How to list the file search through a given path for all files that ends with txt in python
This recipe helps you list the file search through a given path for all files that ends with txt in python
Recipe Objective
This recipe lists the files in the local system using Python. This is reusable code and can be used for automation of data processes using data orchestration tools such as Airflow etc. It automatically lists the file with a certain extension at a certain location in the HDFS / local file system and that data can be useful to pass into a dataframe and perform further data analysis like cleaning, validation etc.
System requirements :
- Install the python module as follows if the below modules are not found:
pip install ospip install syspip install glob- The below codes can be run in Jupyter notebook , or any python console
Table of Contents
Step 1: Using the 'OS' library
The OS module provides a portable way of using operating system dependent functionality. os.listdir() method in python is used to get the list of all files and directories in the specified directory. If we don't specify any directory, then list of files and directories in the current working directory will be returned.
simple code for list of files in the current directory.
import os, sys
# Open a file
dirs = os.listdir('.')
# '.' means the current directory, you can give the directory path in between the single quotes.
# This would print all the files and directories
for file in dirs:
print (file)
It will return a list containing the names of the entries in the directory given by path.
Output of the above code:

Step 2: Using the 'glob' library
glob is mostly a filename pattern matching library, but it can be used to list items in the current directory by:
# Importing the glob library
import glob
# Path to the directory
path = ''
# or
# path = './'
# you can pass the directory path in between the single quotes.
# '.' or '' means the current directory,
# Extract the list of filenames
files = glob.glob(path + '*', recursive=False)
# Loop to print the filenames
for filename in files:
print(filename)
Output of the above code:
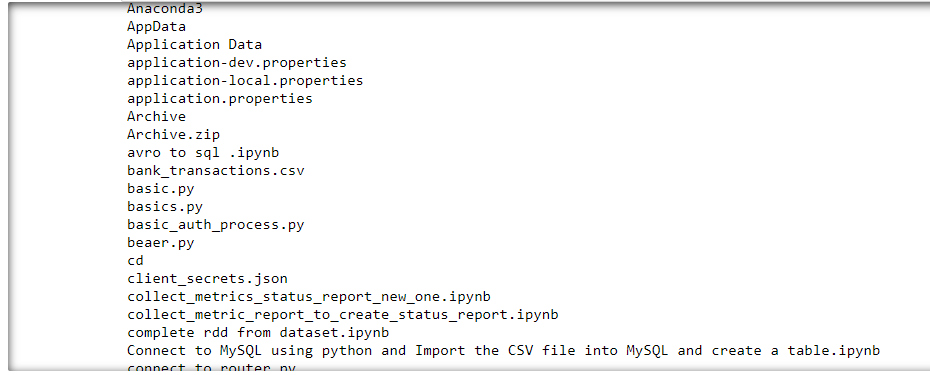
The wildcard character '*' is used to match all the items in the current directory. Since we wish to display the items of the current directory, we need to switch off the recursive nature of glob() function.
Step 3: Using the string methods
Simple code to search and list out and print the specific extension filenames using string methods, .startswith() and .endswith() in the current directory
import os
#Get .txt files
for f_name in os.listdir('.'):
if f_name.endswith('.txt'):
print(f_name)
Output of the above code:

Step 4 : List Files in a Directory with a Specific Extension and given path
import os
req_path = input("Enter your dir path :")
if os.path.isfile(req_path):
print(f"the given path {req_path} is a file. please pass only dir path")
else:
all_f_dir=os.listdir(req_path)
if len(all_f_dir)==0:
print(f"the given path is {req_path} an empty path")
else:
req_ext = input("Enter the required files extension")
req_files =[]
print(f"Listing all {req_ext} files")
for each_f in all_f_dir:
if each_f.endswith(req_ext):
req_files.append(each_f)
# print(each_f)
if len(req_files)==0:
print(f"No {req_ext}files in the location of {req_path}")
else:
print(f"there are {len(req_files)} files in the location of {req_path} with an extension of {req_ext}")
print(f"so, the files are: {req_files}")
Output of the above code: Here it prints the list of .txt extension files as shown below.


What Users are saying..

Savvy Sahai
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of... Read More