How to perform data validation using python by sorting columns on name?
This recipe helps you perform data validation using python by sorting columns on name
Recipe Objective
In most of the big data scenarios , Sorting/ordering is a process of arranging items systematically, and has two common, yet distinct meanings: ordering: arranging items in a sequence ordered by some criterion; categorizing: grouping items with similar properties. Ordering of the field names is extremely required before storing the data in the required order , so that it can be further processed by creating schema on top of it and doing further processing.
Master the Art of Data Cleaning in Machine Learning
System requirements :
- Install the python module as follows if the below modules are not found:
pip install pandas- The below codes can be run in Jupyter notebook, or any python console
Step 1: Import the module
In this scenario we are going to use pandas numpy and random libraries import the libraries as below :
import pandas as pd
Step 2 :Prepare the dataset
Here we are using the stock sales related excel dataset to from the local Please download from here Click Here to Download
Data of Output looks as follows:
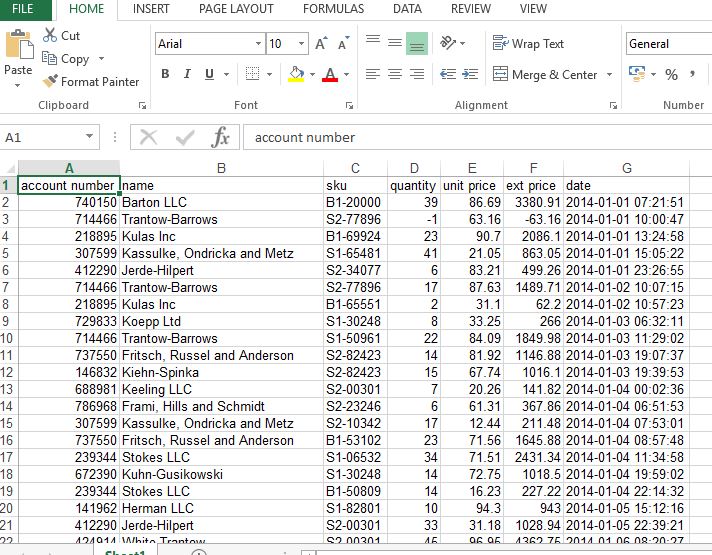
Reading the excel file using pandas library as below and storing data as data frame and print 5 line of data.
df = pd.read_excel('sales_data.xlsx')
df.head()
Output of the above code :
To print only the column names type df.columns

Step 3: Add underscore instead of Space
Here in the code below we are going to add underscore instead of space using the replace method and to convert the column names into uppercase upper method.
for col in df.columns:
df.rename(columns={col:col.upper().replace(" ","_")},inplace=True)
print(df.columns)
Output of the above code :

Step 4: Arrange or sorting the columns
Here we are going to sort and arrange the columns based on the column name, so it means that we arrange the columns in alphabetical order.
df = df[sorted(df)]
validation = df
validation['chk'] = validation['ACCOUNT_NUMBER'].apply(lambda x: True if x in df else False)
validation = validation[validation['chk'] == True].reset_index()
df
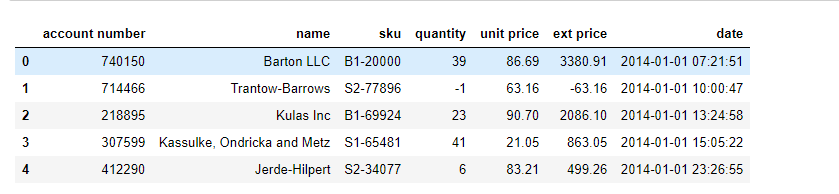
Output of the above code :
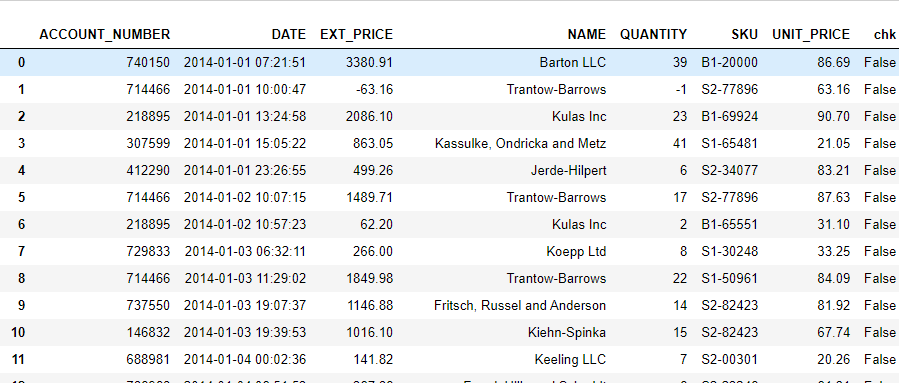
Create a new dataframe and rename the column names as below
renamed_data = df.rename(columns = {'ACCOUNT_NUMBER': 'acnt_num','DATE':'buy_date','EXT_PRICE':'ext_price','NAME':'acc_holder_name',
'QUANTITY':'quantity','SKU':'stock_keep_unit', 'UNIT_PRICE':'unit_price'})
renamed_data.columns
renamed_data
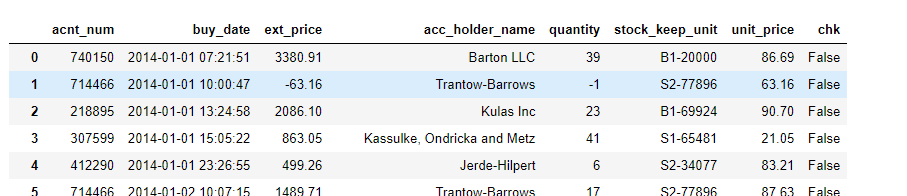
Output of the above code :

Step 5: Convert string to Date Data type and Select the row between dates
Here we have a column buy_date is string data type so we are going to convert the string data type date data type and we will select the row in between dates as follows below
Convert the string to Date datatype as below code:
renamed_data['buy_date'] = pd.to_datetime(renamed_data['buy_date'])
renamed_data['buy_date'].head()
Output of the above code :
Convert the string to Date datatype as below code:
start_date = pd.to_datetime('2014-01-08 17:46:40')
end_date = pd.to_datetime('2014-01-23 20:40:21')
renamed_data.loc[(renamed_data['buy_date'] > start_date) & (renamed_data['buy_date'] < end_date)]
Output of the above code :

What Users are saying..

Anand Kumpatla
ProjectPro is a unique platform and helps many people in the industry to solve real-life problems with a step-by-step walkthrough of projects. A platform with some fantastic resources to gain... Read More