What are the types of windowing functions in hive?
This recipe explains what are the types of windowing functions in hive
Recipe Objective
In big data scenarios , when data volume is huge, we may need to find a subset of data to speed up data analysis. Here comes a technique to select and analyze a subset of data in order to identify patterns and trends in the data known as sampling.
System requirements :
- Install ubuntu in the virtual machine click here
- Install single node hadoop machine click here
- Install apache hive click here
Get Closer To Your Dream of Becoming a Data Scientist with 70+ Solved End-to-End ML Projects
Table of Contents
Step 1 : Prepare the dataset
Here we are using the employee related comma separated values (csv) dataset for the create hive table in local.
Data of Output looks as follows:
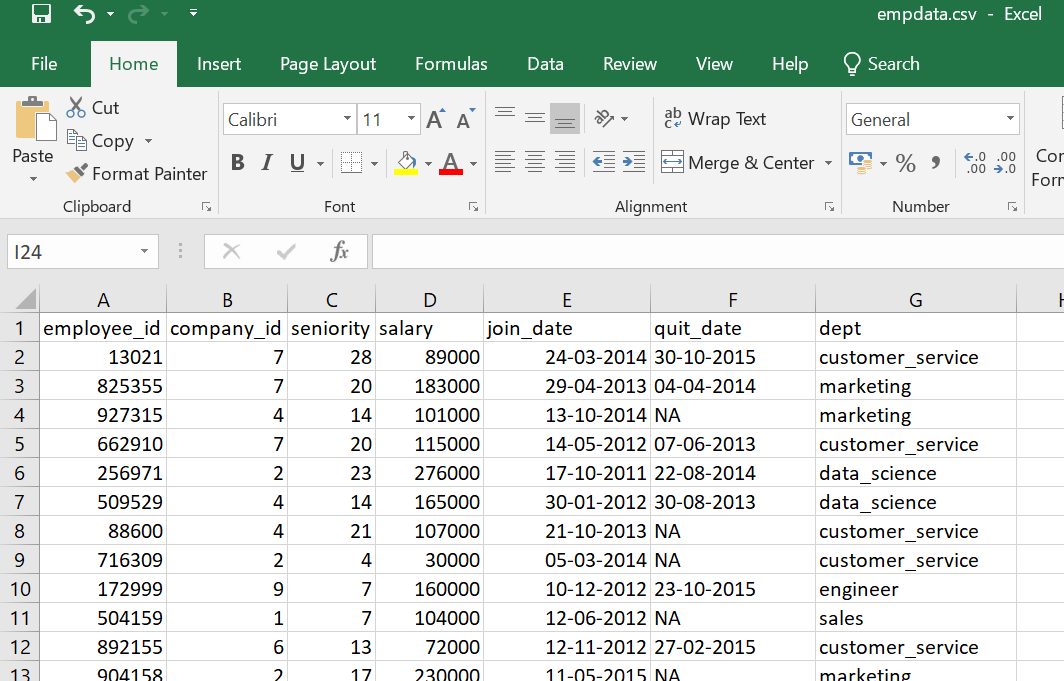
Before create a table open the hive shell and we need to create a database as follows :Open the hive shell as below

To create database using below queries :
Create database dezyre_db;
use dezyre_db;
As follows below:

Step 2 : Create a Hive Table and Load the Data into the Table and verify the Data
Here we are going create a hive table for loading the data from this table to created bucketed tables, Use below to create a hive table:
CREATE TABLE employee (
employee_id int,
company_id int,
seniority int,
salary int,
join_date string,
quit_date string,
dept string
)
ROW FORMAT DELIMITED
fields terminated by ','
TBLPROPERTIES ("skip.header.line.count"="1");
the above query runs as follows :

Loading the data into hive table and verifying the data
load data local inpath '/home/bigdata/Downloads/empdata.csv' into table employee;
Verifying the data by running the select query as follows

Step 3 : Explanation of windowing functions in hive
The use of the windowing feature is to create a window on the set of data , in order to operate aggregation like Standard aggregations: This can be either COUNT(), SUM(), MIN(), MAX(), or AVG() and the other analytical functions are like LEAD, LAG, FIRST_VALUE and LAST_VALUE.
- COUNT() function:
Here we are going to count employees in each department is as follows
hive>SELECT department, COUNT(id) OVER (PARTITION BY department) FROM employee;
Output of the above query :
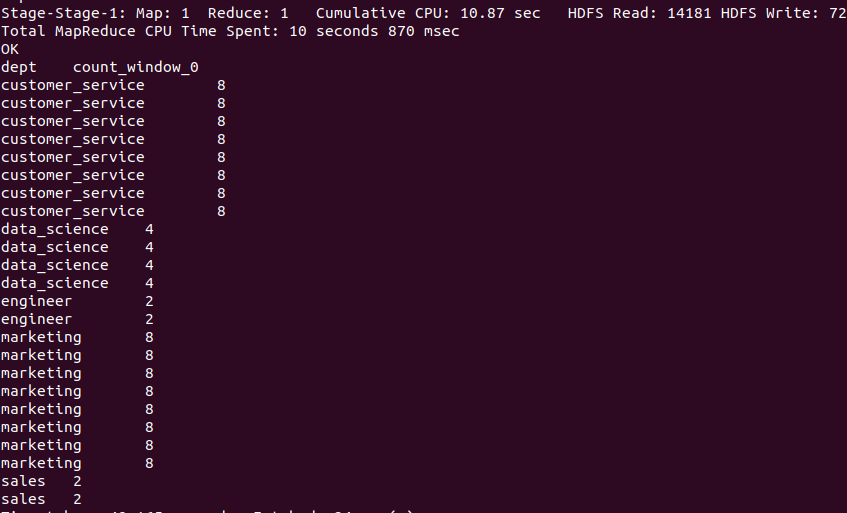
The above query gives the employee count for each department as duplicate records, so to avoid duplicate records then will use distinct in the query as follows below :
hive> SELECT DISTINCT * FROM (SELECT dept, COUNT(employee_id) OVER (PARTITION BY dept) FROM employee) as dist_count;
Output of the above query :

- MAX function:
MAX function is used to compute the maximum of the rows in the column or expression and on rows within the group.
hive> select employee_id, dept, MAX(salary) as max_sal from employee group by employee_id, dept order by max_sal desc;
the above query runs as follows

Output of the above query :

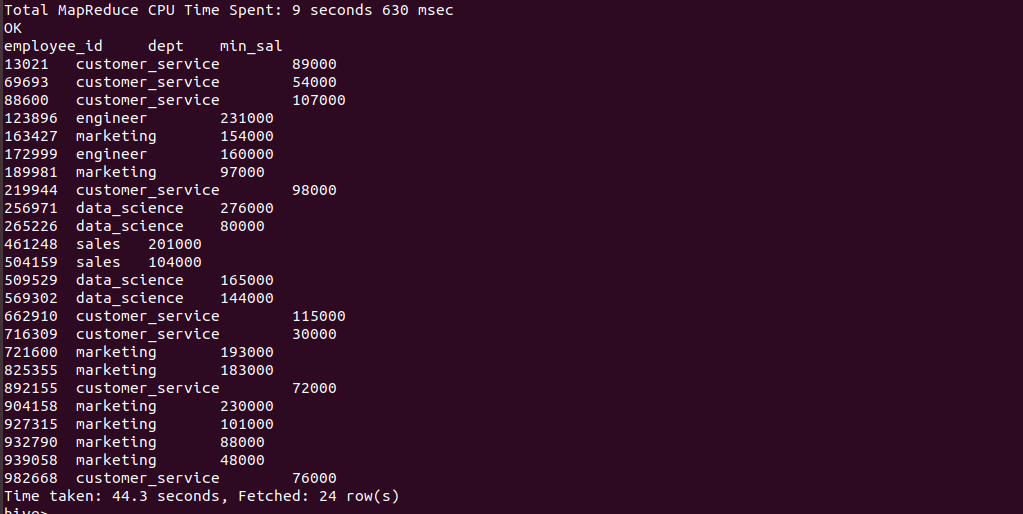
- MIN function:
MIN function is used to compute the minimum of the rows in the column or expression and on rows within the group.
hive> SELECT employee_id,dept, MIN(salary) as min_sal from employee group by employee_id;
Output of the above query :
- AVG function:
The avg function returns the average of the elements in the group or the average of the distinct values of the column in the group.
hive> SELECT AVG(salary) as avg_sal from employee where dept='marketing';
Output of the above query :

- LEAD function:
The LEAD function, lead(value_expr[,offset[,default]]), is used to return data from the next row. The number (value_expr) of rows to lead can optionally be specified. If the number of rows (offset) to lead is not specified, the lead is one row by default. It returns [,default] or null when the default is not specified and the lead for the current row extends beyond the end of the window.
hive>SELECT employee_id, company_id, seniority, dept,salary, LEAD(employee_id) OVER (PARTITION BY dept ORDER BY salary) FROM employee;
The above query runs as follows
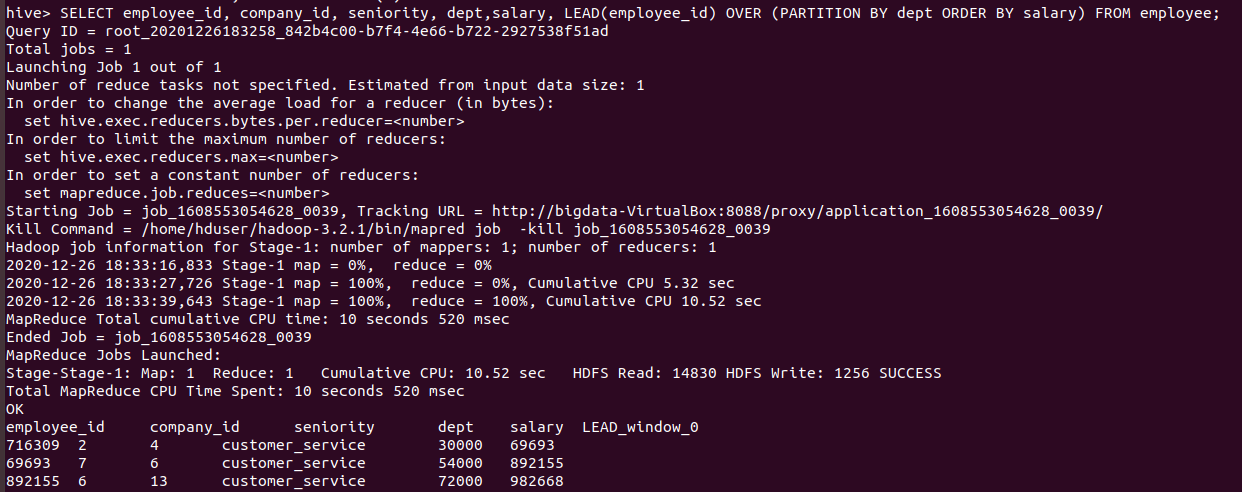
Output of the above query :

- LAG function:
The LAG function, lag(value_expr[,offset[,default]]), is used to access data from a previous row. The number (value_expr) of rows to lag can optionally be specified. If the number of rows (offset) to lag is not specified, the lag is one row by default. It returns [,default] or null when the default is not specified and the lag for the current row extends beyond the end of the window.
hive>SELECT employee_id, company_id, seniority, dept,salary, LAG(employee_id) OVER (PARTITION BY dept ORDER BY salary) FROM employee;
The above query runs as follows

Output of the above query :

- FIRST_VALUE function:
This function returns the value from the first row in the window based on the clause and assigned to all the rows of the same group, simply It returns the first result from an ordered set.
hive>SELECT employee_id, company_id, seniority, dept,salary, FIRST_VALUE(employee_id) OVER (PARTITION BY dept ORDER BY salary) FROM employee;
The above query runs as follows

Output of the above query :

Explore More Data Science and Machine Learning Projects for Practice. Fast-Track Your Career Transition with ProjectPro
- LAST_VALUE function:
In reverse of FIRST_VALUE, it returns the value from the last row in a window based on the clause and assigned to all the rows of the same group,simply it returns the last result from an ordered set.
hive>SELECT employee_id, company_id, seniority, dept,salary, LAST_VALUE(employee_id) OVER (PARTITION BY dept ORDER BY salary) FROM employee;
The above query runs as follows

Output of the above query :

Join Millions of Satisfied Developers and Enterprises to Maximize Your Productivity and ROI with ProjectPro - Read ProjectPro Reviews Now!

What Users are saying..

Anand Kumpatla
ProjectPro is a unique platform and helps many people in the industry to solve real-life problems with a step-by-step walkthrough of projects. A platform with some fantastic resources to gain... Read More