50+ MLOps Interview Questions And Answers
Crack the code to MLOps interview in 2024! Our detailed guide lists the top MLOps interview questions and answers, ensuring your success. | ProjectPro

MLOps interview jitters? We have got you covered! This ultimate guide offers the inside scoop on the top MLOps interview questions and answers, from pipelines and deployment to monitoring and troubleshooting. Time to impress hiring managers and land your dream job in the booming MLOps space – start prepping now!

Learn to Build an End-to-End Machine Learning Pipeline - Part 1
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectDid you know the global MLOps market will likely reach $37.4 billion by 2032, growing at a CAGR of 39.3% from 2023 to 2032?
Looks like MLOps is the future! With data driving every decision nowadays, machines are learning faster than ever. But who teaches the machines? That's where MLOps comes in - the secret sauce behind putting those ML models to work in the real world. And guess what? The demand for MLOps experts is skyrocketing! Companies are actively looking for people who can effectively bridge the gap between data science and production. So, whether you are a data scientist looking to level up or a tech enthusiast ready to join the revolution, this ultimate MLOps interview guide is your golden ticket, as we have packed it with the top MLOps interview questions and answers. So, buckle up, future MLOps masters, because this blog is your roadmap to cracking those interviews and landing your dream job in the hottest job market out there!
Table of Contents
- Top 50+ MLOps Interview Questions And Answers For You in 2024
- MLOps Interview Questions For Freshers
- MLOps Interview Questions For Experienced Professionals
- AWS MLOps Interview Questions And Answers
- Azure MLOps Interview Questions And Answers
- MLOps Engineer Interview Questions And Answers
- MLOps Interview Questions GitHub
- MLOps Interview Questions And Answers: Next Steps With ProjectPro
- FAQs on MLOps Interview Questions And Answers
Top 50+ MLOps Interview Questions And Answers For You in 2024
From pipelines to performance, master every MLOps angle! Whether you are a fresher or an experienced professional, elevate your MLOps expertise as this section explores everything- from foundational concepts to advanced scenarios. The following sections explore interview questions on MLOps engineer skills, specific tools, and cloud platforms like AWS and Azure. Let us help you get started with your MLOps journey.

MLOps Interview Questions For Freshers
For freshers entering the MLOps domain, this dedicated section will help them grasp essential concepts like model deployment, CI/CD for ML, and foundational MLOps tools.
-
Explain the concept of an MLOps pipeline and its key stages.
An MLOps pipeline automates the ML lifecycle stages, from data acquisition and pre-processing to model training, evaluation, deployment, and monitoring. The key stages include-
-
Data Acquisition and Preprocessing- Gathering and preparing data for model training.
-
Model Training- Building the ML model using the prepared data.
-
Model Evaluation- Assessing the model's performance on unseen data.
-
Model Deployment- Integrating the trained model into production systems.
-
Model Monitoring- Tracking the model's performance and detecting any degradation over time.
-
How does CI/CD for ML differ from traditional CI/CD, and how does it benefit MLOps?
Traditional CI/CD focuses on code deployment, while CI/CD for ML handles code and model artifacts. It includes additional stages like model testing and validation before deployment. Some of the key benefits include:
-
Faster and more frequent deployments- Automate model builds and deployments, reducing manual intervention and time to production.
-
Improved model quality- Integrate automated testing and validation to catch errors early and ensure high-performing models in production.
-
Greater reproducibility and traceability- Track model versions and changes throughout the pipeline for easier debugging and version control.
-
Describe a few different methods for deploying ML models in production.
There are various deployment methods, depending on the infrastructure and needs-
-
Direct Deployment- Deploy the model directly onto production servers, which is suitable for simple models and static environments.
-
Containerization- Package the model and its dependencies in a container (e.g., Docker) for easier deployment and scaling across different environments.
-
Model Serving Platforms- AWS SageMaker or Azure Machine Learning Studio allows automated model deployment, monitoring, and scaling.
Here's what valued users are saying about ProjectPro

Abhinav Agarwal
Graduate Student at Northwestern University

Savvy Sahai
Data Science Intern, Capgemini
Not sure what you are looking for?
View All Projects-
Why is monitoring crucial for ML models in production, and what are some key metrics to track?
Monitoring allows you to identify potential model performance issues over time. Some of the key metrics you must track include-
-
Accuracy- Measures the model's ability to make correct predictions.
-
Precision- Measures the proportion of actual positives among all positive predictions.
-
Recall- Measures the proportion of true positives identified out of all actual positives.
-
Latency- Measures the time the model takes to make a prediction.
-
Drift- Detects model performance changes due to data distribution shifts or other factors. By monitoring these metrics, you can proactively address issues like performance degradation, bias, or security vulnerabilities.
-
What is the purpose of MLflow Tracking, and how does it benefit the MLOps process?
MLflow Tracking is a component of MLflow that allows users to log and query experiments. It captures and logs parameters, metrics, artifacts, and source code associated with each run, providing a comprehensive record of the ML development process. This enhances collaboration, reproducibility, and the ability to compare and evaluate different model iterations.
-
Discuss the role of Docker in MLOps and how it interacts with MLflow for model packaging and deployment.
Docker is a containerization platform that plays a vital role in MLOps by encapsulating models, dependencies, and runtime environments. MLflow supports the use of Docker containers for packaging models. By using Docker, MLflow ensures consistency in model deployment across different environments. Data scientists can package their models into Docker containers using MLflow, making it easy to deploy and reproduce models in various production settings.
-
Discuss the challenges associated with deploying ML models to production. How can MLOps address these challenges?
Deploying ML models to production involves challenges such as scalability, real-time inference, and integration with existing systems. MLOps addresses these challenges by automating deployment processes through containerization (e.g., Docker), maintaining version control, and establishing continuous monitoring. This ensures smooth transitions from development to production and facilitates ongoing model maintenance.
-
How can you troubleshoot a problem with an MLOps pipeline?
Troubleshooting requires a systematic approach, including the following steps-
-
Identify the affected stage- Analyze logs, metrics, and alerts to pinpoint where the issue occurs.
-
Investigate the root cause- Examine logs and data within the affected stage for specific errors or inconsistencies.
-
Implement a fix and test it- Develop and test a solution to address the issue, ensuring it doesn't introduce new problems.
-
Monitor for further issues- Continue monitoring the pipeline and relevant metrics after fixing the issue to ensure long-term stability.
-
Discuss the advantages of using a containerized approach for deploying ML models.
Containerization offers several benefits, including-
-
Portability- Models run consistently across different environments regardless of the underlying infrastructure.
-
Isolation- Containers enable isolation from other applications and dependencies, improving security and stability.
-
Scalability- Easily scale models by deploying additional containers on demand.
-
Reproducibility- Captured dependencies within the container ensure consistent model behavior. Containerization simplifies ML models' deployment, scaling, and management in MLOps workflows.
-
Briefly describe how Kubeflow facilitates MLOps on Kubernetes.
Kubeflow is an open-source platform for building and deploying ML pipelines on Kubernetes. It offers:
-
Workflow Orchestration- You can define and automate ML pipelines with training, evaluation, and deployment components.
-
Scalability And Portability- You can leverage Kubernetes for scaling and running pipelines across different environments.
-
Resource Management- You can efficiently allocate and manage resources like CPU and memory for ML tasks.
-
Integration With Tools- Kubeflow integrates with other MLOps tools like MLflow and TensorFlow for a comprehensive workflow. Kubeflow enables MLOps engineers to build and manage scalable, portable ML pipelines on Kubernetes.
-
What are some additional essential MLOps tools and their functionalities?
The MLOps toolbox is vast and includes several useful tools, such as
-
Airflow- Provides a workflow scheduling and orchestration platform for the automated execution of ML pipelines.
-
Neptune- Offers model registry and experiment tracking capabilities similar to MLflow, with additional features like model comparison and impact analysis.
-
TensorBoard- Creates visual dashboards for visualizing training loss, accuracy, and other metrics during model development.
-
Model Explainability tools (LIME, SHAP)- Help understand the reasoning behind model predictions, increasing trust and addressing bias concerns.
-
How do Kubeflow Pipelines contribute to MLOps workflows, and what are its key features?
Kubeflow Pipelines is a component of Kubeflow that facilitates the orchestration and automation of end-to-end ML workflows. It allows engineers to define, deploy, and manage complex workflows involving data preparation, model training, and deployment. Kubeflow Pipelines provides a visual interface for designing workflows, version control for pipeline definitions, and scalability for running workflows on Kubernetes clusters, making it a powerful tool for MLOps automation.
MLOps Interview Questions For Experienced Professionals
For seasoned professionals navigating the complexities of MLOps, this section offers insights on model explainability, data drift, scalability, and practical problem-solving. Elevate your expertise and prepare for advanced discussions with the questions and answers discussed below, ensuring you stand out in interviews and advance your MLOps career.
-
Explain the concept of data drift and how MLOps can address its associated challenges in production environments.
Data drift refers to the evolution of input data distribution over time, impacting model performance. MLOps addresses data drift by implementing continuous monitoring and retraining strategies, including-
-
Active monitoring- You can track key statistics and metrics of model predictions and input data to detect drift early.
-
Drift detection algorithms- You can implement algorithms to analyze data shifts and trigger alerts statistically.
-
Retraining models with updated data- You can periodically retrain models on new data to adapt to evolving distributions.
-
Adaptive models- You can explore online learning algorithms that continuously update themselves with new data.
-
Explain the importance of model explainability in MLOps and discuss various techniques for achieving it.
Model explainability helps us understand why an ML model makes specific predictions. It's crucial for
-
Debugging and troubleshooting- Identifying potential biases or errors in the model's decision-making process.
-
Building trust and transparency- Explainability facilitates trust in the model's fairness and reliability, especially in high-stakes applications.
-
Complying with regulations- Some industries (e.g., healthcare) require explainability for regulatory compliance.
Some key techniques for achieving model explainability include-
-
Feature Importance Analysis- Identifying the features that contribute most to the model's predictions.
-
Local Interpretable Models (LIME)- Explaining individual predictions based on a simplified model trained on the local data point.
-
SHapley Additive exPlanations (SHAP)- Distributing the prediction's credit among the model's input features.
-
Describe the role of Git within the MLOps context.
Git plays a crucial role in code and model version control for MLOps-
-
Track changes- It provides a comprehensive history of changes made to code and models throughout the ML lifecycle.
-
Collaboration- Git enables efficient collaboration between data scientists, engineers, and other stakeholders working on the project.
-
Reproducibility- Git also allows reverting to previous versions of code and models for troubleshooting or redeployment.
-
Branching and merging- Git facilitates experimentation with different model versions and merges successful iterations into the main pipeline.
-
Discuss strategies for ensuring fairness and mitigating bias in ML models within an MLOps framework.
Models can become biased as a result of biased data or algorithms. You can ensure fairness and mitigate bias in these models by following the proactive steps below-
-
Data Exploration and Pre-processing- Identifying and addressing bias in the training data before model training.
-
Fairness Metrics and Monitoring- Using Equal Opportunity Error Rate (EER) to track bias and evaluate mitigation strategies.
-
Explainability and Counterfactual Analysis- Understanding how model predictions can be biased and using tools to identify and explain these biases.
-
Continuous Feedback and Monitoring- Building feedback loops within the MLOps pipeline to collect user feedback and incorporate fairness considerations into future model iterations.
-
Describe your approach to securing ML models in production within an MLOps environment.
You can use a multi-layered approach to secure ML models in an MLOps environment-
-
Data Security- Implementing controls to prevent unauthorized access and manipulation of training and production data.
-
Model Tamper Detection and Logging- Monitoring models for anomalies and suspicious changes in behavior.
-
Model Versioning and Rollbacks- Ability to revert to previous, trusted model versions in case of security vulnerabilities.
-
Automated Vulnerability Scanning and Mitigation- Integrating security tools into the MLOps pipeline to identify and address vulnerabilities in the model and its dependencies.
-
How would you design an MLOps system for handling large-scale models and deployments?
Scalability is critical for enterprise-grade MLOps. You must consider the following strategies to ensure the MLOps system can efficiently handle large-scale models and deployment-
-
Containerization and Microservices- You can package models and container dependencies for efficient deployment and scale across different environments.
-
Cloud-based Infrastructure- You can leverage cloud platforms like AWS SageMaker or Azure Machine Learning Studio for automated scaling and resource management.
-
Model Serving Frameworks- You can implement serverless or distributed serving frameworks for efficient prediction request handling with high availability.
-
Streamlined CI/CD Pipelines- You can optimize pipelines for faster model builds, deployments, and rollbacks.
-
How do you handle versioning of ML models, primarily when multiple teams work on different project aspects?
Version control is crucial for collaboration. You can use tools like Git to track code changes, while MLflow and DVC (Data Version Control) help manage versions of models and datasets. You must establish clear naming conventions and documentation to track contributions from multiple teams. Furthermore, you must regularly merge changes and conduct code reviews to maintain consistency across the ML pipeline.
-
Share your views on the importance of collaboration between data engineers, scientists, and other stakeholders in successful MLOps implementations. Could you provide examples of effective collaboration scenarios?
Collaboration is key for successful MLOps implementations. Data scientists collaborate with engineers to streamline model deployment, while stakeholders provide domain expertise. Effective communication ensures alignment between technical goals and business objectives. For example, joint sprint planning, regular cross-functional meetings, and shared documentation enhance collaboration, leading to more powerful and impactful MLOps workflows.
-
Suppose you encounter a sudden drop in model accuracy in production. What will be your approach to diagnose and resolve the issue?
You can follow the systematic approach below to handle a sudden drop in model accuracy-
-
Analyze monitoring data- You must look for changes in key metrics like accuracy, precision, recall, and latency.
-
Investigate data pipelines- You must examine data pre-processing and feature engineering stages for potential data drift or quality issues.
-
Review model logs and artifacts- You must check for error messages or anomalous behavior within the model.
-
Redeploy previous model versions- If a recent deployment causes the issue, you must consider rolling back.
-
Analyze explainability tools- If available, you must use explainability tools to understand the drop in accuracy and identify potential biases.
-
Communicate effectively- You must keep stakeholders informed and collaborate with data scientists and engineers to find a solution.
-
Can you share some insights into how you would design a resilient and fault-tolerant MLOps architecture for a production environment?
A resilient MLOps architecture involves redundancy, monitoring, and rapid recovery mechanisms. To achieve this, you will use Kubernetes for container orchestration, ensuring high availability and scalability. You must also implement redundant model serving instances and use load balancing. You must monitor resource usage, set up automated alerts, and integrate with tools like Grafana and Prometheus for real-time insights. You must regularly test and simulate failures to ensure the system's fault tolerance.
-
How does integrating GitOps principles contribute to effective MLOps workflows, and what challenges may arise during implementation?
GitOps principles involve using Git as the source of truth for infrastructure and automation. In MLOps, GitOps ensures version control and collaboration. Some of the significant challenges include managing large repositories, synchronizing changes across branches, and ensuring proper access controls. You can use tools like Argo CD to address these challenges.
-
Is automated testing crucial in MLOps? How can you design effective tests for machine learning models, and have you implemented such tests in your projects?
Automated testing is crucial for maintaining model reliability. You can employ unit tests to check individual components, while integration tests help you assess the entire model pipeline. You can mention any instance, such as when you were working on a fraud detection project, you implemented tests to validate model accuracy, checked for data drift, and ensured the robustness of the model against adversarial attacks. You also employed continuous integration pipelines to run these tests automatically upon each model update, ensuring consistent performance.
AWS MLOps Interview Questions And Answers
From SageMaker to CloudTrail, dive deeper into key AWS services and practices shaping MLOps workflows with the interview questions and answers in this section.
-
How does AWS SageMaker contribute to the MLOps lifecycle, and what are its key features?

Source: aws.amazon.com/sagemaker/mlops/
SageMaker is a fully managed service for developing, training, and deploying ML models. It simplifies the end-to-end MLOps lifecycle by providing tools for data labeling, model training, and deployment. Some of its key features include built-in algorithms, automatic model tuning, and seamless integration with other AWS services, facilitating scalable and efficient MLOps workflows.
-
Describe how you would train a machine learning model using Amazon SageMaker.
You can train an ML model using AWS Sagemaker using the following steps-
-
Choose an instance type- Select an appropriate compute instance based on model size and training requirements.
-
Prepare data- Upload training data to S3 buckets and define pre-processing steps within SageMaker notebooks.
-
Train and tune the model- Utilize SageMaker algorithms or custom containers for model training. Use built-in Hyperparameter Tuning for optimal model configurations.
-
Monitor the training process- Track progress and analyze metrics with SageMaker logs and visualizations.
-
Deploy the trained model- Save the model to an S3 bucket and deploy it using SageMaker endpoints or Lambda functions for real-time predictions.
-
Discuss a few best practices for optimizing costs associated with your MLOps infrastructure on AWS.
Some of the best practices for cost optimization for maintaining MLOps infrastructure on AWS include-
-
Right-size your resources- You should choose the appropriate instance types and scaling configurations based on your workload and budget constraints.
-
Utilize spot instances- You must leverage spot instances for cost-effective computing without compromising performance.
-
Schedule workloads efficiently- You should automate model training and deployment based on your needs to avoid unnecessary resource usage.
-
Review and optimize regularly- You must monitor resource utilization and cost trends to identify areas for further optimization.
-
Leverage serverless options- You should consider serverless services like AWS Lambda for inference to scale automatically and minimize costs.
-
Discuss how you would manage model versions and rollbacks using SageMaker Model Registry.
Sagemaker Model Registry offers several versioning and rollback capabilities, such as
-
Register model versions- Store different iterations of your model in the SageMaker Model Registry for easy selection and comparison.
-
Associate endpoints with versions- Link production endpoints to specific model versions for controlled deployments.
-
Rollback functionality- Easily revert to previous model versions in case of performance degradation or issues in production.
-
Model comparisons and evaluations- Utilize SageMaker Model Registry to compare different model versions based on metrics and performance across various datasets.
-
Describe a few scenarios where you would use AWS Lambda for serving ML models in production.
You should leverage AWS Lambda for serverless deployment scenarios, such as
-
Real-time prediction requests- You can deploy models as Lambda functions for low-latency prediction responses at scale.
-
Cost-effective and scalable- You can pay only for the predictions, eliminating idle resource costs and automatically scaling to handle increased traffic.
-
Easy integration with other AWS services- You can seamlessly integrate Lambda functions with AWS services like S3 for data access and DynamoDB for storing predictions.
-
Fast deployments and updates- You can update model versions deployed as Lambda functions with minimal downtime or infrastructure changes.
-
Explain the role of AWS S3 in MLOps, especially in storing and managing datasets for model training.
AWS S3 (Simple Storage Service) is a versatile object storage service. In MLOps, S3 is commonly used to store and manage datasets for model training. It provides scalable and durable storage with high availability. During model development, data scientists can easily access and retrieve datasets stored in S3, ensuring a centralized and reliable data source for training workflows.
-
What is AWS SageMaker Model Monitor, and how does it contribute to ensuring the ongoing quality of deployed ML models?
SageMaker Model Monitor is a feature that automatically detects and alerts on deviations in model quality. It continuously analyzes data input and output during model inference to identify data and concept drift. Model Monitor helps maintain the accuracy and reliability of deployed models by providing real-time insights into model performance and enabling proactive actions to address potential problems.
-
How would you integrate S3 with Kubeflow for an MLOps workflow on AWS?
You can easily integrate S3 with Kubeflow for an AWS MLOps workflow using the following steps-
-
Store artifacts in S3- Use S3 buckets for storing training data, models, and other ML artifacts for centralized access and management.
-
Install S3 buckets in Kubeflow pods- Enable pods running within Kubernetes clusters on AWS EKS to access and process data stored in S3 buckets directly.
-
Leverage S3's scalability and cost-effectiveness- Utilize S3's efficient data storage and management features for large-scale MLOps workflows at minimal storage costs.
-
Hybrid architecture flexibility- Maintain the benefits of Kubeflow for orchestration and scaling while leveraging S3's advantages for AWS data management.
-
How can you use CloudTrail for MLOps on AWS?
You can use CloudTrail for implementing MLOps on AWS in various ways-
-
Track API calls- Monitor all MLOps-related activities like model training, deployment, and data access within CloudTrail logs.
-
Compliance auditing- Meet compliance requirements by highlighting secure and auditable workflows for ML projects.
-
Troubleshooting and incident response- Analyze CloudTrail logs to identify root causes of errors or security issues within the MLOps pipeline.
-
Cost optimization- Monitor resource usage associated with MLOps activities through CloudTrail logs for cost analysis and optimization.
-
In an AWS SageMaker deployment, how can you implement A/B testing to compare/contrast the performance of two different model versions?
A/B testing in AWS SageMaker involves deploying multiple models simultaneously and directing a portion of the traffic to each version. Amazon SageMaker Autopilot and Multi-Model Endpoints support A/B testing. By comparing metrics such as accuracy or inference time, MLOps teams can objectively evaluate the performance of different model versions and make informed decisions about model deployment.
-
Can you mention a few AWS services that can be used for anomaly detection in your MLOps pipeline?
You can use various AWS tools for anomaly detection in an MLOps pipeline-
-
Amazon Kinesis Firehose- You can stream real-time data from your pipeline into Amazon Kinesis for analysis.
-
Amazon CloudWatch Anomaly Detection- You can use anomaly detection algorithms within CloudWatch to identify unusual patterns in model metrics or data streams.
-
Amazon SNS and Lambda- You can trigger alerts and automated actions based on detected anomalies to address potential issues proactively.
Azure MLOps Interview Questions And Answers
This section focuses on the integration of Azure Machine Learning Studio, Azure DevOps\, and other Azure services crucial for MLOps workflows. Practicing these questions will help you gain valuable insights to excel in building robust MLOps pipelines on the Azure cloud.
-
Explain how you would leverage Azure Machine Learning Studio (AML Studio) and Azure DevOps to create a CI/CD pipeline for your ML model.
Here’s how you can leverage AML Studio and Azure DevOps to build a CI/CD pipeline for your ML model-
-
Develop and train the model in AML Studio- You can use AML Studio's drag-and-drop interface or notebooks to develop and train your model using built-in algorithms or your code.
-
Version control and code management- You can integrate AML Studio with Azure DevOps repositories for version control of your model code, data pipelines, and AML Studio experiments.
-
Automated builds and deployments- You can define CI/CD pipelines within Azure DevOps that automatically build the model, run tests, and deploy it to Azure Kubernetes Service (AKS) or Azure Functions for production.
-
Continuous monitoring and feedback- You can leverage Azure Monitor and Application Insights to track model performance metrics and integrate feedback loops into the pipeline for further model improvement.
-
How would you ensure data security and compliance within your Azure MLOps workflow?
You can ensure data security and compliance within your Azure MLOps workflow using the following Azure services-
-
Azure Key Vault- Securely store sensitive data like API keys and passwords used in your MLOps workflow within Azure Key Vault.
-
Azure Active Directory (AAD)- Enforce role-based access control (RBAC) using AAD to restrict access to data and models based on user permissions.
-
Azure Data Loss Prevention (DLP)- Implement DLP policies to scan data used in your MLOps pipeline for potential privacy violations or compliance issues.
-
Azure Security Center- Leverage Azure Security Center for continuous monitoring and proactive security recommendations for your entire MLOps infrastructure.
-
How does Azure DevTest Labs optimize MLOps testing?
Azure DevTest Labs optimizes MLOps testing by
-
Fast Environment Provisioning: It helps to create and manage test environments for model validation quickly.
-
Cost Controls: You can set up resource utilization and cost management policies.
-
Integration with Azure DevOps: It facilitates seamless integration with Azure DevOps for continuous testing and validation of ML models.
-
Can you mention a few scenarios where you would choose Azure Functions and AKS for deploying your ML model in Azure MLOps?
You can choose between Azure Functions and Azure Kubernetes Service for model deployment in Azure MLOps by considering certain factors, such as prediction volume, latency requirements, cost constraints, and existing infrastructure.
-
Azure Functions- Ideal for serverless deployments of models with low-latency, high-volume inference needs. Pay only for the executions, making it cost-effective for sporadic or event-driven predictions.
-
AKS- Suitable for more complex models with higher resource requirements or integration with existing containerized workflows. Offers greater control and customization over the deployment environment.
-
How would you use Azure Blob Storage efficiently for managing data within your MLOps pipeline?
You can leverage Azure Blob Storage for data management within your MLOps pipeline for several purposes-
-
Scalability and cost-effectiveness- You can employ Azure Blob Storage's scalability and tiered storage options to handle large-scale training data and archived model versions cost-effectively.
-
Data pre-processing and transformation- You can leverage Azure Databricks within Azure Blob Storage to perform data pre-processing and feature engineering tasks directly on the data, minimizing data movement and processing time.
-
Integration with AML Studio- You can seamlessly integrate Azure Blob Storage with AML Studio for data access and versioning throughout the ML lifecycle.
-
Secure data access- You can implement role-based access control and encryption for Azure Blob Storage to ensure secure data access and legal compliance.
-
Can you explain the significance of Azure Monitor and Azure Application Insights in MLOps workflows for monitoring ML models in production?
Azure Monitor and Azure Application Insights play crucial roles in MLOps by-
-
Azure Monitor- Collect and analyze telemetry data from various Azure resources, including AKS, to ensure optimal performance and identify potential issues.
-
Application Insights- Providing end-to-end visibility into application behavior and performance, helping MLOps teams detect anomalies, trace requests, and troubleshoot real-time issues.
-
How would you use Azure Data Factory for data pipelines within your MLOps workflow?
You can use Azure Data Factory (ADF) for MLOps data pipelines in the following ways-
-
Orchestrate data movement- You can utilize Data Factory's visual interface to build pipelines for data ingestion, pre-processing, and transformation for model training.
-
Schedule and automate tasks- You can schedule data pipeline execution based on triggers or at specific intervals to ensure timely data availability for model training and deployment.
-
Integrate with other services- You can connect Data Factory with Azure Machine Learning Studio and other Azure services for a unified data and MLOps workflow.
-
Scalability and cost efficiency- You can leverage Data Factory's managed service and pay-per-use model for cost-effective data pipeline management.
-
How would you monitor the performance of Azure Machine Learning models in production?

Source: learn.microsoft.com/
You can monitor the performance of Azure ML models in production using various methods-
-
Azure Monitor integration- You can track key metrics like accuracy, precision, recall, and latency using built-in monitoring capabilities within Azure Machine Learning Studio.
-
Customizable dashboards and alerts- You can create personalized dashboards to visualize performance metrics and set up alerts for anomalies or performance degradation.
-
Integration with Application Insights- You can utilize Application Insights for deeper monitoring and troubleshooting, analyzing logs and application traces for detailed insights.
-
Model explainability tools- You can use Azure Cognitive Services Explainable AI to understand model predictions and address potential bias issues.
-
How would you integrate your Azure MLOps pipeline with existing Azure services like Azure SQL Database and Azure Cognitive Services?
You can easily integrate your Azure MLOps pipeline with existing Azure services in various ways, such as
-
Azure SQL Database- You can use Azure Machine Learning's built-in connectors to import data directly from SQL databases for model training.
-
Azure Cognitive Services- You can utilize pre-trained Cognitive Services models within your pipeline for tasks like image recognition or text analysis, enhancing your ML features.
-
Data Factory integration- You can create Data Factory pipelines to automate data extraction from SQL databases and feed it into Azure Machine Learning Studio for training.
-
Cognitive Services for explainability- You can integrate Azure Cognitive Services Explainable AI to analyze predictions from your models and provide human-interpretable explanations.
-
What approach do you follow to ensure compliance with regulatory requirements like GDPR or HIPAA when building MLOps pipelines on Azure?
You can ensure legal compliance with GDPR or HIPAA for building Azure MLOps pipelines in several ways-
-
Data anonymization and encryption- You can implement data anonymization or encryption techniques to protect sensitive data throughout the MLOps pipeline.
-
Auditing and logging- You can maintain comprehensive audit logs to track data access, model deployments, and user activity for compliance audits.
-
Azure compliance offerings- You can utilize Azure's built-in compliance features and certifications relevant to your regulations.
-
Partner with compliance experts- You can seek guidance from experts familiar with the relevant regulations and best practices for implementing compliance controls within your MLOps workflow.
-
What is the role of Azure Key Vault in securing sensitive information within MLOps pipelines, and how can you leverage it for secure configuration management?
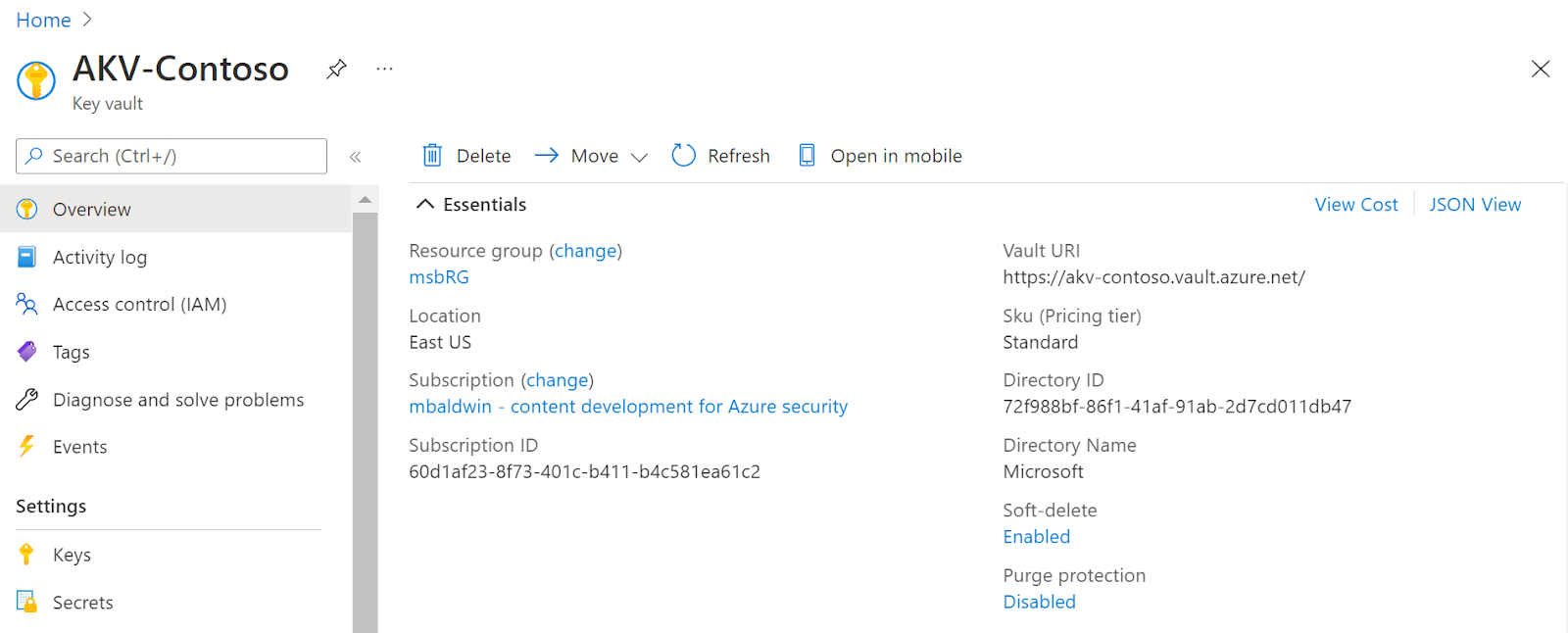
Source: learn.microsoft.com/
Azure Key Vault is crucial for securing sensitive information in MLOps pipelines. It is a secure repository for storing and managing sensitive data such as API keys and connection strings. In MLOps, Key Vault ensures secure configuration management by allowing teams to centralize and control access to sensitive data. This enhances security and compliance by preventing the exposure of sensitive information within configuration files or scripts.
MLOps Engineer Interview Questions And Answers
Before moving onto the interview questions and answers, here’s how Mikiko Bazeley, Head of AI Developer Relations, defines the responsibilities of an MLOps Engineer-

Source: https://medium.com/
This section explores questions tailored to test your skills in bridging data science and operations, designing end-to-end pipelines, automating model deployments, and ensuring security and compliance. These questions will prepare you to showcase your expertise and secure success in interviews for top MLOps engineering roles.
-
What role does an MLOps Engineer play in bridging the gap between the operations and data science teams?
MLOps Engineers play a crucial role in bridging the gap between data science and operations teams by
-
Collaborating with data scientists to understand model requirements.
-
Implementing scalable and reproducible model pipelines.
-
Ensuring seamless deployment and monitoring in production.
-
Facilitating communication between data science and operations teams for efficient MLOps workflows.
-
Can you describe the typical workflow of an MLOps Engineer?
The typical workflow of an MLOps Engineer involves the following key phases-
-
Collaborate with data scientists and engineers- An MLOps engineer understands model requirements, defines deployment strategies, and integrates models into production systems.
-
Automate model training and deployment- MLOps engineers build and maintain CI/CD pipelines for automated model builds, testing, and deployment.
-
Monitor and manage model performance- MLOps engineers track key metrics like accuracy, latency, and drift and take corrective actions when necessary.
-
Ensure infrastructure and resource optimization- An MLOps engineer efficiently manages and scales MLOps infrastructure, optimizing resource utilization and cost.
-
Implement security and compliance best practices- MLOps engineers secure model data, access, and deployments, ensuring compliance with relevant regulations.
-
Troubleshoot and resolve MLOps issues- An MLOps engineer diagnoses and fixes problems within the pipeline, model performance, or infrastructure.
-
Can you provide examples of how you have utilized a version control system like Git in your MLOps projects and how it contributes to collaborative development in your team?
Git is essential in MLOps projects for version control. You can use it to track changes in code, configuration files, and model artifacts. Branching strategies enable parallel development, enabling collaboration among team members. Commits, pull requests, and merge functionalities ensure a systematic and traceable development process. Git also facilitates rollback mechanisms, offering a safety net if issues arise during model deployments. Git plays a crucial role in maintaining a well-organized and collaborative MLOps workflow.
-
Can you share your experience with a specific cloud platform for MLOps, like AWS or Azure? How do you leverage cloud services to build and manage ML pipelines efficiently?
Let us say your expertise lies in Azure for MLOps. You can discuss leveraging Azure services such as Azure Machine Learning Studio, Azure DevOps, and Azure Kubernetes Service. Azure Machine Learning Studio streamlines model development, DevOps provides robust CI/CD pipelines, and AKS facilitates scalable and reliable model deployment. This cloud-native approach allows you to build end-to-end MLOps pipelines efficiently, ensuring seamless collaboration, automation, and scalability in deploying ML models.
-
Describe your proficiency in a programming language relevant to MLOps, such as Python. How do you use Python in your daily tasks as an MLOps Engineer?
Python is an integral part of your toolkit as an MLOps Engineer. You can use it for various tasks, including scripting for automation of model deployment pipelines, writing custom monitoring scripts, and developing utility tools for managing MLOps workflows. Python's extensive ecosystem, particularly with libraries like Flask for creating REST APIs and requests for handling HTTP requests, enhances your ability to design and implement robust and scalable MLOps solutions.
-
Can you elaborate on your experience with containerization tools like Docker and how you leverage them in MLOps workflows?
In your MLOps role, you can extensively use Docker for containerization. You can containerize ML models and their dependencies, ensuring consistency across development, testing, and production environments. Docker allows easy packaging of models into reproducible units, facilitating seamless deployment and scaling. This ensures that models run consistently across different environments, minimizing compatibility issues and streamlining the deployment process.
MLOps Interview Questions GitHub
If you are looking for more MLOps interview questions and resources, you must check out the following GitHub repositories-
MLOps Interview Questions And Answers: Next Steps With ProjectPro
Aced these MLOps interview questions? Ready to transform theory into practice? Understanding MLOps is crucial, but mastering it takes real-world experience. That's where ProjectPro comes in. Practice end-to-end solved Data Science and ML projects alongside industry experts, build your portfolio with real-world MLOps project solutions, and witness MLOps in action. From designing pipelines to deploying models, these enterprise-grade projects from the ProjectPro repository will help you gain the hands-on skills employers crave. So, why wait? Launch your MLOps career with ProjectPro and watch those interview offers flood in!
FAQs on MLOps Interview Questions And Answers
1. What are the prerequisites for learning MLOps?
The prerequisites for learning MLOps include having a strong foundation in machine learning concepts, proficiency in programming languages (such as Python), a solid understanding of cloud computing platforms (e.g., AWS, Azure), and familiarity with version control systems (e.g. Git). Additionally, knowledge of containerization tools (e.g., Docker) and continuous integration/continuous deployment (CI/CD) practices is beneficial for a comprehensive understanding of MLOps workflows.
2. Does MLOps require coding?
Yes, MLOps requires coding. Proficiency in programming languages, e.g. Python, is crucial for model development, data preprocessing, and pipeline scripting. Additionally, knowledge of tools like Git, Docker, and continuous integration systems is essential for effective collaboration and automation in MLOps workflows. While not every MLOps professional needs to be a software engineer, coding skills enhance efficiency and collaboration in deploying and managing ML models.

About the Author

Daivi
Daivi is a highly skilled Technical Content Analyst with over a year of experience at ProjectPro. She is passionate about exploring various technology domains and enjoys staying up-to-date with industry trends and developments. Daivi is known for her excellent research skills and ability to distill