How to read csv data from local system and remove extra columns and change date formats in python
This recipe helps you read csv data from local system and remove extra columns and change date formats in python
Recipe Objective
In most of the big data scenarios , data transformations follow the data cleaning and validation operations . The operations shown in this recipe are most widely used in the industry and can be re-used in various large scale industry environments.
Access Face Recognition Project Code using Facenet in Python
System requirements :
- Install the python module as follows if the below modules are not found:
pip install pandaspip install datetime- The below codes can be run in Jupyter notebook, or any python console
Step 1: Import the module
To import
import pandas as pd
import datetime
Step 2 : Read the csv file
Read the csv file from the local and create a dataframe using pandas, and print the 5 lines to check the data.
df = pd.read_csv('employee_data.csv')
df.head()
Output of the above code:

Step 3 : Find Duplicate Rows based on all columns
In this example we are going to use the employee data set.
To find and select the duplicate all rows based on all columns call the Daraframe.duplicate()
#import modules
import pandas as pd
#reading the csv file
emp = pd.read_csv('employee_data.csv')
emp.head()
emp.columns
duplicateRowsDF = emp[emp.duplicated()]
print("Duplicate Rows except first occurrence based on all columns are :")
print(duplicateRowsDF)
Output of the above code:
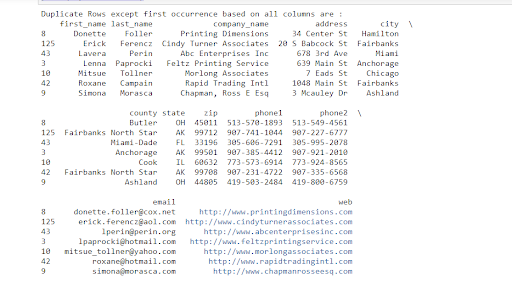
Here all duplicate rows except their first occurrence are returned because the default value of the keep argument was 'first'. If we want to select all duplicate rows except their last occurrence then we need to pass the keep argument as 'last' i.e.
duplicateRowsDF = emp[emp.duplicated(keep='last')]
print("Duplicate Rows except last occurrence based on all columns are :")
print(duplicateRowsDF)
Step 4 : Find Duplicate Rows based on selected columns
If we want to compare rows and find duplicates based on selected columns.
duplicateRowsDF = emp[emp.duplicated(['first_name'])]
print("Duplicate Rows based on a single column are:", duplicateRowsDF.head(), sep='\n')
Output of the above code:

Step 5 : Dropping duplicates from a particular column.
Here, you drop duplicates from column1. Alternatively, you can add 'keep' and indicate whether you'd like to keep the first argument (keep='first'), the last argument (keep='last') from the duplicates or drop all the duplicates altogether (keep=False). The default is 'first' so if you are happy with that, you don't need to include this.
#Dropping duplicates from a particular column
result = emp.drop_duplicates(['zip'],keep='first') #or keep = first or last
print('Result DataFrame:\n', result)
Step 6 : Delete All Duplicate Rows from DataFrame
result = emp.drop_duplicates(keep=False)
print('Result DataFrame:\n', result)
Output of the above code: It gives the data frame without duplicates as a result.

Step 7 : Sort dataframe rows on a single column
In this code below we are going to sort all the rows based on a single column.
emp = emp.sort_values(by ='zip' )
print("Contents of Sorted Dataframe based on a single column 'Zip' : ")
emp.head()
Output of the above code:

Step 8 : Sort Dataframe rows based on columns in Descending / Ascending Order
In the code below , to sort all the rows based on a column in descending or ascending order by passing a parameter ascending = False means descending order and ascending = True means ascending order.
emp = emp.sort_values(by ='zip' , ascending=False )
print("Contents of Sorted Dataframe based on a single column 'Zip' : ")
emp.head()
Step 9 : Sort Dataframe rows based on a multiple columns
In the code below sorting the data based on multiple columns
emp = emp.sort_values(by =['state','zip'])
print("Contents of Sorted Dataframe based on a multiple column 'Zip','State' : ")
emp.head()
Step 10 : Change the order and Write the csv file
After changing order of the column names, write the formatted data into a csv file in your local or hdfs.
#change order of the columns
emp = emp[['zip','first_name','last_name','company_name','email','phone1','phone2','address','city','county','state','web']]
emp.head()
emp.to_csv('newempdata.csv')
Output of the above lines:

Output of the above lines:

System requirement :
To install googletrans library run below code, this command automatically downloads and installs the library.
pip install googletrans or pip install googletrans==3.1.0a0
Importing library and reading csv file, here we are using the employee data csv file with spanish column.
import pandas as pd
spa = pd.read_csv('empdata.csv')
spa.columns
spa.columns[0]
In the above code we are reading the csv file which has the spanish column so we are going to convert into english using the googletrans library.
Output of the above code:

from googletrans import Translator
translator = Translator()
translated = translator.translate(spa.columns[0], dest='en')
print(translated)
Output of the above code:


What Users are saying..

Gautam Vermani
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic... Read More