How to Use Apache Kafka for Real-Time Data Streaming?
Learn the basics about Apache Kafka, real-time data streaming, and how you can use both to build a streaming pipeline providing faster, more reliable insights. | ProjectPro
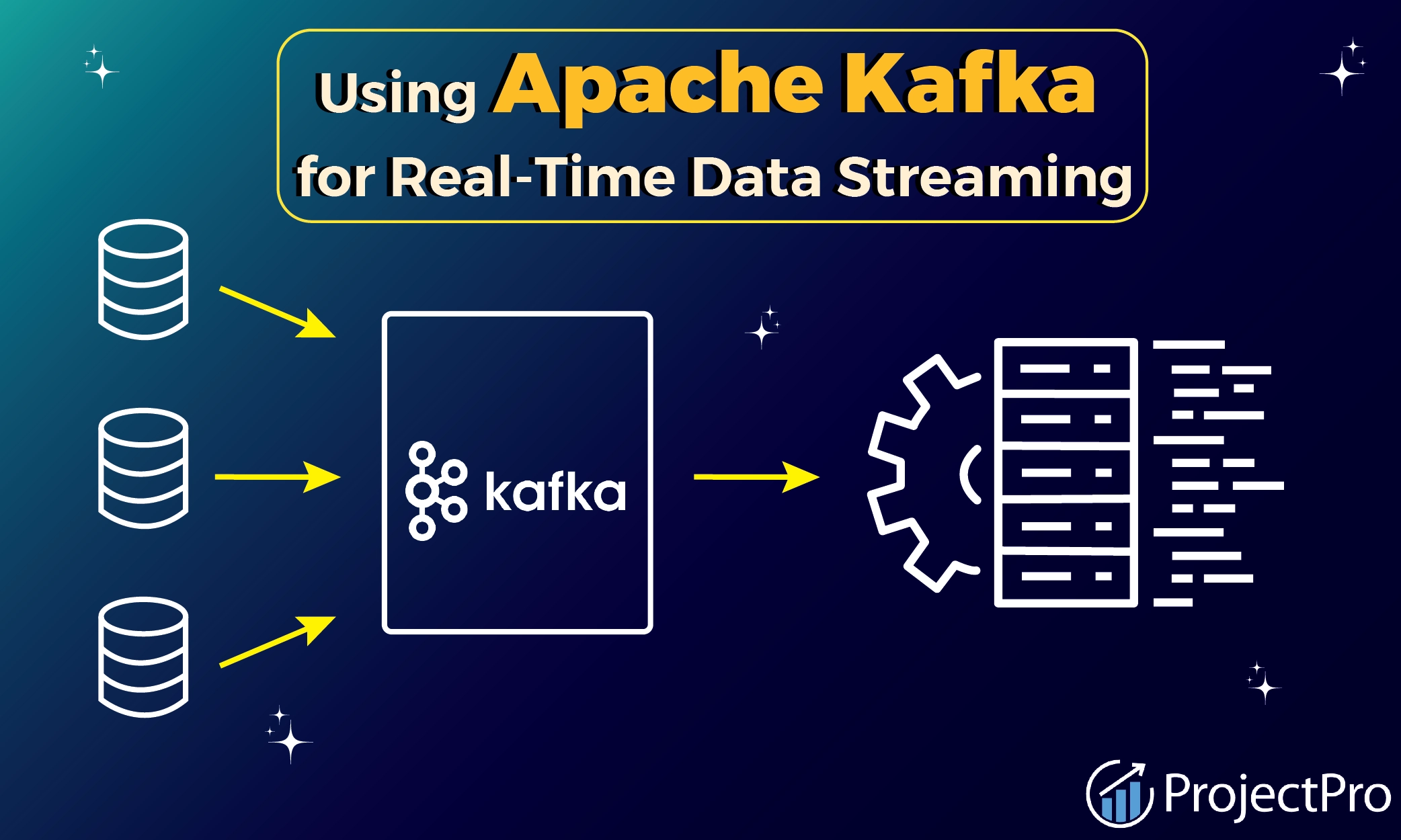
If you’re looking for everything a beginner needs to know about using Apache Kafka for real-time data streaming, you’ve come to the right place. This blog post explores the basics about Apache Kafka and its uses, the benefits of utilizing real-time data streaming, and how to set up your data pipeline. Let's dive in.

Building Real-Time Data Pipelines with Kafka Connect
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectTable of Contents
What is Apache Kafka?
Apache Kafka is an open-source, distributed data streaming platform by the Apache Software Foundation. It provides a data store optimized for ingesting and processing streaming data in real-time and, as such, can be used for real-time data pipelines, stream processing, and data integration at scale.
Kafka was initially developed at LinkedIn in 2011 for performing data analytics on user activity in social networking. Since then, it has been used by companies operating in various industries to manage big data archives, providing a platform for them to build their own custom software services to store and process data.
Kafka can peform real-time processing of data and batch data processing with low latency, allows you to subscribe to and publish events, and then process and perform analytics on them.

Benefits of Using Apache Kafka
Apache Kafka has use cases in a range of industries, including retail, banking, insurance, healthcare, telecoms, and IoT (Internet of Things). Several benefits to using Apache Kagkaa as a data streaming platform have made it a popular choice across such disparate industries (and just as important as picking the right website name during domain name registration)!
Firstly, Kafka provides a faster processing speed than its competitors, allowing for real-time data streaming with near zero latency. This enables organizations that produce data to perform real-time data analytics, allowing them to quickly make well-informed business decisions and efficiently obtain the results of scientific research.

Image sourced from confluent.io
Kafka Connect is a free, open-source component of Apache Kafka, which acts as a centralized data hub, providing integration between databases, file systems, search indexes, key-value stores, and data integration tools. It offers more than 120 pre-built connectors, which can be used to quickly move large data sets in and out of Kafka and accelerate the development of applications.
Finally, Kafka is well-known for being highly scalable and durable. Kafka performs load balancing over a pool of servers, allowing production clusters to be scaled up or down depending on demand. It also distributes the storage of data streams in clusters with fault tolerance and provides intra-cluster replication, making the data it handles highly durable and fault-tolerant.
New Projects
Before you move forward to the next section, here is an insight by Stanislav Kozlovski, helping you understand the importance of having Kafka in you data pipeline.

Here's what valued users are saying about ProjectPro

Anand Kumpatla
Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd

Gautam Vermani
Data Consultant at Confidential
Not sure what you are looking for?
View All ProjectsWhat is Real-Time Data Streaming?
Real-time data streaming is a technology that makes it possible to collect and process data from various data sources in real time. This allows you to extract meaning and insights from your data as soon as it's generated, which enables faster, better-informed decision-making.
Data streaming also has a multitude of other uses and can be used to power messaging systems, build a gaming pipeline, or in log aggregation.
A real-time streaming architecture typically consists of 5 key components:
-
Stream source: This is where the data ingestion takes place. It could be ingested from a database, mobile app, IoT sensor, or various other sources.
-
Stream ingestion: Stream ingestion tools act as an intermediary between the system receiving the data and the data source generating it. They’re responsible for converting raw streams into a consumable format, such as CSV or JSON. Apache Kafka is one such example of a stream ingestion tool.
-
Stream storage: Streamed data needs to be stored somewhere until it’s needed, usually in a data warehouse or data lake environment.
-
Stream processing: The tools used to process streams transform incoming data into a structured state, making it ready to be used by analytics tools. Transformation processes can include normalization, enrichment, and validation.
-
Stream destination: Once the previous components in the data stream architecture have generated an analysis of the data, it needs to be sent downstream to extract value from it. Stream destinations can include data warehouses, databases, event-driven applications, or third-party integrations.
Worried about finding good Hadoop projects with Source Code? ProjectPro has solved end-to-end Hadoop projects to help you kickstart your Big Data career.
Benefits of Real-Time Data Streaming
There are several reasons data driven organizations choose to utilize real-time data streaming, making it one of the fastest-growing aspects of data engineering solutions.
Firstly, it allows for the generation of continuous and instantaneous business insights. This allows decision-makers to react in near real time to changing variables, making critical business decisions rapidly and with greater insight.
Real-time data streaming also helps to reduce the amount of data storage solutions needed. Because data is processed as it is generated, there’s no need to store it somewhere for batch processing later. This helps organizations save on storage space and its associated costs.
The above few sections have been nicely summarized in this post by Rishabh Takkar.

How to use Apache Kafka for Real-Time Data Streaming?

Image sourced from wikimedia.org
Apache Kafka runs on a horizontally scalable cluster of commodity servers. It uses these servers to ingest real-time data from multiple systems and applications, known as producers.
Data is sent and received easily between Kafka servers. Changes in the state of the system are recorded as events.
Data can be transformed, read and rewritten to topics.
This data is then made available to a variety of consumer applications.
To explain in more detail, we can expand upon some of the key terms used above:
-
Producer: a client application that pushes events into topics. Examples of producers include IoT devices, databases, or web apps.
-
Event: A record of a change to the state of the system. Apache Kafka is an event streaming platform, meaning that it transmits data as events. It can publish and subscribe to a stream of events and store and process them as they occur.
-
Topic: The method used to categorize and store events. They are logs that hold events in a logical order and enable data to be sent and received between Kafka servers easily. Older topic messages can be updated by newer topic messages, which allows data to be transformed.
-
Consumer: Applications that read and process events from partitions. Java applications can pull data from topics and write results back to Apache Kafka, thanks to the Streams API.

Using Kafka for Real-time Streaming Example
Here’s how to get started with real-time data streaming using Apache Kafka.
1. Install Kafka
The first step is to download and install the latest version of Kafka:
$ tar -xzf kafka_2.13-3.4.0.tgz
$ cd kafka_2.13-3.4.0
2. Start the Kafka Environment
The next step is to start the Kafka environment. For our example, we’ll be using KRaft, but you can start Apache Kafka with ZooKeeper if you prefer.
First, generate a cluster ID:
$ KAFKA_CLUSTER_ID=“$(bin/kafka-storage.sh random uuid)”
Then format the Log Directories:
$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
Then you can start the Kafka server:
$ bin /kafka-server-start.sh config/kraft/server.properties
You should now have a basic Kafka environment installed and ready to use.
3. Create a Topic
Before you can start writing events, you need to create a specific topic in which they can be stored.
Open a separate terminal session, and run this command:
$ bin/kafka-topics.sh - -create - -topic quickstart-events - -bootstrap-server localhost:9092
4. Write Events
Now that you’ve created a topic, you can begin to write events.
Run the console producer client to write some vents into your topic.
$ bin/kafka-console-producer.sh - -topic quickstart-events - -bootstrap-server localhost:9092
First event
Second event
Third event
Each line you enter should result in a separate event being written to the topic by default. Once you’ve added the desired events, you can close the producer client with ‘Ctrl-C.’
5. Read the Events
Now, you can read the events that you’ve just written to the topic.
$ bin/kafka-console-producer.sh - -topic quickstart-events - -from-beginning - -bootstrap-server localhost:9092
You can play around at this stage, writing events in your producer terminal and seeing how they appear in your consumer terminal. Events are durably stored in Kafka, so you can read them using as many consumer terminals as you wish, as many times as you wish.
If you have data that has been annotated using data labeling software, you can use it here to test the system you’re building.
6. Stream Your Events
Now, you can begin to ingest data from external systems into Kafka, and vice versa, using Kafka Connect.
For this example, we will use Kafka Connect with simple connectors to import data from a file to our Kafka topic and then export data from that Kafka topic to a file.
To do this, we’ll use a relative path and consider the connector’s path as an uber jar. To set this up, we’ll need to edit the file ‘config/connect-standalone.properties’ so that the ‘plugin.path’ configuration matches the following:
> echo “plugin.path=libs/connect-file-3.4.0.jar”
Then we can create some seed data to test with:
> echo -e “foo\nbar > test.txt
Now we need to set up some connectors:
> bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
There are two connectors. One is a source connector that reads lines from an input file and produces them to a Kafka topic. The other is a sink connector, which will read messages from the Kafka topic and then produces lines as output files.
7. Process Events
Now that the data is stored in Kafka in the form of events, you can begin to process the data. This will be achieved using the Kafka Streams client library. This library allows you to implement microservices and applications, with the input and output data stored in topics in Kafka.
You can achieve a variety of data processing tasks using Kafka Streams. For example, you could use it to speed up the process of visual data modeling with Databricks. Why not play around and see what algorithms you can implement?

Free to use image sourced from Unsplash
Learn to use Apache Kafka for Real-Time Data Streaming with ProjectPro
Now you should have a basic understanding of Apache Kafka, real-time data streaming, and how to use the former to achieve the latter. If you’re building a product to market that uses data streaming, remember to use tools such as Global App Testing’s beta testing software to smooth out any kinks in your coding.
But before you jump on to using advance tools, remember, true mastery of Apache Kafka and its applications in real-time streaming comes from actively practicing and working on projects. Embracing a "learning by doing" approach can significantly enhance your understanding and proficiency in this powerful technology. To support your journey in gaining practical skills, we recommend exploring ProjectPro, an exceptional platform that hosts over 270+ projects in Data Science and Big Data. ProjectPro offers an immersive learning environment where you can apply the concepts you've learned and work on real-world projects. By actively engaging with ProjectPro's diverse range of projects, you'll not only deepen your knowledge of Apache Kafka but also develop valuable expertise in Data Science and Big Data. The platform provides an opportunity to tackle industry-relevant challenges and hone your skills in a hands-on manner. So, don’t miss out on this opportunity to take your skills to the next level and subscribe to ProjectPro today!
FAQs
1. What is streaming data in Kafka?
Streaming data in Kafka refers to a continuous flow of real-time data, such as event updates, logs, or messages, that is ingested, processed, and distributed by the Apache Kafka messaging system.
2. What is a real-time example of Kafka Streams?
A real-time example of Kafka Streams is a social media analytics platform that processes incoming tweets in real-time, performs sentiment analysis, and provides live dashboards showing real-time trends, user sentiment, and engagement metrics. Kafka Streams enables the platform to handle the continuous flow of tweets and process them in real-time for immediate insights.

About the Author

Manika
Manika Nagpal is a versatile professional with a strong background in both Physics and Data Science. As a Senior Analyst at ProjectPro, she leverages her expertise in data science and writing to create engaging and insightful blogs that help businesses and individuals stay up-to-date with the