases such as MySQL and Oracle into Hadoop HDFS, Hive, and export data from the Hadoop file system to relational databases.
Scala is a multi-paradigm, general-purpose, high-level programming language. It's an object-oriented programming language that also supports functional programming. Scala applications can be converted to bytecodes and run on the Java Virtual Machine (JVM). Scala is a scalable programming language, and JavaScript runtimes are also available.
Apache Hive is a fault-tolerant distributed data warehouse that allows for massive-scale analytics. Using SQL, Hive allows users to read, write, and manage petabytes of data. Hive is built on top of Apache Hadoop, an open-source platform for storing and processing large amounts of data. As a result, Hive is inextricably linked to Hadoop and is designed to process petabytes of data quickly. Hive is distinguished by its ability to query large datasets with a SQL-like interface utilizing Apache Tez or MapReduce.
Create an AWS EC2 instance and launch it.
Create docker images using docker-compose file on EC2 machine via ssh.
Create tables in MySQL.
Load data from MySQL into HDFS storage using Sqoop commands.
Move data from HDFS to Hive.
Integrate Hive into Spark.
Using Scala programming language, extract Customer demographics information from data and store it as parquet files.
Move parquet files from Spark to Hive.
Create tables in Hive and load data from Parquet files into tables.
Perform Hive analytics on Sales and Customer demographics data.
Recommended
Projects
Adam Optimizer Simplified for Beginners in ML
Unlock the power of Adam Optimizer: from theory, tutorials, to navigating limitations.
Learning Optimizers in Deep Learning Made Simple
Understand the basics of optimizers in deep learning for building efficient algorithms.
30+ Python Pandas Interview Questions and Answers
Prepare for Data Science interviews like a pro! Check out our blog with 30+ Python Pandas Interview questions and answers. | ProjectPro
Get a free demo
ProjectPro
![]()
![]()
![]()



































