How to Select Group By and Order By in hive?
This recipe helps you Select Group By and Order By in hive
Recipe Objective
In most of the big data scenarios, it will be required to group by the rows that have the same values and we sort the rows in ascending or descending order as required . Tables have varying number of columns and using * in the select statement will all the retrieve data but is sometimes used to mention all the column names in the select query manually. It is very hard to do because of the high number of columns. So, here our requirement is to exclude column(s) from select query in hive.
System requirements :
- Install ubuntu in the virtual machine click here
- Install single node hadoop machine click here
- Install apache hive click here
Step 1 : Prepare the dataset
Here we are using the employee related comma separated values (csv) dataset for the create hive table in local.
Data of Output looks as follows:
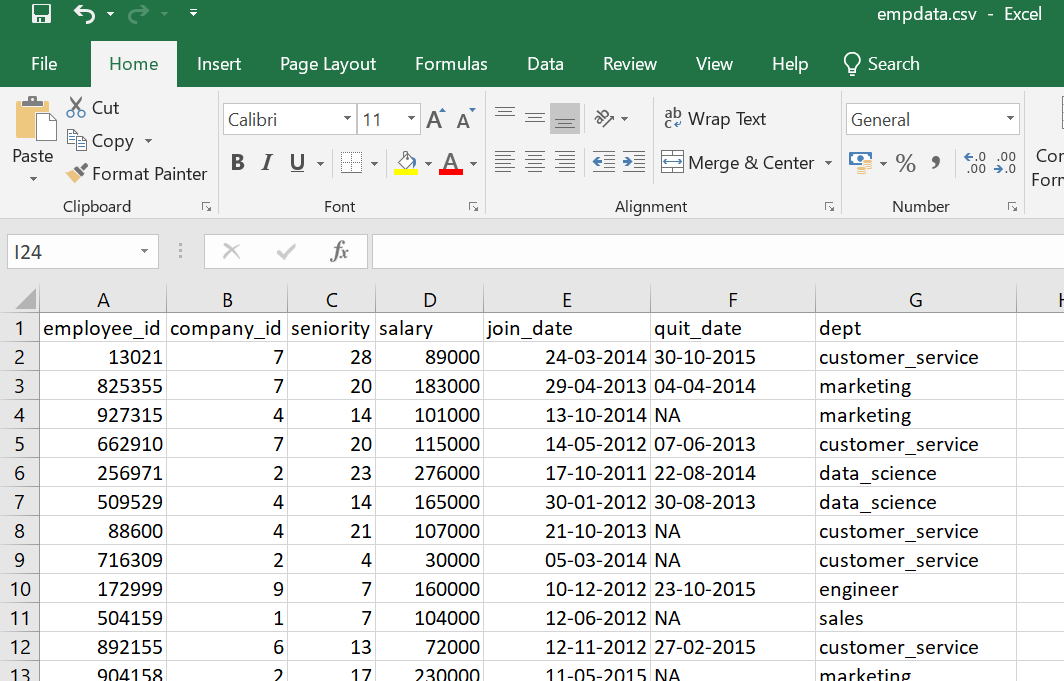
Before create a table open the hive shell and we need to create a database as follows : Open the hive shell as below

To create database using below queries :
Create database dezyre_db;
use dezyre_db;
As follows below:

Step 2 : Create a Hive Table and Load the Data into the Table and verify the Data
Here we are going create a hive table for loading the data from this table to created bucketed tables, Use below to create a hive table:
CREATE TABLE employee (
employee_id int,
company_id int,
seniority int,
salary int,
join_date string,
quit_date string,
dept string
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
the above query runs as follows :

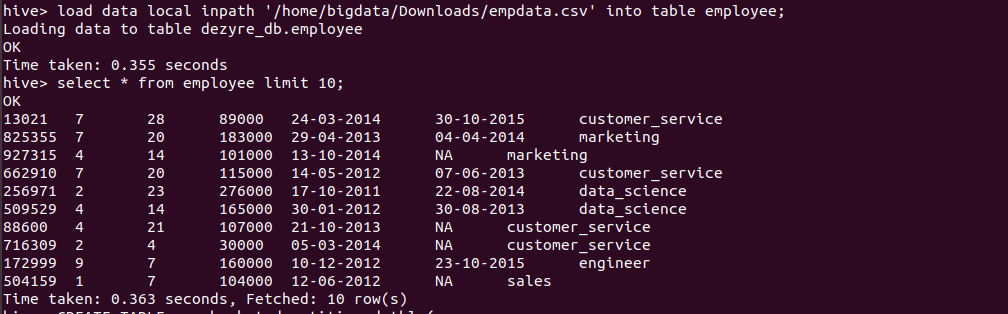
Loading the data into hive table and verifying the data
load data local inpath '/home/bigdata/Downloads/empdata.csv' into table employee;
Verifying the data by running the select query as follows
Step 3 : Group by usage in hive
The GROUP BY clause is used to group all the rows in a result set using a particular collection column. It is used to query a group of rows.
Here we are going run an example query using group by on the hive table as follows
Select dept, count(*) as countof_emp from employee group by dept ;
Output of the above query : the above query will give count of the employees in each dept as a result as below:

Step 4: Order by usage in Hive
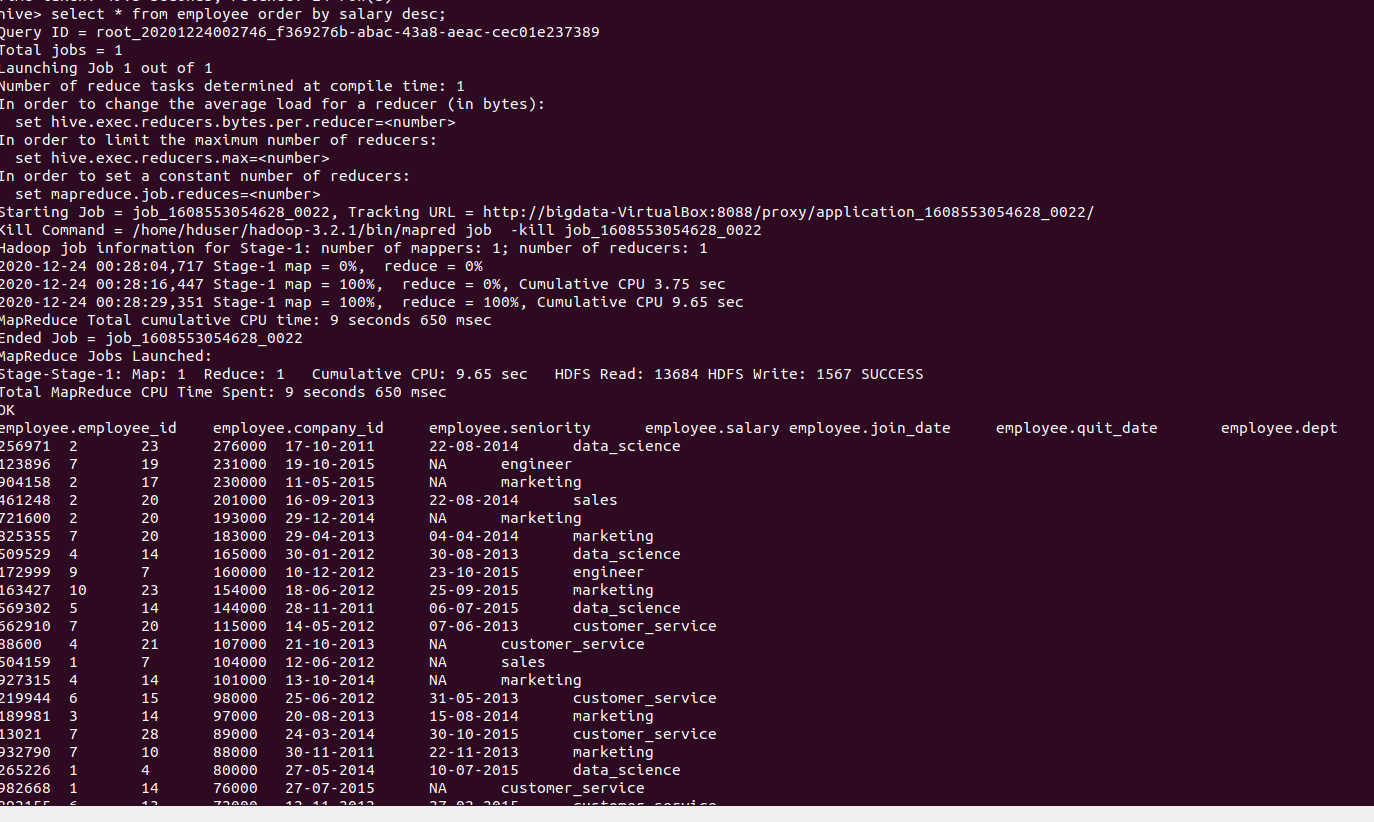
The ORDER BY is used to retrieve the rows based on one column and sort the rows set by ascending or descending order, the default order value is ascending order Here we are going run an example query using order by on the hive table as follows
Select * from employee order by salary desc;
Output of the above query: The above query give the highest salaries of the employees details in the descending order as follows below
Step 5: Excluding the column
The use of the Exclude column is when you have less columns in your data then we will use the select the column names using the select statements, but your table contains many columns ex 90 columns then that time you need to exclude a few columns in the select statement as follows:
Before going to exclude column we need to set or enable a property
hive> set hive.support.quoted.identifiers=NONE;
And also enable property to print the columns as follows
hive> set hive.cli.print.header=true;
Here we are going to use below query to excluding the quit date column as follows and also we use the regulate expression to exclude columns
hive> select `(quit_date)?+.+` from employee;
Output of the above query as follows:

We can also exclude the multiple columns using the below query as follows:
hive> select `(join_date|quit_date)?+.+` from employee;
we can use regular expressions to exclude multiple columns
Output of the above query : as we can see that excluding the join_date and quit_date


What Users are saying..

Ameeruddin Mohammed
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good... Read More