How to Fine Tune LLMs?
Explore the nuts and bolts of fine tuning LLMs in this comprehensive guide.

Hop on to the train of our blog that will take you on a journey through the intricacies of fine-tuning Large Language Models (LLMs). Explore methodologies, tools, and a step-by-step tutorial using OpenLLaMA-7B and QLoRA. Uncover the nuances of LLM fine-tuning and gain insights into its benefits and challenges.

LLM Project to Build and Fine Tune a Large Language Model
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectThe buzz around AI chatbots like ChatGPT, Google Bard, Google Gemini, and others have captured the attention of users worldwide. The secret to the conversational potential of these chatbots lies in the incredible capability of large language models (LLMs). Large language models, trained on massive datasets, stand out as game-changers in natural language processing. GPT-3, for instance, has undergone extensive pre-training on a wide array of text, enabling it comprehensively to grasp the nuances of language and context. The sheer scale of data these models process empowers them with a remarkable ability to comprehend and generate coherent and contextually relevant responses. However, the true magic happens when we dive into the ocean of fine-tuning these LLMs.
Table of Contents
What is Fine-Tuning in LLMs?
Fine-tuning is the process of adapting a pre-trained language model to specific tasks or datasets. In the context of LLMs, it involves exposing the model to task-related examples and adjusting its parameters, aligning its vast pre-existing knowledge with the intricacies of the targeted domain. The significance of fine-tuning LLMs lies in its ability to unlock the full potential of these models for specialized applications. While pre-trained LLMs offer a foundation of general knowledge, fine-tuning tailors them to address specific needs. This adaptability saves time and computational resources and ensures that these models deliver precise and contextually relevant outcomes. Here is an exciting post by Devansh to motivate your interest in learning about LLM fine-tuning.

In the upcoming sections of this blog, we'll explore the nuances of fine-tuning LLMs, unraveling the steps involved, and showcasing its transformative impact on the capabilities of these large language models. Together, let us uncover the intricacies of maximizing the AI chatbots’ potential through the art of fine-tuning. But before we dive into the deets of fine-tuning, allow us to clear a common misconception about the difference between fine-tuning LLMs and embeddings.

LLM Fine Tuning vs Embedding
Fine-tuning Large Language Models (LLMs) and utilizing embeddings are two strategies to enhance language understanding in natural language processing. Fine-tuning adapts pre-trained models for specific tasks, while embeddings represent words as vectors to capture semantic relationships. Here's a concise comparison:
|
Aspect |
LLM Fine-Tuning |
Embeddings |
|
Definition |
Adapting pre-trained models for task-specific proficiency. |
Vector representations capturing semantic ties. |
|
Process |
Exposure to task examples, adjusting for domain alignment. |
Mapping words into vectors based on context. |
|
Advantages |
Leverages pre-existing general knowledge for adaptation. |
Captures semantic relationships between words. |
|
Applications |
Tailored for specific tasks like sentiment analysis. |
Widely used for various NLP tasks and embeddings. |
|
Efficiency |
Quick solution for specific tasks without extensive training. |
Efficient for semantic similarity and related tasks. |
Thus, LLM fine-tuning customizes models for specific tasks, while embeddings provide versatile vector representations, each catering to distinct needs in natural language processing. Let us now explore a few methods to fine-tune LLMs.
New Projects
Fine-tuning Methods for LLMs
Explore the magic of fine-tuning Large Language Models (LLMs) in this section – from smart shortcuts like Repurposing to Simple Fine-Tuning's efficiency, Reinforcement Learning from Human Feedback's sophistication, and Parameter-Efficient Fine-Tuning's innovation with Low-Rank Adaptation (LoRA).
Repurposing
Repurposing is a clever way to make Large Language Models (LLMs) work on tasks they weren't initially designed for, like using a text generation model for sentiment analysis. It's less complex than fine-tuning but may not reach the same performance level.
To repurpose an LLM, you pick out the essential parts of your data for the new task. Then, you connect the LLM to a classifier model, which helps the model learn how these crucial parts relate to your desired output. Repurposing is more straightforward and uses less computer power than complete fine-tuning. However, it might not be as good at the new task as a model explicitly trained for that job. Repurposing is thus like an intelligent shortcut, allowing LLMs to handle different tasks without the complex computational work of complete fine-tuning.
Here's what valued users are saying about ProjectPro

Abhinav Agarwal
Graduate Student at Northwestern University

Ameeruddin Mohammed
ETL (Abintio) developer at IBM
Not sure what you are looking for?
View All ProjectsSimple Fine-Tuning (SFT)
Simple Fine-Tuning (SFT) is a key supervised fine-tuning technique for Large Language Models (LLMs), offering a pathway to enhance the model's performance in specific domains or tasks. SFT typically spans one to three epochs, utilizing a cosine learning rate scheduler alongside a teacher model. This brief yet focused training allows the model to adapt swiftly and efficiently to the nuances of the desired domain.
SFT's effectiveness is further amplified when combined with other techniques like Distilled Supervised Fine-Tuning (dSFT) and Parameter-Efficient Fine-Tuning (PEFT). These collaborations aim to refine and optimize the model's performance beyond the capabilities of standalone SFT. SFT proves particularly useful when a model needs customization for specific datasets or tasks, ensuring compliance with data requirements or addressing rare scenarios. However, it may not be necessary if the model already fits the intended task or if the data is constantly changing.
Reinforcement Learning from Human Feedback (RLHF)
Taking language model customization to a sophisticated level, some data scientists use Reinforcement Learning from Human Feedback (RLHF) as a powerful fine-tuning technique, as suggested in this post by Mrinal Sinha.

This process transcends Simple Fine-Tuning (SFT) or instruction-based approaches but demands substantial technical and financial resources, limiting its accessibility to large companies and AI labs. Initially, an LLM, like GPT-3 in the case of ChatGPT, undergoes training on vast datasets, generating coherent but not necessarily task-specific outputs. RLHF intervenes to align the model's responses with user requirements. Human reviewers assess the model's outputs on specific prompts, offering ratings that serve as signals for fine-tuning. This iterative process creates a refined language model that caters more precisely to desired outcomes.
ChatGPT, a notable RLHF example, underwent a multi-step process. First, a GPT-3.5 model was fine-tuned using SFT on manually generated prompts. Next, human reviewers rated the model's outputs on diverse prompts. This human feedback data constructed a reward model, mirroring human preferences. Finally, the language model underwent deep reinforcement learning, optimizing its parameters based on generated outputs, reward model ratings, and a quest for maximum reward. While RLHF remains complex and resource-intensive, its implementation, as seen in ChatGPT, demonstrates how human-guided fine-tuning can enhance language models beyond their initial capabilities, pushing the boundaries of AI language understanding.
Learn about the significance of R programming language wirh these data science projects in R with source code.
Parameter-Efficient Fine-Tuning (PEFT)
Reducing the number of parameters in a model can be a smart move to save memory and boost efficiency. Imagine having an extensive toolbox but only using the tools you need. This idea is at the core of Parameter-Efficient Fine-Tuning (PEFT), a set of techniques designed to make tweaking large language models (LLMs) more efficient. Various strategies fall under the umbrella of PEFT, and one notable approach gaining traction, particularly in open-source language models, is Low-Rank Adaptation (LoRA). LoRA challenges the notion that fine-tuning a foundational model on a specific task necessitates updating all of its parameters. Instead, it identifies a low-dimension matrix capable of accurately representing the downstream task's space.
During fine-tuning with LoRA, this low-rank matrix is trained, bypassing the need to update the main LLM parameters extensively. The weights of the LoRA model are then integrated into the primary LLM or added during inference. This innovative technique can drastically reduce fine-tuning costs by up to 98 percent. Additionally, LoRA facilitates the storage of multiple small-scale fine-tuned models that can be seamlessly incorporated into the LLM at runtime. Parameter-efficient fine-tuning, involving techniques like LoRA, not only addresses cost concerns but also opens avenues for creating more versatile and adaptable language models. As research progresses, PEFT promises to play a pivotal role in optimizing the efficiency of LLM fine-tuning processes.
Instruction Fine-Tuning
Instruction Fine-Tuning involves training the Large Language Model (LLM) on a particular task or dataset to boost its performance in that area. It is like giving the model specific lessons where it learns to generate responses tailored to the task. It's a bit like a teacher guiding a student with examples of what's expected as input and the desired output for that task.
Adaptive Fine-Tuning
Adaptive Fine-Tuning takes fine-tuning a step further. Before getting specific about a task, the LLM undergoes additional fine-tuning on extra data. This extra step helps the model adjust to the unique features of new data or domains. It's like a warm-up before the main exercise, making the LLM more adaptable and potentially leading to better performance when fine-tuned for the actual task.
Behavioral Fine-Tuning
Behavioral Fine-Tuning focuses on teaching the LLM specific behaviors by fine-tuning it with labeled data related to a particular task. Instead of just learning the task, the model aims to understand and replicate specific behaviors or responses relevant to that task. It's like coaching the model on how to behave in a way that improves its performance in generating task-specific content.
Retrieval augmented generation (RAG)
Retrieval-augmented generation (RAG) is a fine-tuning method tailored for Large Language Models (LLMs), aiming to enrich responses by incorporating external information for improved relevance and depth. Unlike traditional fine-tuning, RAG is a more efficient approach, sidestepping the need for extensive retraining on large labeled datasets. RAG's efficiency thus shines particularly in scenarios where obtaining labeled data is challenging or costly. It excels in tasks where additional context alone isn't sufficient, providing a transparent mechanism that offers more precise insights into the model's decision-making process.
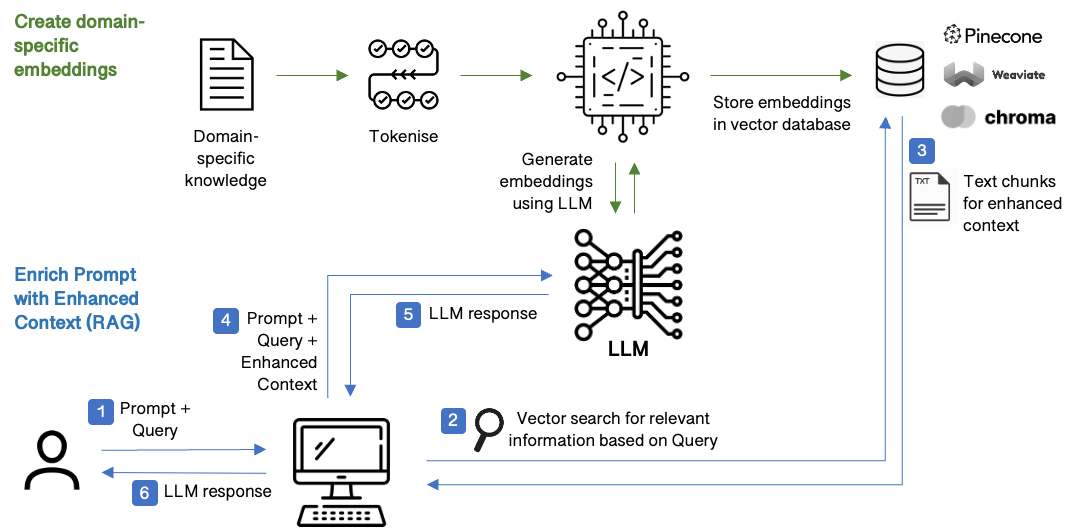
Several factors come into play when deciding between RAG and fine-tuning for an LLM. These include the complexity of the task, the availability of task-specific data, the need for current and proprietary information, and the efficiency and transparency of the chosen approach. RAG is highly recommended for tasks where interpretability, up-to-date responses, and preventing hallucinations are critical. Its transparent nature makes it a preferred choice in such scenarios. However, fine-tuning may prove more suitable if the task demands the model to learn intricate patterns and relationships.
As we dive into fine-tuning methods for LLMs, the excitement doesn't end there. Let's uncover the remarkable advantages of fine-tuning these language models to suit your needs perfectly.
Benefits of Fine-tuning LLMs
Fine-tuning Large Language Models (LLMs) on your data presents a fantastic set of advantages, making it a powerful technique in natural language processing. Here are some key benefits:
-
Capturing Rich Semantic Data
Fine-tuning allows LLMs to capture and adapt to the rich semantic bits of specific tasks or domains. Exposing the model to task-specific examples refines its understanding, enabling it to generate more contextually relevant and accurate responses.
-
Versatility for Many NLP Activities
One of the remarkable strengths of fine-tuning is its versatility. LLMs, pre-trained on diverse datasets, can be fine-tuned for various Natural Language Processing (NLP) activities. From sentiment analysis and summarization to more specialized tasks like legal document analysis, fine-tuning tailors the model's capabilities to diverse applications.
-
Requires Fewer Computational Resources
Fine-tuning requires fewer computational resources than training a language model from scratch. The initial pre-training phase imparts a general understanding of language to the model. Fine-tuning builds upon this foundation, optimizing the model for specific tasks without extensive resources.
-
Generalizes Well to Unknown Data
Fine-tuned LLMs often showcase a robust ability to generalize well to previously unseen or unknown data. The knowledge acquired during pre-training, coupled with task-specific fine-tuning, equips the model to handle a broad spectrum of inputs, contributing to its adaptability in real-world scenarios.
Fine-tuning LLMs is a cost-effective and versatile strategy that enhances their performance across various NLP projects. From capturing intricate semantics to efficient resource utilization and adaptability to unknown data, fine-tuning emerges as a crucial technique in unleashing the full potential of large language models.
Challenges and Limitations of Fine-tuning LLMs
While fine-tuning LLMs is a potent method for enhancing performance, it is not without its challenges and limitations, which include the following:
-
Bias and Fairness
Fine-tuning LLMs may inadvertently produce biased or unfair outputs, reflecting societal prejudices in the training data. To mitigate this, debiasing techniques and a comprehensive evaluation using quantitative metrics and human assessment are crucial.
-
Hyperparameter Tuning
The fine-tuning process involves adjusting various hyperparameters that govern the model's behavior, such as learning rates and batch sizes. Mastering hyperparameter tuning poses a challenge, requiring meticulous adjustments to achieve optimal performance.
-
Catastrophic Forgetting
Fine-tuning can significantly alter learned representations, causing the model to forget knowledge gained during pre-training. Techniques like Elastic Weight Consolidation are employed to address this issue and preserve previous learning.
-
Limited Data
Fine-tuning necessitates a substantial amount of labeled data. When data are scarce, achieving good results through fine-tuning becomes challenging, impacting the model's effectiveness.
-
Data Drift
Constant changes in the data the LLM encounters pose a challenge for fine-tuning, particularly for tasks like machine translation. The model may struggle to keep up with evolving data, affecting its performance.
Organizations can adopt best practices to tackle these challenges, including incorporating debiasing techniques, creating neutral prompts, and employing a combination of quantitative metrics and human evaluation. Additionally, carefully considering when to use fine-tuning is essential to maximize efficiency. Now, let's look at the valuable tools for fine-tuning LLMs.
Tools for Fine-tuning LLMs
Fine-tuning Large Language Models (LLMs) is made more accessible and efficient with various tools and techniques. Here are some notable options:
1. Hugging Face Transformers Library
Hugging Face's Transformers Library is a comprehensive resource offering various pre-trained models and tools designed explicitly for fine-tuning LLMs on distinct tasks and datasets.
2. Llama Factory
An open-source tool on GitHub, Llama Factory provides a user-friendly interface for fine-tuning LLMs. It simplifies the process, making it accessible for users aiming to adapt models to specific requirements.
3. Axolotl
While lacking a graphical user interface, Axolotl is known for its efficiency in the fine-tuning process. It is a robust tool for organizations and individuals looking for effective fine-tuning solutions.
4. H2O LLM Studio
H2O LLM Studio offers a framework and a no-code GUI, providing users with a user-friendly interface for the fine-tuning process. It simplifies the customization of LLMs without the need for extensive coding.
5. Databricks
Databricks, a cloud-based data analytics platform, offers tools for fine-tuning LLMs. They offer an LLMOps stack comprised of various components facilitating the fine-tuning process.
6. Lakera
Lakera, a company specializing in tools and services for fine-tuning LLMs, provides a valuable Prompt Engineering Guide. This guide offers effective strategies for guiding the model's thought process, enhancing its adaptability.
These tools cater to diverse user preferences, offering options from user-friendly interfaces to efficient fine-tuning processes. Whether you seek simplicity or advanced functionality, these tools empower organizations and individuals to adapt LLMs effectively to specific tasks and domains. After learning so much about fine-tuning LLMs, you are now likely to be curious about learning the art from fine-tuning LLM tutorials. So, let us explore one such example in the next section.
Fine Tuning LLM Tutorial: OpenLLaMA-7B with QLoRA
This tutorial involves customizing LLMs for specific needs. It will guide you on leveraging powerful base models, like OpenLLaMA-7B, and QLoRA, an accessible fine-tuning algorithm. QLoRA builds upon LoRA by introducing quantization to a 4-bit format during training. This innovation optimizes GPU memory usage, allowing for fine-tuning with a smaller footprint.
The setup in this tutorial involves choosing OpenLLaMA-7B, selecting a suitable dataset, and opting for QLoRA to fine-tune the model. The tutorial simplifies vital concepts such as LoRA's weight adaptation, making it ideal for users with regular GPUs.
Prerequisites
Before we begin, make sure you have the necessary libraries installed. You can install them by downloading this requirements.txt file and then using the following command:
pip install -r requirements.txt
Also, download all the other relevant files from this fine-tune LLM GitHub repository of George Sung.
Step 1: QLoRA Configuration
To understand the code implementation from the GitHub repository, you need to thoroughly go through the QloraTrainer.py file, which manages the language model's loading, training, and saving.
The code starts with the definition of QloraTrainer class as mentioned below:
class QloraTrainer:
def __init__(self, config: dict):
self.config = config
self.tokenizer = None
self.base_model = None
self.adapter_model = None
self.merged_model = None
self.data_processor = None
The __init__ method initializes the trainer with a configuration dictionary (config). It sets up attributes to store the tokenizer, base model, adapter model, merged model, and data processor.
def load_base_model(self):
model_id = self.config["base_model"]
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
if "model_family" in self.config and self.config["model_family"] == "llama":
tokenizer = LlamaTokenizer.from_pretrained(model_id)
model = LlamaForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
else:
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
if not tokenizer.pad_token:
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
self.tokenizer = tokenizer
self.base_model = model
Next, the load_base_model method loads the base language model specified in the configuration (config["base_model"]). It checks if the model family is "llama" and, if so, uses the LlamaTokenizer and LlamaForCausalLM classes; otherwise, it uses AutoTokenizer and AutoModelForCausalLM. The BitsAndBytesConfig is used to configure quantization settings.
Special tokens, such as the padding token [PAD], are added to the tokenizer if not already present. Gradient checkpointing is enabled for more efficient training, and the tokenizer and base model are stored in the class attributes.
def load_adapter_model(self, adapter_path: str):
""" Load pre-trained lora adapter """
self.adapter_model = PeftModel.from_pretrained(self.base_model, adapter_path)
The load_adapter_model method loads a pre-trained adapter model specified by adapter_path.
It utilizes the PeftModel class to load the adapter model from the specified path.
def train(self):
# Set up lora config or load pre-trained adapter
if self.adapter_model is None:
config_dict = self.config["lora"]
config = LoraConfig(
r=config_dict["r"],
lora_alpha=config_dict["lora_alpha"],
target_modules=config_dict["target_modules"],
lora_dropout=config_dict["lora_dropout"],
bias=config_dict["bias"],
task_type=config_dict["task_type"],
)
model = get_peft_model(self.base_model, config)
else:
model = self.adapter_model
self._print_trainable_parameters(model)
# ... (Training setup and execution)
The train method initiates the training process. It checks if an adapter model is loaded and creates a new model using the provided LoraConfig settings. The method then prints the number of trainable parameters using the _print_trainable_parameters private method. The data preprocessing is set up, and the model is trained using the Hugging Face Trainer class.
def merge_and_save(self):
""" Merge base model and adapter, save to disk """
# Cannot merge when base model loaded in 8-bit/4-bit mode, so load separately
model_id = self.config["base_model"]
if "model_family" in self.config and self.config["model_family"] == "llama":
base_model = LlamaForCausalLM.from_pretrained(model_id, device_map="cpu")
else:
base_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cpu")
adapter_save_path = f"{self.config['model_output_dir']}/{self.config['model_name']}_adapter"
model = PeftModel.from_pretrained(base_model, adapter_save_path)
self.merged_model = model.merge_and_unload() # note it's on CPU, don't run inference on it
model_save_path = f"{self.config['model_output_dir']}/{self.config['model_name']}"
self.merged_model.save_pretrained(model_save_path)
self.tokenizer.save_pretrained(model_save_path)
The merge_and_save method merges the base model and the adapter model (if any) and saves the resulting model to disk. It first loads the base model separately to avoid issues with loading in 8-bit/4-bit mode. The adapter model is loaded using PeftModel. The merge_and_unload method is called to merge the models, and the resulting merged model is saved to the specified path.
def push_to_hub(self):
""" Push merged model to HuggingFace Hub """
raise NotImplementedError("push_to_hub not implemented yet")
This optional method is a placeholder for pushing the merged model to the Hugging Face Model Hub. Currently, it raises a NotImplementedError to indicate that this functionality is not implemented in the provided code.
def _print_trainable_parameters(self, model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params
The _print_trainable_parameters method prints the number of trainable parameters and the total number of parameters in the given model. The method iterates through the model's named parameters, accumulating counts for both trainable and total parameters, and then outputs these counts in a clear and concise format.
You don't have to remember all the machine learning algorithms by heart because of amazing libraries in Python. Work on these Machine Learning Projects in Python with code to know more!
Step 2: Run the LLM Fine Tuning Script
You must now run the train.py file in your system. The explanation for the code in this file is as follows:
First, it Includes the required Python modules at the beginning:
import argparse
from QloraTrainer import QloraTrainer
Next, it defines the read_yaml_file function, which reads the YAML configuration file and returns the parsed data.
def read_yaml_file(file_path):
with open(file_path, 'r') as file:
try:
data = yaml.safe_load(file)
return data
except yaml.YAMLError as e:
print(f"Error reading YAML file: {e}")
After that, it contains the following code which ensures that the script expects the user to provide the path to the YAML configuration file as a command-line argument.
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("config_path", help="Path to the config YAML file")
args = parser.parse_args()
config = read_yaml_file(args.config_path)
Next, it creates an instance of the QloraTrainer class, passing the configuration data obtained from the YAML file:
trainer = QloraTrainer(config)
The next step involves loading the base language model as specified in the configuration using the load_base_model method:
print("Load base model")
trainer.load_base_model()
This step initializes the tokenizer and base model, ensuring that they are ready for fine-tuning. Finally, it Initiates the training process by calling the train method:
print("Start training")
trainer.train()
This step sets up the required configurations, preprocesses the data, and starts the training loop using the Hugging Face Trainer. After training, merge the base model and any adapter model and save the resulting model:
print("Merge model and save")
trainer.merge_and_save()
This step ensures that the fine-tuned model is saved to disk for later use.
Now, the final step is to run the script from the command line, providing the path to this YAML configuration file:
python fine_tune_script.py open_llama_7b_qlora_uncensored.yaml
This command executes the script, triggering the fine-tuning process based on the specified configuration. During training, the script may print training progress information, such as the number of batches processed, loss values, etc. Monitor the console for updates on the training progress.
Congratulations! You have successfully executed the fine-tuning script, training an LLM based on the provided configuration. The resulting model is now saved and ready for further evaluation or use in your tasks.
Step-3 Testing Model Performance
For a quick assessment of the model performance, you can use the inference.py file, which has the following code:
import argparse
import torch
import yaml
from langchain import PromptTemplate
from transformers import (AutoConfig, AutoModel, AutoModelForSeq2SeqLM,
AutoTokenizer, GenerationConfig, LlamaForCausalLM,
LlamaTokenizer, pipeline)
def read_yaml_file(file_path):
with open(file_path, 'r') as file:
try:
data = yaml.safe_load(file)
return data
except yaml.YAMLError as e:
print(f"Error reading YAML file: {e}")
def get_prompt(human_prompt):
prompt_template=f"### HUMAN:\n{human_prompt}\n\n### RESPONSE:\n"
return prompt_template
def get_llm_response(prompt):
raw_output = pipe(get_prompt(prompt))
return raw_output
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("config_path", help="Path to the config YAML file")
args = parser.parse_args()
config = read_yaml_file(args.config_path)
print("Load model")
model_path = f"{config['model_output_dir']}/{config['model_name']}"
if "model_family" in config and config["model_family"] == "llama":
tokenizer = LlamaTokenizer.from_pretrained(model_path)
model = LlamaForCausalLM.from_pretrained(model_path, device_map="auto", load_in_8bit=True)
else:
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", load_in_8bit=True)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=512,
temperature=0.7,
top_p=0.95,
repetition_penalty=1.15
)
print(get_llm_response("What is your favorite movie?"))
This script is intended for a quick check to see if the loaded language model provides coherent responses to a specific input prompt. It's not designed as a robust inference platform but serves as a simple verification tool.
-
A text generation pipeline, 'pipe,' is set up using Hugging Face's pipeline function for language model inferences.
-
The pipeline is customized for text generation with specific settings, including the language model (model) and associated tokenizer (tokenizer).
-
Parameters such as max_length=512, temperature=0.7, top_p=0.95, and repetition_penalty=1.15 fine-tune the generation process.
-
Based on the provided YAML configuration, the script loads a pre-trained language model from Hugging Face's transformers library.
-
Human-generated prompts are formatted using the get_prompt function, creating a template for model input and response.
-
The argparse module handles command-line arguments, expecting a YAML configuration file path (config_path).
-
The read_yaml_file function interprets the YAML configuration, which likely contains the language model and fine-tuning settings.
-
The configured pipeline (pipe) generates responses to a predefined prompt ("What is your favorite movie?") using the loaded model.
-
The generated output is printed to the console, enabling a quick assessment of the model's coherence and performance.
Learn Fine Tuning LLMs with ProjectPro
Large language models have emerged as the next frontier in AI applications. Understanding the intricacies of LLMs requires an in-depth knowledge of various concepts in NLP. And if you're seeking a comprehensive and structured approach to learning NLP, look no further than ProjectPro, a distinguished platform hosting a rich repository of solved projects in data science and big data. ProjectPro simplifies the journey by providing a solid foundation in NLP essentials. The platform's curated projects offer hands-on experience, bridging the gap between theory and application. ProjectPro becomes your guide in unraveling the complexities of Language Models, making the learning process insightful and enjoyable. By subscribing to ProjectPro, you can access a wealth of resources that empower you to refine your skills and stay ahead in the competitive AI landscape. Take a proactive step towards professional growth, immerse yourself in practical projects, and unlock the full potential of LLMs with ProjectPro — your partner in the dynamic world of artificial intelligence. Subscribe today and take your career to the next level.
FAQ
1) What is the difference between tuning and fine-tuning in LLMs?
Tuning in LLMs refers to adjusting hyperparameters during initial training, while fine-tuning involves training on specific tasks or domains using pre-trained models, optimizing for task-specific data.
2) How much data do you need to fine tune an LLM?
The amount of data needed for fine-tuning LLMs varies but generally requires a smaller dataset than training from scratch, often in the range of hundreds to thousands of task-specific examples.
3) How do you evaluate a fine-tuned LLM?
Evaluating a fine-tuned LLM involves metrics relevant to the specific task, such as accuracy, precision, recall, or task-specific performance indicators, measuring how well the model performs on the targeted domain or task.

About the Author

Manika
Manika Nagpal is a versatile professional with a strong background in both Physics and Data Science. As a Senior Analyst at ProjectPro, she leverages her expertise in data science and writing to create engaging and insightful blogs that help businesses and individuals stay up-to-date with the