What is Hadoop 2.0 High Availability?
This article gives overview on Hadoop 2.0 High Availability feature that addresses the Single Point of Failure problem through multiple Namenodes.
Hadoop 1.0 was intensive and played a significant role in processing large data sets, however it was not an ideal choice for interactive analysis and was constrained for machine learning, graph and memory intensive data analysis algorithms. In one of our previous articles we had discussed about Hadoop 2.0 YARN framework and how the responsibility of managing the Hadoop cluster is shifting from MapReduce towards YARN. Here we will highlight the feature - high availability in Hadoop 2.0 which eliminates the single point of failure (SPOF) in the Hadoop cluster by setting up a secondary NameNode. If you are new to Hadoop learning read our previous articles to get an overview on What is Big Data & Why Hadoop, Hadoop Architecture and Its Components.
The early adopters of Hadoop 1.0 – Google, Facebook and Yahoo, had to depend on the joint venture of Resource Management Environment, HDFS and the Map Reduce programming. The partnership among these technologies added value to the processing, managing and storage of Semi Structured, Structured and Unstructured Data in the Hadoop Cluster for these data giants.

Hadoop Project to Perform Hive Analytics using SQL and Scala
Downloadable solution code | Explanatory videos | Tech Support
Start ProjectHowever, the limitations in the Hadoop Map Reduce pairing paved way for Hadoop 2.0. For instance, Yahoo reported that Hadoop 1.x is not able to pace up with flood of information they were collecting online due to the Map Reduce’s batch processing format and the NameNodes SPOF had always been a bothersome issue in case of failures.
Table of Contents
- Hadoop 2.0 – An Overview
- Hadoop NameNode High Availability problem
- What is high availability in Hadoop?
- Hadoop Users Expectations from Hadoop 2.0 High Availability
- Short Quiz on Hadoop High Availability
- Hadoop 2.0 High Availability Feature –AvatarNode Implementation at Facebook to solve the availability problem

Hadoop 2.0 – An Overview
Hadoop 2.0 boasts of improved scalability and availability of the system via a set ofbundled features that represent a generational swing in the Hadoop Architecture with the introduction of YARN
Hadoop 2.0 also introduces the solution to the much awaited High Availability problem.
- Hadoop introduced YARN - that has the ability to process terabytes and Petabytes of data present in HDFS with the use of various non-MapReduce applications namely GIRAPH and MPI.
- Hadoop 2.0 divides the responsibilities of the overloaded Job Tracker into 2 different divine components i.e. the Application Master (per application) and the Global Resource Manager.
- Hadoop 2.0 improves horizontal scalability of the NameNode through HDFS Federation and eliminates the Single Point of Failure Problem with the NameNode High Availability​
New Projects
Hadoop NameNode High Availability problem:
Hadoop 1.0 NameNode has single point of failure (SPOF) problem- which means that if the NameNode fails, then that Hadoop Cluster will become out-of-the-way. Nevertheless, this is anticipated to be a rare occurrence as applications make use of business critical hardware with RAS features (Reliability, Availability and Serviceability) for all the NameNode servers. In case, if NameNode failure occurs then it requires manual intervention of the Hadoop Administrators to recover the NameNode with the help of a secondary NameNode.
Here's what valued users are saying about ProjectPro

Ray han
Tech Leader | Stanford / Yale University

Gautam Vermani
Data Consultant at Confidential
Not sure what you are looking for?
View All ProjectsNameNode SPOF problem limits the overall availability of the Hadoop Cluster in the following ways:
- If there are any planned maintenance activities of hardware or software upgrades on the NameNode then it will result in overall downtime of the Hadoop Cluster.
- If any unplanned event triggers, which results in the machine crashing, then the Hadoop cluster would not be available unless the Hadoop Administrator restarts the NameNode.
What is high availability in Hadoop?
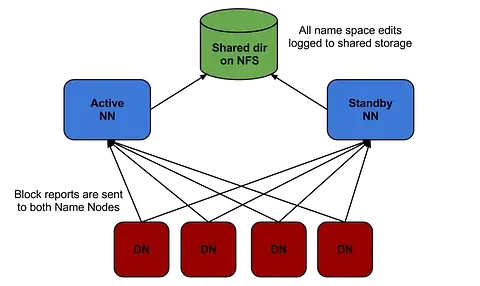
Hadoop 2.0 overcomes this SPOF shortcoming by providing support for multiple NameNodes. It introduces Hadoop 2.0 High Availability feature that brings in an extra NameNode (Passive Standby NameNode) to the Hadoop Architecture which is configured for automatic failover.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization
The main motive of the Hadoop 2.0 High Availability project is to render availability to big data applications 24/7 by deploying 2 Hadoop NameNodes –One in active configuration and the other is the Standby Node in passive configuration.
Earlier there was one Hadoop NameNode for maintaining the tree hierarchy of the HDFS files and tracking the data storage in the cluster. Hadoop 2.0 High Availability allows users to configure Hadoop clusters with uncalled- for NameNodes so as to eliminate the probability of SPOF in a given Hadoop cluster. The Hadoop Configuration capability allows users to build clusters horizontally with several NameNodes which can operate autonomously through a common data storage pool, thereby, offering better computing scalability when compared to Hadoop 1.0
With Hadoop 2.0, Hadoop architecture is now configured in a manner that it supports automated failover with complete stack resiliency and a hot Standby NameNode.
Image Credit :blog.cloudera.com
From the above graph, it is evident that both the active and passive (Standby) NameNodes have state-of-the-art metadata that ensures flawless failover for large Hadoop clusters indicating that there would not be any downtime for your Hadoop cluster and it will be available all the time.
Hadoop 2.0 is keyed up to identify any failures in NameNode host and processes, so that it can automatically switch to the passive NameNode i.e. the Standby Node to ensure high availability of the HDFS services to the Big Data applications. With the advent of Hadoop 2.0 HA it’s time for Hadoop Administrators to take a breather, as this process does not require manual intervention.
With HDP 2.0 High Availability, the complete Hadoop Stack i.e. HBase, Pig, Hive, MapReduce, Oozie are equipped to tackle the NameNode failure problem- without having to lose the job progress or any related data. Thus, any critical long running jobs that are scheduled to be completed at a specific time will not be affected by the NameNode failure.
Get More Practice, More Big Data and Analytics Projects, and More guidance.Fast-Track Your Career Transition with ProjectPro
Hadoop Users Expectations from Hadoop 2.0 High Availability
When Hadoop users were interviewed about the High Availability Requirements from Hadoop 2.0 Architecture, some of the most common High Availability requirements that they came up with are:
-
No Data Loss on Failure/No Job Failure/No Downtime
Hadoop users stated that with Hadoop 2.0 High Availability should ensure that there should not be any impact on the applications due to any individual software or hardware failure.
-
Stand for Multiple Failures -
Hadoop users stated that with Hadoop 2.0 High Availability the Hadoop Cluster must be able to stand for more than one failure simultaneously. Preferably, Hadoop configuration must allow the administrator to configure the degree of tolerance or let the user make a choice at the resource level - on how many failures can be tolerated by the cluster.
-
Self Recovery from a Failure
Hadoop users stated that with Hadoop 2.0 High Availability, the Hadoop Cluster must heal automatically (self healing) without any manual intervention to restore it back to a highly available state after the failure, with the pre-assumption that sufficient physical resources are already available.
-
Ease of Installation
According to Hadoop users, setting up High Availability should be a trifling activity devoid of requiring the Hadoop Administrator to install any other open source or commercial third party software.
-
No Demand for Additional Hardware Requirements
​ Hadoop users say that Hadoop 2.0 High Availability feature should not demand that the users deploy, maintain or purchase additional hardware. 100% Commodity hardware must be used to achieve high availability i.e. there should not be any further dependencies on non commodity hardware such as Load Balancers.
Become a Hadoop Developer By Working On Industry Oriented Hadoop Projects
Short Quiz on Hadoop High Availability
1) Hadoop 2.2 has how many Namenodes?
Hadoop 2.2 has two Namenodes- Active Namenode and Passive Namenode.
2) Which of the following is true about Hadoop High Availability?
i) Hadoop High Availability feature tackles the namenode failure problem only for the MapReduce component in the hadoop stack.
ii) Hadoop High Availability feature supports only single Namenode within a Hadoop cluster.
iii)Hadoop High Availability feature tackles the namenode failure problem for all the components in the hadoop stack.
Answer - iii
Hadoop 2.0 High Availability Feature –AvatarNode Implementation at Facebook to solve the availability problem
Facebook is a fast growing large data organization that has close to 500 million active users who share more than 30 billion pieces of content on the web in the form of blog posts, photos, news stories, links, comments, etc. Approximately people spend 700 billion minutes on Facebook per month and this data is said to double semi annually. How does Facebook render high availability to such a huge database of users? Facebook uses Hadoop 2.0 High Availability feature to ensure that 100 Petabytes of data is online 24/7 with the use of the special AvatarNode.
Ashish Thusoo, Engineering Manager at Facebook, stated at the Hadoop Summit that “Facebook uses Hadoop 2.0 and Hive extensively to process large data sets. This infrastructure is used for a variety of different jobs - including adhoc analysis, reporting, index generation and many others. We have one of the largest clusters with a total storage disk capacity of more than 20PB and with more than 23000 cores. We also use Hadoop and Scribefor log collection, bringing in more than 50TB of raw data per day. Hadoop has helped us scale with these tremendous data volumes.”
In the HDFS architecture, all the file system metadata requests are passed through a single server known as the NameNode and the file system sends and receives data through a group of Data Nodes. The presence of Data Nodes in the HDFS architecture is redundant and at any given point of time the file system can afford to handle the failure of a Data Node, however, if the NameNode is down then the overall functionality of the HDFS will be at stake and any of the applications connected to it will cease to operate.
Andrew Ryan, Hadoop professional at Facebook mentioned at one of the Hadoop Summit that “it is necessary for a large organization like Facebook to understand the degree and level of ‘NameNode as a Single Point of Failure’ so that they can build a solution that will overcome the shortcomings of NameNode as SPOF”.
AvatarNode is Born to Address NameNode Problem

Image Credit:.slideshare.net
The limitation of SPOF with the HDFS architecture was overcome with the birth of AvatarNode at Facebook. Wondering why it has such an unusual name?
Dhruba Borthakur, a famed HDFS developer at Facebook has named it after the James Cameron movie “Avatar” released then in 2009 - during the birth of AvatarNode.
AvatarNode has been contributed by Facebook as open source software to the Hadoop Community, to offer highly available NameNode that has hot failover and failback. AvatarNode is a double node or can be called as two-node cluster that provides a highly available NameNode to the Big Data applications with a manual failover.
AvatarNode is now the heartthrob inside Facebook as it is a huge WIN to the NameNode SPOF problem. AvatarNode is running heavy production workloads and contributes to improved administration and reliability of Hadoop Clusters at Facebook.
Build an Awesome Job Winning Project Portfolio with Solved End-to-End Big Data Projects
Hadoop 2.2 is now supported on Windows that is now craving interest from organizations that are dedicated to Microsoft platforms only. There is no doubt that there would be growing pains as organizations migrate to the latest release of Hadoop, however the basic changes to the MapReduce framework will add value for Hadoop in Big Data set-ups. Hadoop 2.0 is just a messenger of the growing technology and a revitalized concept for building and implementing Big Data Applications. There is anticipation for various tools that will make the most of the Hadoop 2.0 High Availability and the new HDFS Architecture will support features in YARN.
Related Posts
- How much Java is required to learn Hadoop?
- Top 100 Hadoop Interview Questions and Answers 2016
- Difference between Hive and Pig - The Two Key components of Hadoop Ecosystem
- Make a career change from Mainframe to Hadoop - Learn Why
- Apache Kafka Architecture and Its Components-The A-Z Guide
- Kafka vs RabbitMQ - A Head-to-Head Comparison for 2021

About the Author

ProjectPro
ProjectPro is the only online platform designed to help professionals gain practical, hands-on experience in big data, data engineering, data science, and machine learning related technologies. Having over 270+ reusable project templates in data science and big data with step-by-step walkthroughs,