What are the types of sampling in hive ?
This recipe explains what are the types of sampling in hive
Recipe Objective
In big data scenarios , when data volume is huge, we may need to find a subset of data to speed up data analysis. Here comes a technique to select and analyze a subset of data in order to identify patterns and trends in the data known as sampling.
Hands-On Guide to the Art of Tuning Locality Sensitive Hashing in Python
System requirements :
- Install ubuntu in the virtual machine click here
- Install single node hadoop machine click here
- Install apache hive click here
Step 1 : Prepare the dataset
Here we are using the employee related comma separated values (csv) dataset for the create hive table in local.
Data of Output looks as follows:

Before create a table open the hive shell and we need to create a database as follows :Open the hive shell as below

To create database using below queries :
Create database dezyre_db;
use dezyre_db;
As follows below:

Step 2 : Create a Hive Table and Load the Data into the Table and verify the Data
Here we are going create a hive table for loading the data from this table to created bucketed tables, Use below to create a hive table:
CREATE TABLE employee (
employee_id int,
company_id int,
seniority int,
salary int,
join_date string,
quit_date string,
dept string
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
the above query runs as follows :

Loading the data into hive table and verifying the data
load data local inpath '/home/bigdata/Downloads/empdata.csv' into table employee;
Verifying the data by running the select query as follows
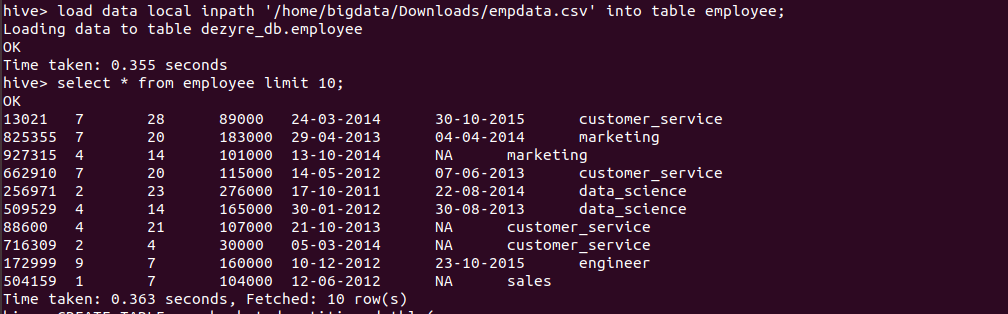
In Hive, there are three ways of sampling data: Random sampling, Bucket table sampling, and Block sampling.
Step 3 : Sampling using Random function
Random sampling uses the RAND() function and LIMIT keyword to get the sampling of data as shown in the following example. The DISTRIBUTE and SORT keywords are used here to make sure the data is also randomly distributed among mappers and reducers efficiently. The ORDER BY RAND() statement can also achieve the same purpose, but the performance is not good.
Here we are going run an example query using random funtion on the hive table as follows
hive>SELECT * FROM employee DISTRIBUTE BY RAND() SORT BY RAND()
LIMIT 10;
Output of the above query :

Step 4: Create a Bucketed table
Here we are going to create bucketed table bucket with "clustered by" is as follows
CREATE TABLE emp_bucketed_tbl_only (
employee_id int,
company_id int,
dept string,
seniority int,
salary int,
join_date string,
quit_date string
)
CLUSTERED BY (salary)
SORTED BY (salary ASC) INTO 4 BUCKETS;
the above query runs as follows
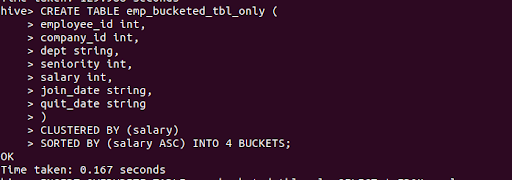
Step 5 : Load data into Bucketed table
Here we are going to insert data into the bucketed table which is without any partition:
INSERT OVERWRITE TABLE emp_bucketed_tbl_only SELECT * FROM employee;
When you load the data into the table i will performs map reduce job in the background as looks below
Output of the above query as follows:

Step 6 : Sampling using bucketing
Bucket table sampling is a special sampling optimized for bucket tables as shown in the following syntax and example. The colname value specifies the column where to sample the data. The RAND() function can also be used when sampling is on the entire rows. If the sample column is also the CLUSTERED BY column, the TABLESAMPLE statement will be more Efficient.
The below query will fetch data from the 1st bucket
hive> select employee_id, company_id,seniority,dept from emp_bucketed_tbl_only TABLESAMPLE(BUCKET 1 OUT OF 4 ON company_id);
Output of the above query :

We can specify the company_id column for sampling.The following query will produce the same result as the above query
hive> select employee_id, company_id,seniority,dept from emp_bucketed_tbl_only TABLESAMPLE(BUCKET 1 OUT OF 4 ON company_id);
Output of the above query :
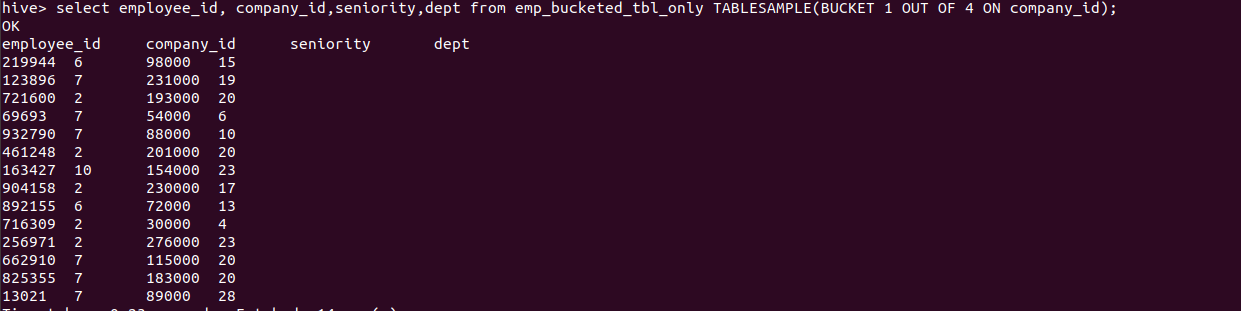
Step 7 : Block sampling in hive
Block sampling allows Hive to randomly pick up N rows of data, percentage (n percentage) of data size, or N byte size of data. The sampling granularity is the HDFS block size.
Using percent :
hive>select * from emp_bucketed_tbl_only TABLESAMPLE(20 PERCENT);
Output of the above query :

Using Rows :
hive>select * from emp_bucketed_tbl_only TABLESAMPLE(2 ROWS);
Output of the above query :


What Users are saying..

Ameeruddin Mohammed
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good... Read More