100+ Data Science in R Interview Questions and Answers for 2024
Data Science in R Interview Questions and answers for 2024, focused on R programming questions that will be asked in a data science job interview.

In our previous post for 100 Data Science Interview Questions, we had listed all the general statistics, data, mathematics and conceptual questions that are asked in the interviews. These articles have been divided into 3 parts which focus on each topic wise distribution of interview questions. Below are some of the questions that maybe asked during a data science interview, that is related to R programing specifically.

Churn Prediction in Telecom using Machine Learning in R
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectClick here to get free access to 100+ Data Science interview coding questions + solution code.

Data Science Interview Questions and Answers in R Programming
Feature |
Python is Better |
R Language is Better |
| Model Building | Both are Similar | Both are Similar |
| Model Interpretability | Not better than R. | R is better |
| Production | Python is Better | Not better than Python |
| Community Support | Not better than R. | R has good community support over Python. |
| Data Science Libraries | Both are similar. | Both are similar |
| Data Visualizations | Not better than R | R has good data visualizations libraries and tools. |
| Learning Curve | Learning Python is easier than learning R. | R has a steep learning curve. |
Ace Your Next Job Interview with Mock Interviews from Experts to Improve Your Skills and Boost Confidence!
![]()

- Explain about data import in R language (get solved code examples for hands-on experience)
R Commander is used to import data in R language. To start the R commander GUI, the user must type in the command Rcmdr into the console. There are 3 different ways in which data can be imported in R language-
• Users can select the data set in the dialog box or enter the name of the data set (if they know).
• Data can also be entered directly using the editor of R Commander via Data->New Data Set. However, this works well when the data set is not too large.
• Data can also be imported from a URL or from a plain text file (ASCII), from any other statistical package or from the clipboard.
3) Two vectors X and Y are defined as follows – X <- c(3, 2, 4) and Y <- c(1, 2). What will be output of vector Z that is defined as Z <- X*Y.
In R language when the vectors have different lengths, the multiplication begins with the smaller vector and continues till all the elements in the larger vector have been multiplied.
The output of the above code will be –
Z <- (3, 4, 4)
4) How missing values and impossible values are represented in R language?
NaN (Not a Number) is used to represent impossible values whereas NA (Not Available) is used to represent missing values. The best way to answer this question would be to mention that deleting missing values is not a good idea because the probable cause for missing value could be some problem with data collection or programming or the query. It is good to find the root cause of the missing values and then take necessary steps handle them.
5) R language has several packages for solving a particular problem. How do you make a decision on which one is the best to use?
CRAN package ecosystem has more than 6000 packages. The best way for beginners to answer this question is to mention that they would look for a package that follows good software development principles. The next thing would be to look for user reviews and find out if other data scientists or analysts have been able to solve a similar problem.
Get Closer To Your Dream of Becoming a Data Scientist with 70+ Solved End-to-End ML Projects
6) Which function in R language is used to find out whether the means of 2 groups are equal to each other or not?
t.tests ()
7) What is the best way to communicate the results of data analysis using R language? (get solved use-cases + code)
The best possible way to do this is combine the data, code and analysis results in a single document using knitr for reproducible research. This helps others to verify the findings, add to them and engage in discussions. Reproducible research makes it easy to redo the experiments by inserting new data and applying it to a different problem.
Here's what valued users are saying about ProjectPro

Ameeruddin Mohammed
ETL (Abintio) developer at IBM

Anand Kumpatla
Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd
Not sure what you are looking for?
View All Projects8) How many data structures does R language have?
R language has Homogeneous and Heterogeneous data structures. Homogeneous data structures have same type of objects – Vector, Matrix ad Array. Heterogeneous data structures have different type of objects – Data frames and lists.
9) What is the value of f (2) for the following R code?
b <- 4
f <- function (a)
{
b <- 3
b^3 + g (a)
}
g <- function (a)
{
a*b
}The answer to the above code snippet is 35. The value of “a” passed to the function is 2 and the value for “b” defined in the function f (a) is 3. So the output would be 3^3 + g (2). The function g is defined in the global environment and it takes the value of b as 4(due to lexical scoping in R) not 3 returning a value 2*4= 8 to the function f. The result will be 3^3+8= 35.
10) What is the process to create a table in R language without using external files?
MyTable= data.frame ()
edit (MyTable)
The above code will open an Excel Spreadsheet for entering data into MyTable.
Recommended Reading
- 100 Deep Learning Interview Questions and Answers
- Machine Learning Interview Questions and Answers
- Data Analyst Interview Questions and Answers
- Python Data Science Interview Questions and Answers
- Spark Interview Questions and Answers
- Data Analyst Salary 2021-Based on Different Factors
- 25 Computer Vision Engineer Interview Questions and Answers
- 50 Business Analyst Interview Questions and Answers
- 50 Statistic and Probability Interview Questions for Data Scientists
- 25 SQL Interview Questions and Answers for Data Analyst[2021]
- 50 Artificial Intelligence Interview Questions and Answers [2021]
- Prepare for your Next Machine Learning Job Interview with Commonly Asked NLP Interview Questions and Answers
- Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers
11) Explain about the significance of transpose in R language
Transpose t () is the easiest method for reshaping the data before analysis.
12) What are with () and BY () functions used for?
With () function is used to apply an expression for a given dataset and BY () function is used for applying a function each level of factors.
13) dplyr package is used to speed up data frame management code. Which package can be integrated with dplyr for large fast tables?
data.table
14) In base graphics system, which function is used to add elements to a plot?
boxplot () or text ()
15) What are the different type of sorting algorithms available in R language? (get solved use-cases + code)
Bucket Sort
Selection Sort
Quick Sort
Bubble Sort
Merge Sort
Build a fantastic Data Science Project Portfolio
15) What is the command used to store R objects in a file?
save (x, file=”x.Rdata”)
16) What is the best way to use Hadoop and R together for analysis?
HDFS can be used for storing the data for long-term. MapReduce jobs submitted from either Oozie, Pig or Hive can be used to encode, improve and sample the data sets from HDFS into R. This helps to leverage complex analysis tasks on the subset of data prepared in R.
17) What will be the output of log (-5.8) when executed on R console?
Executing the above on R console will display a warning sign that NaN (Not a Number) will be produced because it is not possible to take the log of negative number.
Recommended Reading: Deep Learning Interview Questions and Answers
18) How is a Data object represented internally in R language?
unclass (as.Date (“2016-10-05″))
19) What will be the output of the below code -
printmessage <- function (a) {
if (is.na (a))
print ("a is a missing value!")
else if (a < 0)
print ("a is less than zero")
else
print ("a is greater than or equal to zero")
invisible (a)
}
printmessage (NA)
The output for the above R programming code will be “a is a missing value.” The function is.na () is used to check if the input passed is a missing value.
20) Which package in R supports the exploratory analysis of genomic data?
adegenet
21) What is the difference between data frame and a matrix in R?
Data frame can contain heterogeneous inputs while a matrix cannot. In matrix only similar data types can be stored whereas in a data frame there can be different data types like characters, integers or other data frames.
22) How can you add datasets in R?
rbind () function can be used add datasets in R language provided the columns in the datasets should be same.
23) How do you split a continuous variable into different groups/ranks in R?
New Projects
Data Science interview coding questions + solution code
Here are some solved data science code snippets that you can use in your interviews or projects. Click on these links below to download the code for these problems. Complete list of ready-to-use solved use-cases is available here.
How to Flatten a Matrix?
How to Calculate Determinant of a Matrix or ndArray?
How to calculate Diagonal of a Matrix?
How to Calculate Trace of a Matrix?
How to invert a matrix or nArray in Python?
How to convert a dictionary to a matrix or nArray in Python?
How to reshape a Numpy array in Python?
How to select elements from Numpy array in Python?
How to create a sparse Matrix in Python?
How to Create a Vector or Matrix in Python?
How to run a basic RNN model using Pytorch?
How to save and reload a deep learning model in Pytorch?
How to use auto encoder for unsupervised learning models?​
How to create RANDOM Numbers in Python?
How to define WHILE Loop in Python?
How to define FOR Loop in Python?
How to find MIN, MAX in a Dictionary?
How to deal with Dictionary Basics in Python?
How to deal with Date & Time Basics in Python?
How to Create and Delete a file in Python?
How to convert STRING to DateTime in Python?
How to use CONTINUE and BREAK statement within a loop in Python?
How to do numerical operations in Python using Numpy?
24) What are factor variable in R language?
Factor variables are categorical variables that hold either string or numeric values. Factor variables are used in various types of graphics and particularly for statistical modelling where the correct number of degrees of freedom is assigned to them.
25) What is the memory limit in R?
8TB is the memory limit for 64-bit system memory and 3GB is the limit for 32-bit system memory.
26) What are the data types in R on which binary operators can be applied?
Scalars, Matrices ad Vectors.
27) How do you create log linear models in R language? (click here to get interview problems + solution code)
Using the loglm () function
28) What will be the class of the resulting vector if you concatenate a number and NA?
number
29) What is meant by K-nearest neighbour?
K-Nearest Neighbour is one of the simplest machine learning classification algorithms that is a subset of supervised learning based on lazy learning. In this algorithm the function is approximated locally and any computations are deferred until classification.
Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization
30) What will be the class of the resulting vector if you concatenate a number and a character?
character
31) Write code to build an R function powered by C?
32) If you want to know all the values in c (1, 3, 5, 7, 10) that are not in c (1, 5, 10, 12, 14). Which in-built function in R can be used to do this? Also, how this can be achieved without using the in-built function.
Using in-built function - setdiff(c (1, 3, 5, 7, 10), c (1, 5, 10, 11, 13))
Without using in-built function - c (1, 3, 5, 7, 10) [! c (1, 3, 5, 7, 10) %in% c (1, 5, 10, 11, 13).
33) How can you debug and test R programming code?
R code can be tested using Hadley’s testthat package.
34) What will be the class of the resulting vector if you concatenate a number and a logical? (get interview problems + solution code)
number
35) Write a function in R language to replace the missing value in a vector with the mean of that vector.
mean impute <- function(x) {x [is.na(x)] <- mean(x, na.rm = TRUE); x}
36) What happens if the application object is not able to handle an event?
The event is dispatched to the delegate for processing.
37) Differentiate between lapply and sapply.
If the programmers want the output to be a data frame or a vector, then sapply function is used whereas if a programmer wants the output to be a list then lapply is used. There one more function known as vapply which is preferred over sapply as vapply allows the programmer to specific the output type. The disadvantage of using vapply is that it is difficult to be implemented and more verbose.
38) Differentiate between seq (6) and seq_along (6)
Seq_along(6) will produce a vector with length 6 whereas seq(6) will produce a sequential vector from 1 to 6 c( (1,2,3,4,5,6)).
39) How will you read a .csv file in R language?
read.csv () function is used to read a .csv file in R language. Below is a simple example –
filcontent <-read.csv (sample.csv)
print (filecontent)
40) How do you write R commands?
The line of code in R language should begin with a hash symbol (#).
41) How can you verify if a given object “X” is a matric data object?
If the function call is.matrix(X ) returns TRUE then X can be termed as a matrix data object.
42) What do you understand by element recycling in R?
If two vectors with different lengths perform an operation –the elements of the shorter vector will be re-used to complete the operation. This is referred to as element recycling.
Example – Vector A <-c(1,2,0,4) and Vector B<-(3,6) then the result of A*B will be ( 3,12,0,24). Here 3 and 6 of vector B are repeated when computing the result.
(Get interview problems + solution code)
43) How can you verify if a given object “X” is a matrix data object?
If the function call is.matrix(X) returns true then X can be considered as a matrix data object otheriwse not.
44) How will you measure the probability of a binary response variable in R language?
Logistic regression can be used for this and the function glm () in R language provides this functionality.
45) What is the use of sample and subset functions in R programming language?
Sample () function can be used to select a random sample of size ‘n’ from a huge dataset.
Subset () function is used to select variables and observations from a given dataset.
46) There is a function fn(a, b, c, d, e) a + b * c - d / e. Write the code to call fn on the vector c(1,2,3,4,5) such that the output is same as fn(1,2,3,4,5).
do.call (fn, as.list(c (1, 2, 3, 4, 5)))
47) How can you resample statistical tests in R language?
Coin package in R provides various options for re-randomization and permutations based on statistical tests. When test assumptions cannot be met then this package serves as the best alternative to classical methods as it does not assume random sampling from well-defined populations.
48) What is the purpose of using Next statement in R language?
If a developer wants to skip the current iteration of a loop in the code without terminating it then they can use the next statement. Whenever the R parser comes across the next statement in the code, it skips evaluation of the loop further and jumps to the next iteration of the loop.
49) How will you create scatterplot matrices in R language?
A matrix of scatterplots can be produced using pairs. Pairs function takes various parameters like formula, data, subset, labels, etc.
The two key parameters required to build a scatterplot matrix are –
- formula- A formula basically like ~a+b+c . Each term gives a separate variable in the pairs plots where the terms should be numerical vectors. It basically represents the series of variables used in pairs.
- data- It basically represents the dataset from which the variables have to be taken for building a scatterplot.
50) How will you check if an element 25 is present in a vector?
There are various ways to do this-
- It can be done using the match () function- match () function returns the first appearance of a particular element.
- The other is to use %in% which returns a Boolean value either true or false.
- Is.element () function also returns a Boolean value either true or false based on whether it is present in a vector or not.
(Get interview problems + solution code)
51) What is the difference between library() and require() functions in R language?
There is no real difference between the two if the packages are not being loaded inside the function. require () function is usually used inside function and throws a warning whenever a particular package is not found. On the flip side, library () function gives an error message if the desired package cannot be loaded.
52) What are the rules to define a variable name in R programming language?
A variable name in R programming language can contain numeric and alphabets along with special characters like dot (.) and underline (-). Variable names in R language can begin with an alphabet or the dot symbol. However, if the variable name begins with a dot symbol it should not be a followed by a numeric digit.
53) What do you understand by a workspace in R programming language?
The current R working environment of a user that has user defined objects like lists, vectors, etc. is referred to as Workspace in R language.
54) Which function helps you perform sorting in R language?
Order ()
55) How will you list all the data sets available in all R packages?
Using the below line of code-
data(package = .packages(all.available = TRUE))
56) Which function is used to create a histogram visualisation in R programming language?
Hist()
57) Write the syntax to set the path for current working directory in R environment.
Setwd(“dir_path”)
58) How will you drop variables using indices in a data frame? (get interview problems + solution code)
Let’s take a dataframe df<-data.frame(v1=c(1:5),v2=c(2:6),v3=c(3:7),v4=c(4:8))
df
## v1 v2 v3 v4
## 1 1 2 3 4
## 2 2 3 4 5
## 3 3 4 5 6
## 4 4 5 6 7
## 5 5 6 7 8
Suppose we want to drop variables v2 & v3 , the variables v2 and v3 can be dropped using negative indicies as follows-
df1<-df[-c(2,3)]
df1
## v1 v4
## 1 1 4
## 2 2 5
## 3 3 6
## 4 4 7
## 5 5 8
59) What will be the output of runif (7)?
It will generate 7 randowm numbers between 0 and 1.
60) What is the difference between rnorm and runif functions ?
rnorm function generates "n" normal random numbers based on the mean and standard deviation arguments passed to the function.
Syntax of rnorm function -
rnorm(n, mean = , sd = )
runif function generates "n" unform random numbers in the interval of minimum and maximum values passed to the function.
Syntax of runif function -
runif(n, min = , max = )
Get More Practice, More Data Science and Machine Learning Projects, and More guidance.Fast-Track Your Career Transition with ProjectPro
61) What will be the output on executing the following R programming code –
mat<-matrix(rep(c(TRUE,FALSE),8),nrow=4)
sum(mat)
8
62) How will you combine multiple different string like “Data”, “Science”, “in” ,“R”, “Programming” as a single string “Data_Science_in_R_Programmming” ?
paste(“Data”, “Science”, “in” ,“R”, “Programming”,sep="_")
63) Write a function to extract the first name from the string “Mr. Tom White”.
substr (“Mr. Tom White”,start=5, stop=7)
64) Can you tell if the equation given below is linear or not ? (get interview problems + solution code)
Emp_sal= 2000+2.5(emp_age)2
Yes it is a linear equation as the coefficients are linear.
65) What will be the output of the following R programming code ?
var2<- c("I","Love,"ProjectPro")
var2
It will give an error.
66) What will be the output of the following R programming code?
x<-5
if(x%%2==0)
print("X is an even number")
else
print("X is an odd number")
Executing the above code will result in an error as shown below -
## Error: :4:1: unexpected 'else'
## 3: print("X is an even number")
## 4: else
## ^
R programming language does not know if the else related to the first ‘if’ or not as the first if() is a complete command on its own.
67) I have a string "contact@dezyre.com". Which string function can be used to split the string into two different strings “contact@dezyre” and “com” ? (get interview problems + solution code)
This can be accomplished using the strsplit function which splits a string based on the identifier given in the function call. The output of strsplit() function is a list.
strsplit("contact@dezyre.com",split = ".")
Output of the strsplit function is -
## [[1]]
## [1] " contact@dezyre" "com"
68) What is R Base package?
R Base package is the package that is loaded by default whenever R programming environent is loaded .R base package provides basic fucntionalites in R environment like arithmetic calcualtions, input/output.
69) How will you merge two dataframes in R programming language? (get interview problems + solution code)
Merge () function is used to combine two dataframes and it identifies common rows or columns between the 2 dataframes. Merge () function basically finds the intersection between two different sets of data.
Merge () function in R language takes a long list of arguments as follows –
Syntax for using Merge function in R language -
merge (x, y, by.x, by.y, all.x or all.y or all )
- X represents the first dataframe.
- Y represents the second dataframe.
- by.X- Variable name in dataframe X that is common in Y.
- by.Y- Variable name in dataframe Y that is common in X.
- all.x - It is a logical value that specifies the type of merge. all.X should be set to true, if we want all the observations from dataframe X . This results in Left Join.
- all.y - It is a logical value that specifies the type of merge. all.y should be set to true , if we want all the observations from dataframe Y . This results in Right Join.
- all – The default value for this is set to FALSE which means that only matching rows are returned resulting in Inner join. This should be set to true if you want all the observations from dataframe X and Y resulting in Outer join.
70) Write the R programming code for an array of words so that the output is displayed in decreasing frequency order.
R Programming Code to display output in decreasing frequency order -
tt <- sort(table(c("a", "b", "a", "a", "b", "c", "a1", "a1", "a1")), dec=T)
depth <- 3
tt[1:depth]
Output -
1) a a1 b
2) 3 3 2
71) How to check the frequency distribution of a categorical variable?
The frequency distribution of a categorical variable can be checked using the table function in R language. Table () function calculates the count of each categories of a categorical variable.
gender=factor(c(“M”,”F”,”M”,”F”,”F”,”F”))
table(sex)
Output of the above R Code –
Gender
F M
4 2
Programmers can also calculate the % of values for each categorical group by storing the output in a dataframe and applying the column percent function as shown below -
t = data.frame(table(gender))
t$percent= round(t$Freq / sum(t$Freq)*100,2)
| Gender | Frequency | Percent |
| F | 4 | 66.67 |
| M | 2 | 33.33 |
72) What is the procedure to check the cumulative frequency distribution of any categorical variable? (get interview problems + solution code)
The cumulative frequency distribution of a categorical variable can be checked using the cumsum () function in R language.
Example –
gender = factor(c("f","m","m","f","m","f"))
y = table(gender)
cumsum(y)
Output of the above R code-
Cumsum(y)
f m
3 3
73) What will be the result of multiplying two vectors in R having different lengths?
The multiplication of the two vectors will be performed and the output will be displayed with a warning message like – “Longer object length is not a multiple of shorter object length.” Suppose there is a vector a<-c (1, 2, 3) and vector b <- (2, 3) then the multiplication of the vectors a*b will give the resultant as 2 6 6 with the warning message. The multiplication is performed in a sequential manner but since the length is not same, the first element of the smaller vector b will be multiplied with the last element of the larger vector a.
74) R programming language has several packages for data science which are meant to solve a specific problem, how do you decide which one to use?
CRAN package repository in R has more than 6000 packages, so a data scientist needs to follow a well-defined process and criteria to select the right one for a specific task. When looking for a package in the CRAN repository a data scientist should list out all the requirements and issues so that an ideal R package can address all those needs and issues.
The best way to answer this question is to look for an R package that follows good software development principles and practices. For example, you might want to look at the quality documentation and unit tests. The next step is to check out how a particular R package is used and read the reviews posted by other users of the R package. It is important to know if other data scientists or data analysts have been able to solve a similar problem as that of yours. When you in doubt choosing a particular R package, I would always ask for feedback from R community members or other colleagues to ensure that I am making the right choice.
75) How can you merge two data frames in R language?
Data frames in R language can be merged manually using cbind () functions or by using the merge () function on common rows or columns.
76) Explain the usage of which() function in R language.
which() function determines the postion of elemnts in a logical vector that are TRUE. In the below example, we are finding the row number wherein the maximum value of variable v1 is recorded.
mydata=data.frame(v1 = c(2,4,12,3,6))
which(mydata$v1==max(mydata$v1))
It returns 3 as 12 is the maximum value and it is at 3rd row in the variable x=v1.
77) How will you convert a factor variable to numeric in R language ? (get interview problems + solution code)
A factor variable can be converted to numeric using the as.numeric() function in R language. However, the variable first needs to be converted to character before being converted to numberic because the as.numeric() function in R does not return original values but returns the vector of the levels of the factor variable.
X <- factor(c(4, 5, 6, 6, 4))
X1 = as.numeric(as.character(X))
78) Explain the significance of R programming language for Data Science ?
i) Most of the calculations can be done with the help of vector so it is easy for data scientists to add functions to a single vector without having to put them in a loop.
ii) A turning complete language that can be used for any kind of data science task whether it is in the field of genetics, statistics or biology.
iii) Being an interpreted language , it does not require any compiler-making development of code easier.
79) What is power analysis ?
Power analysis is the process used to determine the effect of a given sample size and is generally used for experimental design.Pwr package in R is used for power analysis.
80) Explain the usage of abline() function.
abline function in R used to add reference line to a graph. Below is the syntax of using abline function -
abline(h=yvalues, v=xvalues)
81) What is the usage of lattice package in R ?
Lattice package helps enhance base R graphics by providing better defaults and helps easily display multi-variate relationships.
R Interview Questions for Data Science
1) What is the need of factorizing variables in R?
When performing machine learning tasks, it is important that categorical variables like gender, countries, etc. are converted into numbers. In R, we thus use the factor function to make our categorical variables algorithm-friendly.
2) List some of your favorite functions in R programming language along with their usage.
3) Explain the differences between Python and R.
4) What is multi-threading and how can you implement it in R programming language?
5) Implement string operations in R language.
6) dplyr <- "ggplot2" library(dplyr). Which package will be loaded on executing the command and why?
Upon executing the mentioned command, the tidyverse package will be loaded as both ggplot2 and dplyr are included in the tidyverse package collection.
7) Why you should use R language for statistical work?
The programing language R is used for statistical analysis as it is an interpreted language that offers several packages that contain statistical functions.
8) What according to you are disadvantages of R Programming over Python?
- The userbase of Python is larger than that of R Programming Language. Thus, the bugs are resolved relatively quickly for Python than R.
- Certain calculations in R aren’t as quick as Python because of its syntax.
- It is not as good as Python when it comes to Data Manipulation and Data Visualization tasks.
9) Which R objects have you most frequently worked with?
10) Build a binary search tree in R language.
11) How can you produce co-relations and covariances in R lanaguge?
a <- c(1, 2, 5, 20)
b <- c(2, 3, 6, 10)
print(cor(x, y))
#For Covariance
a <- rnorm(2)
b <- rnorm(2)
mat <- cbind(x, y)
A <- cov(mat)
print(A)
print(cor(mat))
#Converting covariance matrix to correlation matrix using function cov2cor()
print(cov2cor(X))
12) How can you develop a package in R language and do version control?
This list of 100 data science interview questions is not an exhaustive one and we know that we have not gotten all the answers here. We request the data science community to help us out with the questions that we did not get the answers to. Please do chime in with any data science interview questions related to R programming that you think ought to be here. We will add it in.
13) List a few string manipulation functions in the R language.
Here a few functions available in R Language that allow string manipulation:
- nchar()
- grep()
- paste()
- substr()
- strsplit()
- gregexpr()
- regex()
- sprintf()
82) How will you save the output of an R plot?
To create a pdf, you can use the pdf() function, and if one wishes to save the plot in jpeg format, they can use the jpeg() function.
83). Suppose you have a dataset ‘CallRecords.csv’ that contains the two columns: ‘dur_min’ and ‘balance’. How will you plot a graph of the two variables?
>CR = red.table(“CallRecords.csv”)
>plot(CR$dur_min, CR$balance)
OR
>attach(CR)
>plot(dur_min,balance)
The key point to remember is that to refer to a variable in R, we are required to type the dataset and the variable name joined with a $ symbol as R does not know to look for the variables in the dataset automatically.
84) Write the code to implement linear regression over all the variables of a dataset ‘d’ except one of the variables, ‘age’ to predict the value of variable ‘y’.
>library(MASS)
>lm.fit1=lm(y~.-age,data=d)
In R, a special identifier exists that one can use in a formula to mean all the variables, it is the ‘.’ identifier.
85) What do (principal) diagonal and non diagonal elements of a confusion matrix printed using table() function in R represent?
The diagonal elements of the confusion matrix represent correct predictions for a given target variable while the non-diagonal elements represent incorrect predictions.
86) How many inputs does knn() function of the class library in R require? Explain each of them briefly.
The knn() function requires following four inputs:
-
A matrix that consists of feature values from the training data.
-
A matrix that consists of feature values from testing data, for which we want to make predictions.
-
A vector that contains target values or class labels for the training data.
-
A value of K that specifies the number of nearest neighbors to be used by the algorithm.
87) Consider a dataset named “Vehicles” that has a part of its observations contained in a sample named test. How will you use lm() to fit a linear regression model to the observations that belong to this subset?
lm.fit((x~y, dat Vehicles, subset = test)
88) What is the use of the set.seed() function?
The set.seed() function is used by R programmers to set a seed for the language’s random number generator. This means that the function will allow users to reproduce the same results as observed by someone who uses the same code even if they have used a random number generator in their code.
89) If you use glm() function to fit a model without providing a value for the family argument, which regression model will be used by the R Programming language?
The model used by the language will be the linear regression model and the function glm() will perform in the same manner as the lm() functions.
90) Which library has the cross-validation function cv.glm()?
The Boot library.
91) Write the code to remove rows that contain missing values for any variable in the dataset ‘Hello.csv’.
Assuming that we are working the correct directory which contains ‘Hello.csv’, the following code should work:
Hello = read.table(“Hello.csv”)
Hello = na.omit(Hello)
92) What criteria does regsubsets() function of the ‘leaps’ library use to perform best subset selection?
Ans: The function regsubsets() evaluates the best subset selection by choosing the best model that has a given number of feature variables, where best is quantified using the residual sum-of-squares (RSS).
93) Which function is used to perform both ridge regression and lasso regression? By default, which regression does it perform?
Both ridge regression and lasso regression can be performed using the function glmnet() of the glmnet package. By default, the glmnet() function performs ridge regression for a predefined range of λ values.
94) What does setting the argument TRUE for the scale variable of pcr() function do?
On setting the value of scale as TRUE, we will observe that each feature variable will be standardized or normalized, before evaluating the principal components. This is done so that scale of each feature variable can be ignored while analyzing the significance of each one.
95) What does the percentage of variance for different datasets prepared by selecting different numbers of components using Principal Component Analysis (PCA) reflect?
The percentage variance for different datasets prepared through PCA reflects the amount of information about the feature variables or the target variable that has been conveyed by selecting N number of principal components.
For example: Given a dataset, we observe
N=1 conveys 40% of all the variance,
N=4 conveys 80% of all the variance,
And N= total number of feature variables conveys 100% of the variance as the full dataset has been covered.
96) Given a decision tree in R, ‘tree.vehicles’, how will you display the tree in R?
We can use plot() function to visualize the structure of the decision tree. Along with this function, we can use text() function to show the node labels. And if we set pretty=0, we can also see full category names of any qualitative feature variable instead of just displaying an initial for each category.
Code:
plot(tree.vehicles)
text(tree.vehicles,pretty=0)
97) When you print the summary() for a classification decision tree, you will notice a parameter ‘deviance’. What is it and what does it denote?
Deviance is a metric for estimating the performance of a classification decision tree. It is given by,
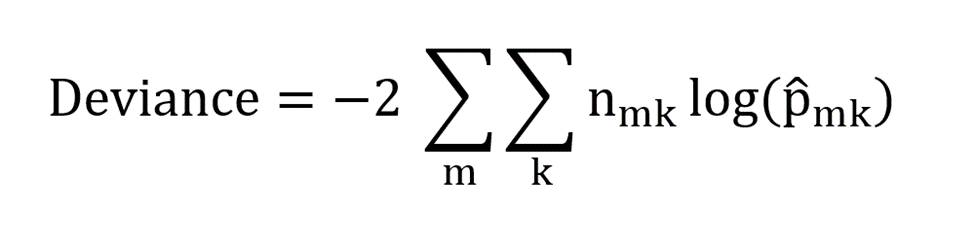
where nmk is the number of observations in the mth terminal node that belongs to the kth class.
98) Can the random forest function be used for both bagging and random forests? If yes, how?
Yes, the random forest function can be used for both bagging and random forests by setting the values for the parameter mtry.
99) How are node impurity measures different for classification decision trees and regression decision trees?
For classification decision trees, the node impurity is evaluated using Residual sum-of-squares and the node impurity of regression decision trees is evaluated using deviance.
100)Which library of R contains the Support Vector Classifier?
The library e1071 has the function svm() that can be used to implement the Support Vector Classifier by setting the argument kernel=”linear”.
101) What is the cost argument for a Support Vector Classifier?
A cost argument is a tool for specifying the cost of a violation to the margin. When the cost argument takes a small value, the margins for the classifier are wide and several support vectors lie on the margin or violate the margin. When the cost argument takes a large value, then the margins for the support vectors are narrow, and very few support vectors are on the margin or violate the margin.
102) What happens when we set the argument “scale=FALSE” for the svm() function?
The argument “scale=FALSE” ensures that the function does not scale each feature variable in a way that they have mean zero or standard deviation one. If one wants their feature variables scaled in this manner, then they should use “scale=TRUE”.
103) Which function of the e1071 library is used to perform cross-validation for the Support Vector Classifier? How many folds are there by default for cross-validation?
The function tune() of the e1071 library is used to perform cross-validation. By default, it performs ten-fold cross-validation on a given dataset.
104) How will you implement Support Vector Machine in R? Explain for both radial and polynomial kernel.
Using the svm() function of the e1071 library, we can implement a support vector machine (SVM) in R. It has a parameter kernel that we can set the values for to use SVM with a polynomial or radial kernel. For using the SVM with a polynomial kernel, we set kernel=”polynomial” and for using the SVM with a radial kernel, we set kernel=”radial”. For the former case, we specify the degree of a polynomial by providing the value of the degree argument and for the latter case, we specify the value for γ for the radial basis kernel by providing the value for the gamma argument.
105) Write the code to print the mean of the feature variables for the USArrests data which is a part of the base R package.
apply(USArrests, 2, mean)
The second input to the function has been used to specify that the mean has to be evaluated column-wise.
106) What is the significance of the “nstart” argument for the kmeans() function?
The nstart argument for the kmeans() function allows us to run the K-means clustering algorithm with multiple initial cluster assignments. If the argument nstart is provided with a value greater than one, then the K-means clustering will be performed using multiple random assignments, and the function kmeans() will display only the best results. It is thus always recommended to use a large value for the nstart argument as otherwise, an undesirable local optimum may be obtained.
107) How will you make sure that the results that you have obtained using the K-means clustering algorithms are reproducible?
Ans: To ensure reproducible results, we will set a random seed using the set.seed() function.
R Programming Interview Questions
108. What is the difference between a factor and a character variable in R? How would you convert a character variable to a factor variable?
109. How would you handle missing values in R? Explain the functions and techniques you would use to handle missing data.
110. Explain the concept of function closures in R and provide an example of their usage.
111. What are the differences between the "==" and "===" operators in R?
112. What is the purpose of the apply() function in R? Provide an example of how you would use it.
113. How can you generate random numbers in R? Explain the difference between the "runif()" and "rnorm()" functions.
114. What are the advantages and disadvantages of using R for machine learning compared to other programming languages like Python?
115. What is the purpose of the "dplyr" package in R? How does it differ from base R functions for data manipulation?
116. Explain the concept of vectorization in R. Why is it important, and how does it improve performance?
117. How would you plot multiple graphs on the same page in R? Explain the functions or packages you would use to achieve this.

About the Author

ProjectPro
ProjectPro is the only online platform designed to help professionals gain practical, hands-on experience in big data, data engineering, data science, and machine learning related technologies. Having over 270+ reusable project templates in data science and big data with step-by-step walkthroughs,