Explain with example how to perform subquery union and union all?
This recipe explains what with example how to perform subquery union and union all
Recipe Objective
In most of the big data scenarios , Hive is used as an ETL and data warehouse tool on top of the hadoop ecosystem, it is used for the processing of the different types structured and semi-structured data, it is a database. Hive gives you data summarization, querying , and analysis of data. To querying hive we will you use a query language called as HiveQL(Hive Query Language).Hive allows you to store a structured and unstructured data..After you define the structure, you can use HiveQL to query the data
System requirements :
- Install ubuntu in the virtual machine click here
- Install single node hadoop machine click here
- Install apache hive click here
Table of Contents
Step 1 : Prepare the dataset
Here we are using the salesman and orders related datasets for the create hive tables in local to perform subqueries on the tables.
Use linux command to check data as follows:
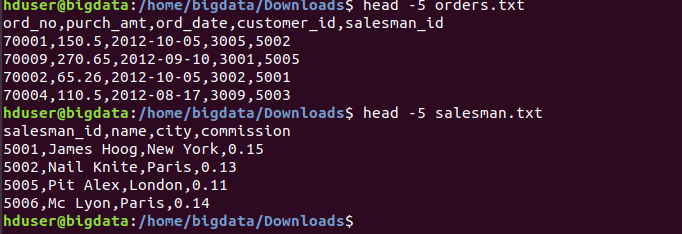
head -5 /home/bigdata/Downloads/salesman.txt
head -5 /home/bigdata/Downloads/orders.txt
Data of Output looks as follows:
Before create a table open the hive shell, we need to create a database as follows Open the hive shell

To create database :
Create database dezyre_db;
use dezyre_db;

Step 2 : Create a Hive Tables and Load the data into the tables and verify the data
Here we are going create a hive tables as follows
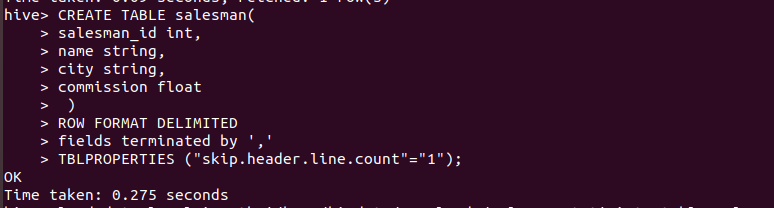
CREATE TABLE salesman(
salesman_id int,
name string,
city string,
commission float
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
Using below query we are going to load data into table as follow:
load data local inpath '/home/bigdata/Downloads/salesman.txt' into table salesman;

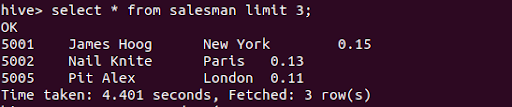
To verify the data :
select * from salesman limit 3;
Create another table, load and verify the data
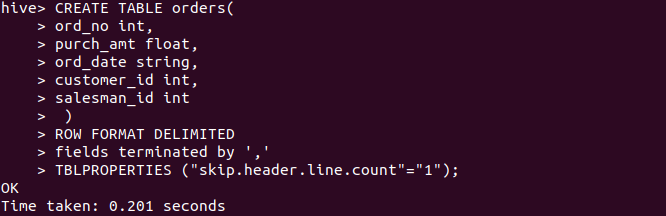
CREATE TABLE orders(
ord_no int,
purch_amt string,
ord_date string,
customer_id int,
Salesman_id int
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
Using below query we are going to load data into table as follow:
load data local inpath '/home/bigdata/Downloads/orders.txt' into table orders;

To verify the data use below query:
select * from orders limit 3; 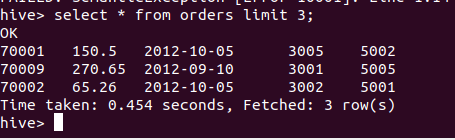
Step 3 : To perform a Subquery
Hive supports subqueries in FROM clauses and in WHERE clauses of SQL statements A hive subquery is a select expression it is enclosed as parentheses. In this scenario we are going to Display all the orders from the orders table issued by a particular salesman as below.
SELECT *
FROM orders
WHERE salesman_id =
(SELECT salesman_id
FROM salesman
WHERE name='Paul Adam');
The above query runs mapreduce job to perform a query as below :

Output of the above query :

Step 4 : Perform a Union on two tables :
The UNION operator is used to combine the result-set of two or more SELECT statements. UNION operation eliminates the duplicated rows from the result set but UNION ALL returns all rows after joining.
In this scenario we are going to perform union operator on the two hive tables getting the id's from the table
SELECT salesman_id FROM salesman UNION SELECT salesman_id FROM orders ORDER BY salesman_id ;
The above union set operator runs as below
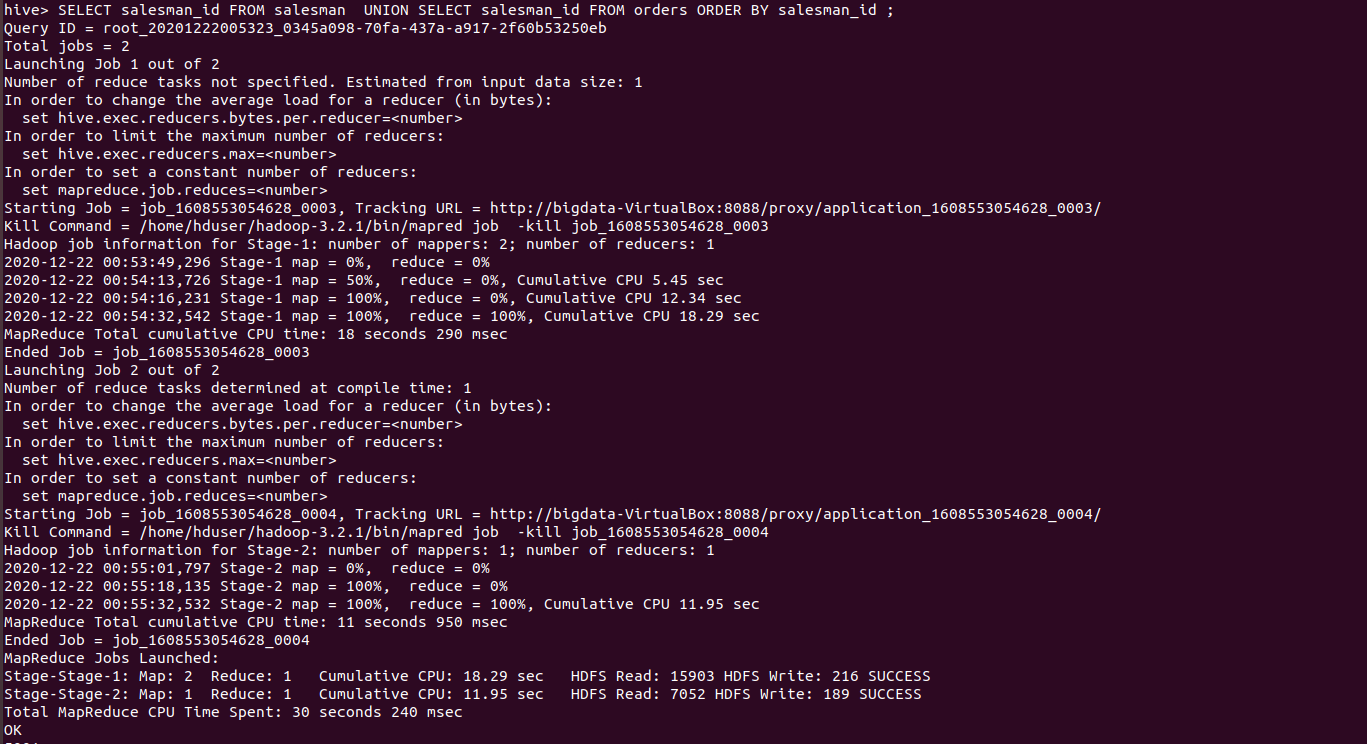
Output of the above query :
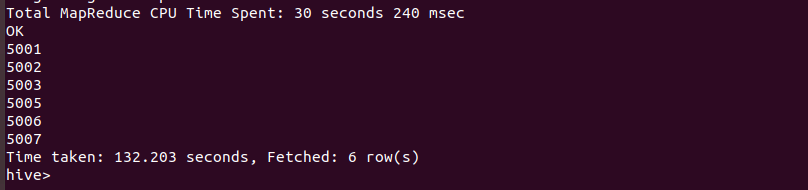
Step 5 : Perform a Union all on two tables :
UNION ALL is faster than UNION, but to remove duplicates the result set must be sorted, and this may have an impact on the performance of the UNION, depending on the volume of data being sorted.UNION result set is sorted in ascending order whereas UNION ALL Result set is not sorted
In this scenario we are going to perform union all operator on the two hive tables getting the id's from the table
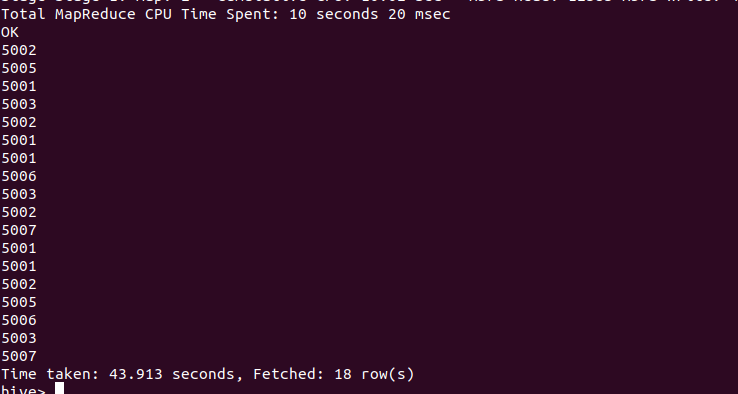
SELECT salesman_id FROM salesman UNION ALL SELECT salesman_id FROM orders ORDER BY salesman_id ;
The above union set operator runs as below
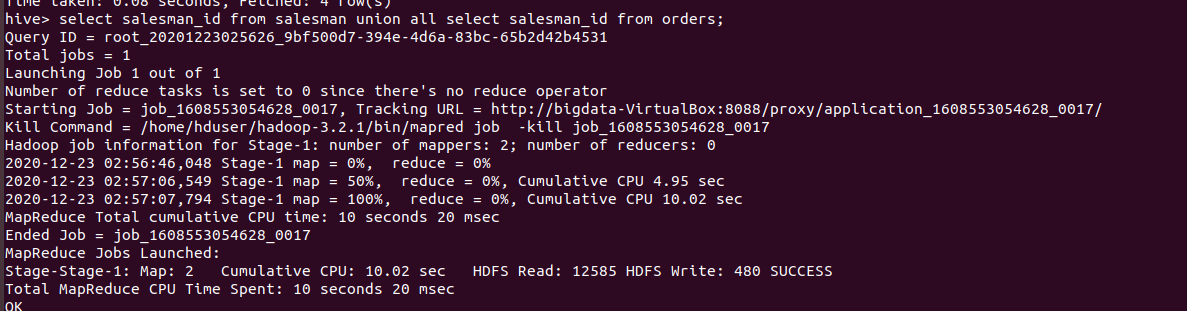
Output of the above query:

What Users are saying..

Jingwei Li
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data.... Read More