How Data Partitioning in Spark helps achieve more parallelism?
Get in-depth insights into Spark partition and understand how data partitioning helps speed up the processing of big datasets.

![]()
Apache Spark is the most active open big data tool reshaping the big data market and has reached the tipping point in 2015.Wikibon analysts predict that Apache Spark will account for one third (37%) of all the big data spending in 2022. The huge popularity spike and increasing spark adoption in the enterprises, is because its ability to process big data faster. Apache Spark allows developers to run multiple tasks in parallel across hundreds of machines in a cluster or across multiple cores on a desktop. All thanks to the primary interaction point of apache spark RDDs. Under the hood, these RDDs are stored in partitions and operated in parallel. What follows is a blog post on partitioning data in apache spark and how it helps speed up processing big data sets.

Spark Project - Airline Dataset Analysis using Spark MLlib
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectSpark Partition – Why Use a Spark Partitioner?
When it comes to cluster computing, it is pretty challenging to reduce network traffic. There is a considerable amount of data shuffle around the network in preparation for subsequent RDD processing. When the data is key-value oriented, partitioning becomes essential. Because the range of keys or comparable keys is in the same partition, shuffling is minimized. As a result, processing becomes significantly faster.

Some transformations need data reshuffling among worker nodes and thus benefit substantially from partitioning. For instance, co-group, groupBy, groupByKey, and other operations need many I/O operations.
Partitioning helps significantly minimize the amount of I/O operations accelerating data processing. Spark is based on the idea of data locality. It indicates that for processing, worker nodes use data that is closer to them. As a result, partitioning decreases network I/O, and data processing becomes faster.
New Projects
What is a Partition in Spark?
Spark is a cluster processing engine that allows data to be processed in parallel. Apache Spark's parallelism will enable developers to run tasks parallelly and independently on hundreds of computers in a cluster. All thanks to Apache Spark's fundamental idea, RDD.
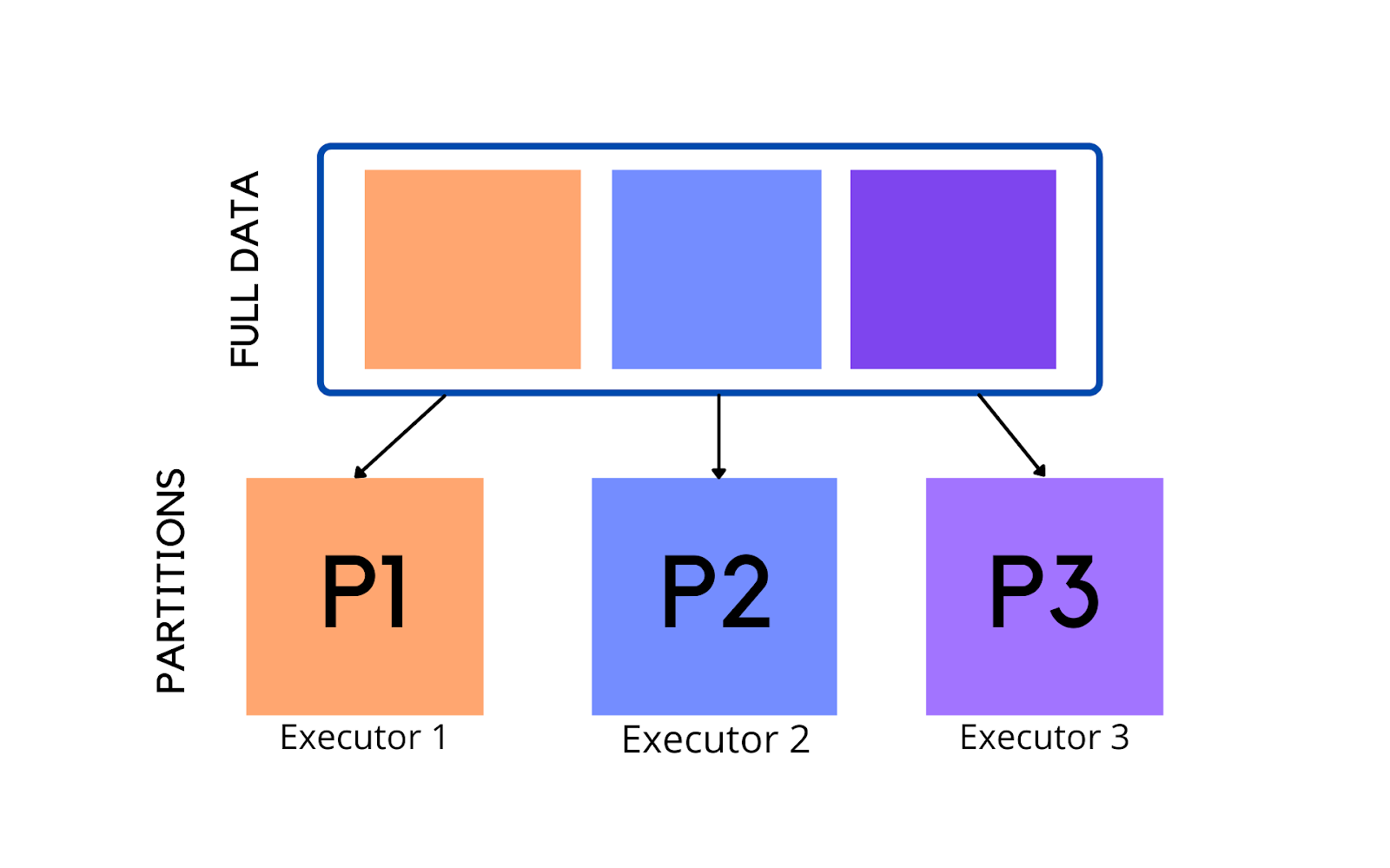
Resilient Distributed Datasets are collection of various data items that are so huge in size, that they cannot fit into a single node and have to be partitioned across various nodes. Spark automatically partitions RDDs and distributes the partitions across different nodes. A partition in spark is an atomic chunk of data (logical division of data) stored on a node in the cluster. Partitions are basic units of parallelism in Apache Spark. RDDs in Apache Spark are collection of partitions.
Here’s a simple example that creates a list of 10 integers with 3 partitions –
integer_RDD = sc.parallelize (range (10), 3)
Characteristics of a Partition in Spark
- Every machine in a spark cluster contains one or more partitions.
- The number of partitions in spark are configurable and having too few or too many partitions is not good.
- Partitions in Spark do not span multiple machines.
Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers
Here's what valued users are saying about ProjectPro

Anand Kumpatla
Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd

Gautam Vermani
Data Consultant at Confidential
Not sure what you are looking for?
View All ProjectsPartitioning in Spark
One important way to increase parallelism of spark processing is to increase the number of executors on the cluster. However, knowing how the data should be distributed, so that the cluster can process data efficiently is extremely important. The secret to achieve this is partitioning in Spark. Apache Spark manages data through RDDs using partitions which help parallelize distributed data processing with negligible network traffic for sending data between executors. By default, Apache Spark reads data into an RDD from the nodes that are close to it.
Communication is very expensive in distributed programming, thus laying out data to minimize network traffic greatly helps improve performance. Just like how a single node program should choose the right data structure for a collection of records, a spark program can control RDD partitioning to reduce communications. Partitioning in Spark might not be helpful for all applications, for instance, if a RDD is scanned only once, then portioning data within the RDD might not be helpful but if a dataset is reused multiple times in various key oriented operations like joins, then partitioning data will be helpful.
Partitioning is an important concept in apache spark as it determines how the entire hardware resources are accessed when executing any job. In apache spark, by default a partition is created for every HDFS partition of size 64MB. RDDs are automatically partitioned in spark without human intervention, however, at times the programmers would like to change the partitioning scheme by changing the size of the partitions and number of partitions based on the requirements of the application. For custom partitioning developers have to check the number of slots in the hardware and how many tasks an executor can handle to optimize performance and achieve parallelism.
Upskill yourself for your dream job with industry-level big data projects with source code
How many partitions should a Spark RDD have?
Having too large a number of partitions or too few - is not an ideal solution. The number of partitions in spark should be decided thoughtfully based on the cluster configuration and requirements of the application. Increasing the number of partitions will make each partition have less data or no data at all. Apache Spark can run a single concurrent task for every partition of an RDD, up to the total number of cores in the cluster. If a cluster has 30 cores then programmers want their RDDs to have 30 cores at the very least or maybe 2 or 3 times of that.
As already mentioned above, one partition is created for each block of the file in HDFS which is of size 64MB.However, when creating a RDD a second argument can be passed that defines the number of partitions to be created for an RDD.
val rdd= sc.textFile (“file.txt”, 5)
The above line of code will create an RDD named textFile with 5 partitions. Suppose that you have a cluster with four cores and assume that each partition needs to process for 5 minutes. In case of the above RDD with 5 partitions, 4 partition processes will run in parallel as there are four cores and the 5th partition process will process after 5 minutes when one of the 4 cores, is free. The entire processing will be completed in 10 minutes and during the 5th partition process, the resources (remaining 3 cores) will remain idle. The best way to decide on the number of partitions in an RDD is to make the number of partitions equal to the number of cores in the cluster so that all the partitions will process in parallel and the resources will be utilized in an optimal way.
Recommended Reading: Spark vs Hive - What's the Difference
The number of partitions in a Spark RDD can always be found by using the partitions method of RDD. For the RDD that we created the partitions method will show an output of 5 partitions
Scala> rdd.partitions.size
Output = 5
If an RDD has too many partitions, then task scheduling may take more time than the actual execution time. To the contrary, having too less partitions is also not beneficial as some of the worker nodes could just be sitting idle resulting in less concurrency. This could lead to improper resource utilization and data skewing i.e. data might be skewed on a single partition and a worker node might be doing more than other worker nodes. Thus, there is always a trade off when it comes to deciding on the number of partitions.
Some acclaimed guidelines for the number of partitions in Spark are as follows-
When the number of partitions is between 100 and 10K partitions based on the size of the cluster and data, the lower and upper bound should be determined.
- The lower bound for spark partitions is determined by 2 X number of cores in the cluster available to application.
- Determining the upper bound for partitions in Spark, the task should take 100+ ms time to execute. If it takes less time, then the partitioned data might be too small or the application might be spending extra time in scheduling tasks.
Types of Partitioning in Apache Spark
- Hash Partitioning in Spark
- Range Partitioning in Spark
Hash Partitioning in Spark
Spark Hash Partitioning attempts to spread the data evenly across various partitions based on the key. Object.hashCode method is used to determine the partition in Spark as partition = key.hashCode () % numPartitions.
Range Partitioning in Spark
Some Spark RDDs have keys that follow a particular ordering, for such RDDs, range partitioning is an efficient partitioning technique. In range partitioning method, tuples having keys within the same range will appear on the same machine. Keys in a range partitioner are partitioned based on the set of sorted range of keys and ordering of keys.
Spark’s range partitioning and hash partitioning techniques are ideal for various spark use cases but spark does allow users to fine tune how their RDD is partitioned, by using custom partitioner objects. Custom Spark partitioning is available only for pair RDDs i.e. RDDs with key value pairs as the elements can be grouped based on a function of each key. Spark does not provide explicit control of which key will go to which worker node but it ensures that a set of keys will appear together on some node. For instance, you might range partition the RDD based on the sorted range of keys so that elements having keys within the same range will appear on the same node or you might want to hash partition the RDD into 100 partitions so that keys that have same hash value for modulo 100 will appear on the same node.
What is Spark repartition?
Many times, spark developers will have to change the original partition. This can be achieved by changing the spark partition size and number of spark partitions. This can be done using the repartition() method.
df.repartition(numberOfPartitions)
repartition() shuffles the data and divides it into a number partitions. But a better way to spark partitions is to do it at the data source and save network traffic.
Explore real-world Apache Hadoop projects by ProjectPro and land your Big Data dream job today!
How to decide number of partitions in Spark?
RDDs can be created with specific partitioning in two ways –
- Providing explicit partitioner by calling partitionBy method on an RDD,
- Applying transformations that return RDDs with specific partitioners. Some operation on RDDs that hold to and propagate a partitioner are-
- Join
- LeftOuterJoin
- RightOuterJoin
- groupByKey
- reduceByKey
- foldByKey
- sort
- partitionBy
- foldByKey
Spark partitioning Best practices
-
PySpark partitionBy() method
While writing DataFrame to Disk/File system, PySpark partitionBy() is used to partition based on column values. PySpark divides the records depending on the partition column and puts each partition data into a sub-directory when you write DataFrame to Disk using partitionBy().
PySpark Partition divides a large dataset into smaller chunks using one or more partition keys. You can also use partitionBy() to build a partition on several columns; simply give the columns you wish to partition as an argument.
Let’s create a DataFrame by reading a CSV file. You can find the dataset at this link Cricket_data_set_odi.csv
# importing module
import pyspark
from pyspark.sql import SparkSession
from pyspark.context import SparkContext
# create sparksession and give an app name
spark = SparkSession.builder.appName(‘dezyreApp’).getOrCreate()
# create DataFrame
df=spark.read.option("header",True).csv("Cricket_data_set_odi.csv")
-
PySpark partitionBy() with One column:
For the following instances, we'll utilize team as a partition key from the DataFrame above:
df.write.option("header", True) \
partitionBy("Team") \
mode("overwrite") \
csv("Team")We have a total of 9 different teams in our dataframe. Thus it produces nine directories. The partition column and its value (partition column=value) would be the name of the sub-directory.
FAQs
How to decide number of partitions in Spark?
In Spark, one should carefully choose the number of partitions depending on the cluster design and application requirements. The best technique to determine the number of spark partitions in an RDD is to multiply the number of cores in the cluster with the number of partitions.
How do I create a partition in Spark?
In Spark, you can create partitions in two ways -
-
By invoking partitionBy method on an RDD, you can provide an explicit partitioner,
-
By applying Transformations to yield RDDs with specific partitioners.

About the Author

ProjectPro
ProjectPro is the only online platform designed to help professionals gain practical, hands-on experience in big data, data engineering, data science, and machine learning related technologies. Having over 270+ reusable project templates in data science and big data with step-by-step walkthroughs,