How to perform Joins in hive ?
This recipe helps you perform Joins in hive
Recipe Objective
In most of the big data scenarios , Hive is used for the processing of the different types of structured and semi-structured data. Joins are used to combine records from two or more tables in the hive database. A JOIN is a means for combining fields from two tables by using values common to each. Joins are the most important feature in data engineering SQL based analytics
ETL Orchestration on AWS using Glue and Step Functions
System requirements :
- Install ubuntu in the virtual machine click here
- Install single node hadoop machine click here
- Install apache hive click here
Step1 : Prepare the dataset
The dataset used here is authors and books related datasets for creating the hive tables in local to perform the different types of joins.
Use linux command to check data as follows:
head -5 /home/bigdata/Downloads/list_authors.txt
head -5 /home/bigdata/Downloads/nameofbooks.txt
Data of Output looks as follows:

Before create a table open the hive shell , we need to create a database as follows Open the hive shell

To create database :
Create database dezyre_db;
use dezyre_db;

Step 2 : Create a Hive Tables and Load the data into the tables and verify the data
Here we are going create a hive tables as follows
CREATE TABLE authors(
id int,
author_name string ,
country string
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");

Using below query we are going to load data into table as follow:
load data local inpath '/home/bigdata/Downloads/list_authors.txt' into table authors;

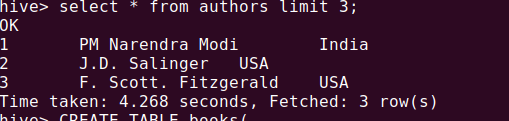
To verify the data :
select * from authors limit 3;
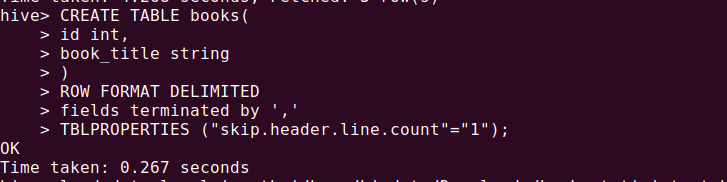
Create another table, load and verify the data
CREATE TABLE books(
id int,
book_title string
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
Using below query we are going to load data into table as follow:
load data local inpath '/home/bigdata/Downloads/namesofbooks.txt' into table books;

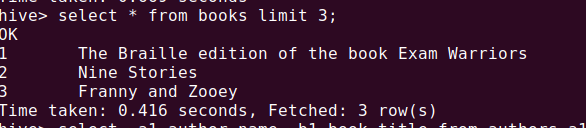
To verify the data use below query:
select * from books limit 3;
Step 3 : To perform different joins on the tables
INNER JOIN : The inner join will give the all the matched records from left and right tables if there is a match between the columns
To perform the inner join operation by using the following below command :
select a1.author_name, b1.book_title from authors a1 join books b1 on a1.id= b1.id;
Query runs as follows and the run below output:

LEFT OUTER JOIN : Left outer join will give you the all the values which are matched from the right table and left table all values
To perform the left outer join operation by using the following command: -
select a1.author_name, b1.book_title from authors a1 left outer join books b1 on a1.id= b1.id;
Query runs as follows and the run below output:

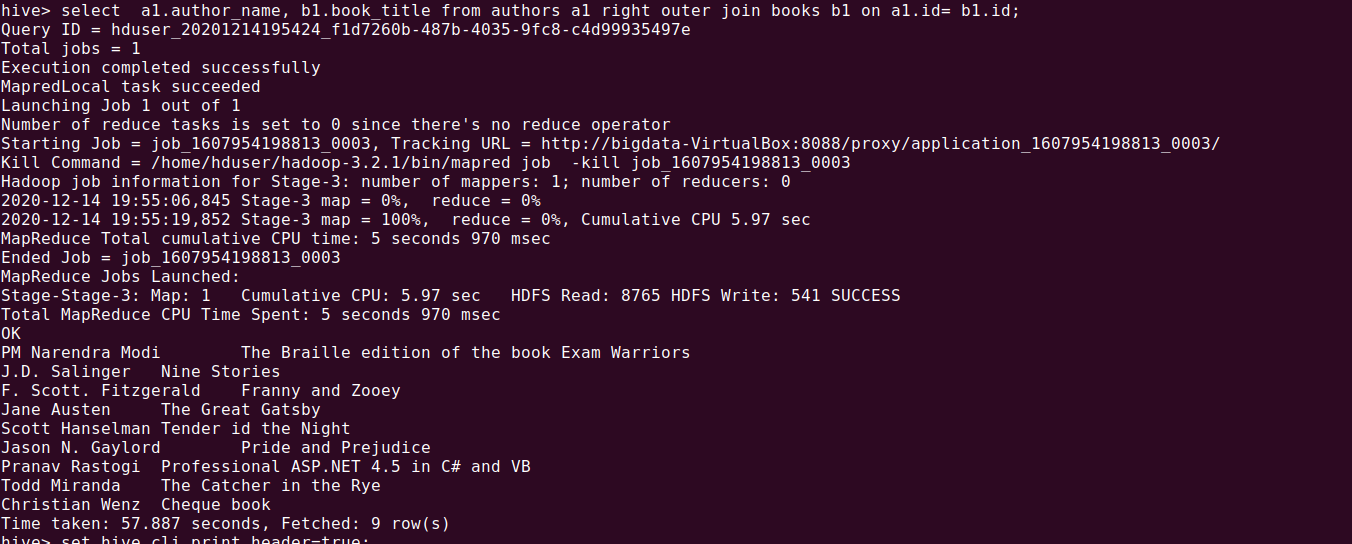
RIGHT OUTER JOIN : The right outer join will give you all the values which are matched from the left table and all values from the right table.
To perform the right outer join operation by using the following command: -
select a1.author_name, b1.book_title from authors a1 right outer join books b1 on a1.id= b1.id;
Query runs as follows and the run below output:
FULL OUTER JOIN : The full outer join will give all records from when there is a match in left or right.
To perform the full outer join operation by using the following command: -
select a1.author_name, b1.book_title from authors a1 full outer join books b1 on a1.id= b1.id;
Query runs as follows and the run below output:


What Users are saying..

Jingwei Li
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data.... Read More