Hadoop Short Tutorials
These short Hadoop tutorials compiled by DeZyre are powerful instructional tools that will serve as a helpful memory guide to professionals, even after they have completed their Hadoop training online. These Hadoop tutorials enhance online Hadoop training with continuous blended learning so that professionals can get in-depth insights into a specific Hadoop concept introduced in the class. These short tutorials are a great opportunity for practicing and reviewing the concepts learnt in the Hadoop training class.
Hadoop tutorials are aimed at providing solutions to specific problems in a short amount of time. However, for professionals to gain additional experience working on each and every component in the Hadoop ecosystem, tutorials would not suffice. Professionals ought to work on multiple Hadoop projects to stimulate creative and problem-solving approach when working with Hadoop. Hadoop online training fosters and instills the ground work on working with big data projects. DeZyre's Hackerday aims at corroborating the concepts learnt in Hadoop training class and implementing them with a fresh perspective to business challenges.
Hackerday provides experience working on different components in the Hadoop ecosystem so candidates can highlight multiple projects under their Hadoop experience belt in the resume.
What is the difference between a Hadoop database and a traditional Relational Database?
Often people confuse hadoop with a database but hadoop is not a database instead it is a distributed file system for storing and processing large amounts of structured and unstructured data. The major difference between a traditional RDBMS and hadoop lies in the type of data they handle. RDBMS handle only relational data whilst Hadoop works well with unstructured data and provides support for different data formats like Avro, JSON, XML, etc. Hadoop and RDBMS have similar functionalities like collecting, storing, processing, retrieving and manipulating data, they both are different in the manner of processing data.
RDBMS works well with small/medium scale defined database schema for real-time OLTP processing but it does not deliver fast results with vertical scalability even after adding additional storage or CPU’s. To the contrary, Hadoop effectively manages large sized structured and unstructured data in parallelism with superior performance at high fault-error tolerance rendering credible results at economical cost.
If you would like to get in-depth insights on how hadoop differs from RDBMs, enrol now for Online Hadoop Training.
What is the easiest way to install hadoop?
For a beginner getting started with Hadoop who is trying to create hadoop clusters on Linux server there are several modes in which they can install hadoop on Ubuntu. Usually, people learning hadoop install it in Pseudo-Distributed Mode. The process for installing hadoop on Ubuntu depends on the flavour of Linux we are using and the hadoop distribution you are working with. The standard process to follow for hadoop installation is –
- Install Java
- Setup password less SSH between the root accounts on all nodes.
- Install the hadoop distribution package repository.
- Every hadoop distributions comes with installation instruction manual.
However, the above process to install hadoop is usually followed in production implementation. The easiest way to install hadoop on Ubuntu for learning hadoop is mentioned under this Step-By-Step Hadoop Installation Tutorial .
What is the significance of a Job Tracker in hadoop?
Job Tracker is the core process involved in the execution of Hadoop MapReduce jobs. On a given Hadoop cluster, only one job tracker can run that submits and tracks all the MapReduce jobs. Job Tracker always runs on a separate node and not on the DataNode. The prime functionality of a job tracker is to manage the task trackers (resource management), track the availability of resources (locating task tracker nodes that have available slots for data), and task life cycle management (fault tolerance, tracking the progress of jobs, etc.).
Job Tracker is a critical process within a Hadoop cluster because the execution of hadoop MapReduce jobs cannot be started until the Job Tracker is up and running. When the Job Tracker is down, the HDFS will still be functional but the execution of MapReduce jobs will be halted.
How to install Hadoop on Ubuntu?
Short Hadoop Tutorial for Beginners - Steps for Hadoop Installation on Ubuntu
- Update the bash configuration file present - $HOME/.bashrc
- Configure the Hadoop Cluster Configuration files – hadoop-env.sh, core-site.xml, mapred-site.xml and hdfs-site.xml.
- Format HDFS through NameNode using the NameNode format command.
- Start the Hadoop cluster using the start-all.sh shell script. This will start the NameNode, DataNode, Task Tracker and Job Tracker.
- If you want to stop the Hadoop Cluster, you can run the stop-all.sh script to stop running all the daemons.
- Now, you can run any Hadoop MapReduce job.
Read more for detailed instructions on Installing Hadoop on Ubuntu
What are the most popular hadoop distributions available in the market?
Popular Hadoop distributions include –
- Cloudera Hadoop Distribution
- Hortonworks Hadoop Distribution
- MapR Hadoop Distribution
- IBM Hadoop Distribution
- Pivotal
- Amazon
Read More about Hadoop Distrbutions and Popular Hadoop Vendors
What is a DataNode in Hadoop?
DataNode also referred to as the Slave in Hadoop architecture is the place where the actual data resides. DataNode in the Hadoop architecture is configured with lots of hard disk space because it is the place for the actual data to be stored. DataNode continuously communicates with the NameNode through the heartbeat signal. When a DataNode is down, the availability of data within the hadoop cluster is not affected. The NameNode replicates the blocks managed by the DataNode that is down.
Sample DataNode Configuration in Hadoop Architecture
Processors: 2 Quad Core CPUs running @ 2 GHz
Network: 10 Gigabit Ethernet
RAM: 64 GB
Hard Disk 12-24 x 1TB SATA
Is Namenode a Commodity Hardware in Hadoop?
The complete Hadoop Distributed File System relies on the Namenode , so Namenode cannot be a commodity hardware. Namenode is the single point of failure in HDFS and has to be a high availability machine and not a commodity hardware.
What HDFS features make it an ideal file system for distributed systems?
- HDFS has good scalability i.e. data transfer happens directly with the DataNodes so the read/write capacity scales well with the number of DataNodes.
- Whenever there is need for disk space, just increase the number of DataNodes and rebalance it.
- HDFS is fault tolerant, data can be replicated across multiple DataNodes to avoid machine failures.
- Many other distributed applications like HBase, MapReduce have been built on top of HDFS.
Does Hadoop require SSH passwordless access ?
Apache Hadoop in itself does not require SSH passwordless access but hadoop provided shell scripts such as start-mapred.sh and start-dfs.sh make use of SSH to start and top daemons. This holds good in particular when there is a large hadoop cluster to be managed. However, the daemons can also be started manually on individual nodes without the need of SSH script.
How will you check if hadoop hdfs is running or not ?
Use the following steps to check if HDFS is running or not –
List all the active daemons using the jps command. The most appropriate command would be –
hadoop dfsadmin –report
The above command will list all the details of data nodes which is nothing but the hdfs.
Or you can also use the cat command with any filename available at the HDFS location.
How well does Apache Hadoop scale ?
The tiny toy elephant’s scalability has been validated on hadoop clusters of up to 4000 nodes . Sort performance of hadoop on 900 nodes, 1400 nodes and 2000 nodes is good and it takes approx. 1.8 hours, 2.2 hours and 2.5 hours to sort 9TB, 14TB and 20TB of data respectively.
Is it always necessary to write MapReduce jobs in Java programming language?
There are different ways to write a mapreduce job by incorporating non-java code.
- Use a JNI based C API libhdfs for communicating with HDFS.
- Use HadoopStreaming utility that allows any shell command to be used as a map or a reduce function.
- You can also write map-reduce jobs using a SWIG compatible C++ API known as Hadoop Pipes.
Is it possible to recover the filesystem from datanodes if the namenode loses its only copy of the fsimage file?
No it is not possible to recover the filesystem from datanodes if the namenode loses its only copy of the fsimage file. This is the reason it is always suggested to configure dfs.namenode.name.dir to write to two filesystems on different physical hosts and make use of the secondary Namenode.
How will you copy a file form your local directory to HDFS ?
The following syntax can be used on the Linux command line to copy the file -
hadoop fs -put localfile hdfsfile
OR
hadoop fs -copyFromLocal localfile hdfsfile
If there is a used 64MB block size and you write a file that uses less than 64MB , will the total 64MB of disk space be consumed?
When writing a file in HDFS , there are two types of block sizes -one is the underlying file systems block size and the other is the HDFS's block size.The underlying file system will store the file as increments of its block size on the actual raw disk so it will not consume the complete 64MB of disk space.
In HDFS, why is it suggested to have very few large files rather than having multiple small files?
The Namenode contains metadata about each and every file in HDFS. If the number of files is more, more will be the metadata. Namenode loads all the metadata information in-memory for speed, thus having many small files will make the metadata information big enough that will exceed the size of the memory on the Namenode.
What is hadoop used for ?
i) For processing really BIG DATA - If the business use-case you are tackling has atleast terabytes or petabytes of data then Hadoop is your go-to framework of choice. There are tons of other tools available for not-so large datasets.
ii) For stroing diverse data - Hadoop used for storing and processing any kind of data be it plain text files, binary format files, images.
iii) Hadoop is used for parallel data processing use-cases.
If we have 100 GB file in HDFS and we want to make a hive table out of that data what will be the size of that table and where will it be stored?
If it is a 100GB file then it should be created as an Hive External Table. When creating a Hive External Table , the data itself will be stored on HDFS in the specified filepath but Hive will create a map of the data in the metastore and the managed table will store data in Hive. Instead of speciifying just the filepath , one can also specify a directory of files as long as they have the same strcuture.
What is the difference between Hadoop Mapreduce, Pig and Hive?
MapReduce vs Pig vs Hive - Professionals learning hadoop are likely to work with these 3 important hadoop components when writing Hadoop jobs. Programmers who know java, prefer to work directly hadoop mapreduce whilst others from a database background work with Pig or Hive components in the hadoop ecosystem. The major difference here is that Hadoop MapReduce is a compiled language based programming paradigm whereas Hive is more like SQL and Pig is a scripting language.Considering in terms of the development efforts that programmers have to spend when working with these hadoop components - pig and hive require less development effort than mapreduce programming.
What is Hadoop 2.0 YARN?
Hadoop 2.0 has improved from Hadoop 1.0's restricted processing model of batch oriented MapReduce jobs to more interactive and specialized processing models. Hadoop 2.0 has seen significant increase in the HDFS distributed storage layer and high availability. YARN [Yet Another Resource Negotiator] is a cluster management technology which is used to split up the two primary responsibility of the Job Tracker - resource management and job scheduling/monitoring into separate daemons. This enables Hadoop to support more varied processing approaches and a wide array of applications. With YARN, Hadoop clusters can now run interactive querying, streaming data application while simultaneously running batch oriented Hadoop MapReduce jobs.
What is a NoSQL Database?
NoSQL Databases - as the name suggests is 'not SQL' database. Any database which is not modeled after relational databases in tabular format with defined schemas - is a NoSQL database. NoSQL databases works on the paradigm that there are alternate storage solutions or mechanisms available when particular software is designed, that can be used based on the needs of the type of data. The data structures used by NoSQL databases like key/value pairs, graphs, documents, etc. differ from relational databases which makes operations on NoSQL databases faster. NoSQL databases solves the problems that relational databases were not able to cope with - increasing scale of data storage and agility, fast computing processes and cheap storage.
What is the difference between Hadoop and traditional Relational Database?
Hadoop is not a database. Hadoop is a Distributed File System (HDFS). Hadoop will let you store extensive amount of data files on remote machines. Above the layer of Distributed File System, Hadoop has an API which is used for processing the stored data files. This is known as MapReduce. Since Hadoop doesn't require any data modelling, it is ideal for storing vast amount of unstructured data.Whereas in a traditional Relational Database (RDBMS), the handling is limited to relational data. RDBMS would not do much good for unstructured data and won't support multiple serializations and data formats. However traditional databases offer the following four properties (ACID)- Atomicity, Consistency, Isolation and Durability.
What is Hadoop Master Slave architecture?
Hadoop uses a master-slave architecture for both distributed computation and storage. For the distributed storage, the NameNode is master and the DataNodes are the slaves. While in the case of distributed computation, the JobTracker is the master and the TaskTracker are the slaves. In relation to Hadoop, a Job is a term for complete Hadoop execution of a user request. JobTracker is a program which manages and coordinates the jobs. Taking job submissions from clients, job control and monitoring and distribution of tasks in a job are all managed by Jobtracker. On the other hand, TaskTracker manages the tasks involved in the job. For example, reduce task, map task, etc. There can be one or more TaskTracker processes per node in a cluster.
What is the difference between JobTracker and TaskTracker
The JobTracker is responsible for taking in requests from a client and assigning Task tracker which task to be performed, whereas the TaskTracker accepts task from the JobTracker. The task tracker keeps sending a heartbeat message to the job tracker to notify that it is alive.
What are NameNodes and DataNodes?
Name node is the master node which has all the metadata information. It contains the information about no. of blocks, size of blocks, no. of vacant blocks, no. of replicated blocks etc. DataNode is a slave node, which sends information to the Name node about the files and blocks stored in and responds to the Name node for all file.
What is the recommended Hardware requirement for efficient execution of Hadoop?
Any Hadoop cluster will have these basic 4 roles; NameNode, JobTracker, TaskTracker and DataNode. The machines in the cluster will perform the task of Data storage and processing. In order to operate DataNode/TaskTracker in a balanced Hadoop cluster, the below mentioned configuration is recommended: -- 64 to 512 GB of RAM -- 2 quad-/hex-/octo-core CPUs (Minimum Operating Frequency 2.5 GHz) -- 10 Gigabit Ethernet or Bonded Gigabit Ethernet -- 12-24 1-4TB hard disks in a JBOD Hardware requirement for running NameNode and JobTracker are relaxed in terms of RAM size and memory, nearly one third; though it depends upon the requirement and redundancy.
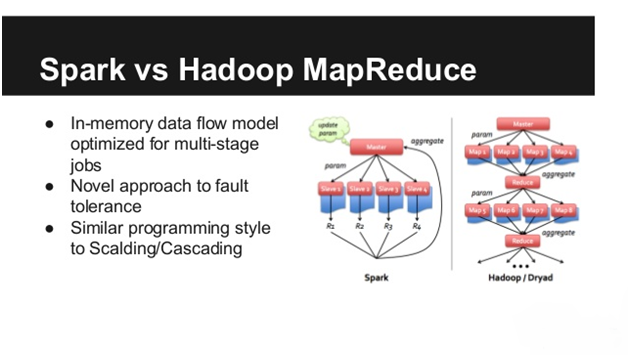
When is MapReduce preferred over Spark?
Hadoop MapReduce is a programming paradigm designed for database that exceeds the system memory, whereas on dedicated clusters Spark has less latency especially when all the data can be stored in system memory. In terms of ease of use, Hadoop MapReduce is difficult to program compared to Spark, but since it is widely used in Industry, a lot of tools are available to make it easier. Both of the technology offer more or less same amount of compatibility for data types and sources. As a conclusion, Hadoop MapReduce is better suited for Batch Processing whereas Spark is meant for Data Processing.
Comparison between Normal and Sequential MapReduce jobs?
In a normal MapReduce job the task is divided in different nodes and executed simultaneously. This parallel processing is a key feature for MapReduce, where the consequential jobs are independent of each other and therefore can be executed simultaneously. As the name suggests in a Sequential MapReduce job, the data has to be processed from a single node at some point because there is no way of dividing the processing.
How to process MapReduce jobs using multiple Database?
One of the ways of reading more than one database simultaneously is to export the data from RDBMS as raw text files, followed by using MultipleInputs do process the jobs. However there is an alternate of using MultipleInputs. It is feasible to execute 2 map only jobs and then combining the output from these jobs at input to a final job which performs the necessary logical processing required for the reducer.
What are the InputFormats suitable for Hadoop?
InputFormats in Hadoop defines the method to read data from a file into the Mapper instances. There are multiple implementation of the InputFormats, they are suitable for text files and their various interpretations and suitable for reading particular binary file formats. InputFormats generates the key-value pair inputs for the mappers by parsing the input data. In Hadoop architecture, InputFormats is responsible for splitting the input data into logical partitions.
What is a JUnit testing framework?
This is a unit testing framework designed for Java Programming Language. Junit is used for test driven development and belongs to unit testing frameworks. JUnit is linked as a JAR at compile-time; the framework resides under package junit.framework for JUnit 3.8 and earlier, and under package org.junit for JUnit 4 and later.
How does PIG use Hadoop MapReduce environment?
MapReduce acts as an execution engine for PIG latin commands that are translated into MR jobs by PIG system. PIG is more of a translator and no execution of job or task is done by PIG. For a better understanding, we can create an analogy between PIG and Hadoop like Compiler and OS, respectively. Since we create commands through PIG and it translates those latin commands before delegating the jobs to Hadoop, PIG acts like a compiler. Whereas Hadoop acts like an OS, which executes the commands (MR jobs), being monitored by PIG. PIG uses Hadoop's API for implementation of operators. Pig Latin provides a set of standard data-processing operations, such as join, filter, group by, order by, union, etc which are then mapped to map-reduce jobs.
What is the relationship between Hadoop's Hive, PIG, HDFS and MapReduce?
In simple words, PIG is an application that makes MR jobs based on commands given in Pig Latin Language. Similarly, Hive is also an application which creates Tex jobs based on SQL commands given in Hibernate Query Language (HQL). On the other hand, Hadoop is a collective term which describes an ecosystem for distributed computing tools focused around Hadoop Distributed File Systems. The one thing similar in all of the above mentioned technologies, is that these are high level languages to facilitate large-data processing.
How to parse complex data type in PIG?
The simplest approach to parse complex data types in PIG is to use the following command:
REGEX_EXTRACT_ALL
The above mentioned command can be used in the following way:
***
A = LOAD B FROM '...' USING TextLoader() AS (line:chararray);
B = FOREACH A GENERATE REGEX_EXTRACT_ALL(line,'^..zone_id..(\d*)..position..(\d*),(\d*),(\d*)..$);
***
Here we are using TextLoader to read one line at once into chararray. The address of the file is to be written in place of '...'. Following TextLoader, the FOREACH command, woudl repeat the REGEX command for every line that was read using TextLoader. The command REGEX_EXTRACT_ALL pulls each group from within the paranthesis and returns it into a tuple.
What is the difference between HIVE and RDBMS?
RDBMS works on schema on write time, on the other hand Hive enforces schema on read time. Hive is similar to the traditional database which supports sequential query language interface but it is more of a data warehouse instead of a Database. RDBMS is suitable for Read and Write many times operation where Hive is designed for Write once and read many times. RDBMS allows indexing, transactions, insertion and deletion of record level updates, but Hive doesn't support all these features. This is because Hive was designed to operate over HDFS data using MapReduce. One of the crucial differences between Hive and RDBMS is, the former provides more than 100 Petabyte of maximum data size whereas the latter just supports 10's of Terabyte of data at maximum.
HiveQL query to execute joining of multiple tables.
Let us assume there are 4 tables with name p,q,r,s and all these tables have a common column "ObjectId". The objective is to join all these tables together in HIveQL using JOIN ON command.
Syntax:
SELECT p.column1, q.column1, r.column1, s.column1 FROM p JOIN q ON (p.ObjectId=q.ObjectId) JOIN r ON (r.ObjectId=q.ObjectId) JOIN s ON (s.ObjectId=r.ObjectId)
How to convert CamelCase data into snake_case data using HiveQL?
The data being used in HiveQL is case independent. Hive parser doesn't discrimated between upper or lower case letters. Therefore for to and from CamelCase conversion, the 'to_json' and 'from_json' take and extra boolean argument, which acts as a flag for conversion. This allows to ouput the format in the required case.
Syntax:
select
to_json(
named_struct("camel_case",1,"check_casing",2)
from table_name;
Output:
{"CamelCase":1,"Check_Casing":2}
What is Hive UDF?
UDF is a user defined function that can be written in Hive to extract and manipulate data from Hadoop. Mostly these UDF are written in Java but you can also use build tools of another language for translation. Hive UDF (user defined function) are a way to extend the functionality of Hive with a Java written function which can be compiled in HiveQL statements.
How to install Sqoop on a client/edge node?
Sqoop makes up from two separate parts- Client and Server. It is required to install Sqoop server on a single node in your cluster. That node will serve as an entry point for all connecting Sqoop points. Server behaves like a MapReduce client and hence it is required to install Hadoop and configure it on machine which is hosting Sqoop server.
However, Sqoop clients doesn't need any extra configuration and installation. All that is required is to copy paste Sqoop distribution artifact on the client/edge machine and unzip it in desired directory. The client can be initiated using the following command:
bin/sqoop.sh client
How to load data from RDBMS using Sqoop import command?
Sqoop import command lets you import data from RDBMS to HDFS, Hive and HBase. The following examples will let you store data in HDFS.
1. For Postgres
sqoop import --connect jdbc:postgresql://postgresHost/databaseName
--username username --password 123 --table tableName
2. For MySQL
sqoop import --connect jdbc:mysql://mysqlHost/databaseName --username username --password 123 --table tableName
3. For Oracle
sqoop import --connect jdbc:oracle:thin:@oracleHost:1521/databaseName --username USERNAME --password 123 --table TABLENAME
What is the difference between Sqoop and Flume?
Even though both Sqoop and Flume are used for data transfer but there are key differences like aggregation and memory usage which can define their usage. Flume is a reliable, distributed service for effectively joining, aggregating and transferring large chunks of log data. Whereas, Apache Sqoop is designed for effectively moving bulk data among Apache Hadoop and structured database.
Flume can collect data from various sources like Directory, jms and logs and data collection can be scaled horizontally by using multiple Flume machines. Sqoop's job is to transfer data between Hadoop and other database and it transfer data in parallel for increased efficiency.
How to install Sqoop in a machine with Windows Operating System?
Sqoop is a tool used for data transfer to and fro RDBMS and HDFS. In order to install Sqoop on a Windows machines, first download the latest version of sqoop from online Apache repository.
-- Extract the Apache Sqoop Binary file in to the root directory
-- Specify SQOOP_HOME and add sqoop path variable
export SQOOP_HOME="/Dezyre/hadoop/sqoop-1.4.3"
export PATH=$PATH:$SQOOP_HOME/bin
You can test Sqoop installation by using following command:
$ sqoop help
How to install Sqoop in Ubuntu OS?
In order to install Sqoop, follow the below mentioned steps:
- Download the sqoop-1.4.4.bin_hadoop-1.0.0.tar.gz file from www.apache.org/dyn/closer.cgl/sqoop/1.4.4
- Unzip the tar: sudo tar -zxvf sqoop-1.4.4.bin hadoop1.0.0.tar.gz
- Move sqoop-1.4.4.bin hadoop1.0.0 to sqoop using command
user@ubuntu:~$ sudo mv sqoop 1.4.4.bin hadoop1.0.0 /usr/local/sqoop - Create a directory sqoop in usr/lib using command
user@ubuntu:~$ sudo mkdir /usr/lib/sqoop - Go to the zipped folder sqoop-1.4.4.bin_hadoop-1.0.0 and run the command
user@ubuntu:~sudo mv ./* /usr/lib/sqoop - Go to root directory using cd command
user@ubuntu:~$ cd - Open bashrc file using
user@ubuntu:~$ sudo gedit ~/.bashrc - Add the following lines
export SQOOP_HOME=¡usr/lib/sqoop
export PATH=$PATH:$SQOOP_HOME/bin - To check if the sqoop has been installed successfully type the command
$ sqoop version
What are the main components of a Hadoop Application?
A hadoop application can have multiple components integrated into the big data solution to solve complex business logic. However, the main components of a Hadoop application are Hadoop HDFS for storing data and hadoop MapReduce for processing data. A hadoop application is incomplete without these two hadoop components. HDFS consists of NameNode’s and DataNodes
- NameNode is the master of the hadoop distributed file system which manages the blocks present on the data nodes and also maintains the file metadata and file modifications.
- DataNodes are the slaves of the HDFS architecture which provide actual storage and serve the read/write requests for the clients.
- HDFS also has a secondary NameNode that is responsible for performing periodic checkpoints so whenever the NameNode fails, the checkpoint can be used to restart the NameNode.
- JobTracker is the master of Hadoop MapReduce component that manages the jobs and the resources within the hadoop cluster.
- TaskTrackers run the map and reduce tasks as specified by the JobTracker.
- JobHistoryServer as the name indicates is a daemon that contains information about the completed applications.
What are NoSQL Databases?
NoSQL comprises of a database technology, which aims to provide efficient solutions to big data storage, data extraction, data analytic and performance. It is preferred over Relational Databases, because they were not designed to deal with the scalability of Big Data. NoSQL has four prominent Database types:
1. Document Databases
2. Graph Stores
3. Key-value Pairs
4. Wide-column Stores
NoSQL offers sclability and performance superiority over relational databases. NoSQL is capable of using structured, semi-structures and unstructured data. It also supports object oriented programming.
How does HBase works with HDFS?
HDFS stands for Hadoop Distributed File Systems and it has following characteristics:
1. HDFS is suitable for streaming access of files with big data sizes. Typically the size of files stored in HDFS are above 100 MBs and they are access through MapReduce.
2. HDFS files are write once files and read-many files.
Whereas HBase is a database that stores it's data in a distributed filesystem. HDFS is generally chosen as the preferred filesystem because of the integration between HBase and HDFS. HBase can also work on other filesystems. HBase has following characteristics:
1. Low latency access to small amounts of data from within a large data set. This means that a single rows access is done quickly from a billion row table.
2. Flexible data model to work with and data is indexed by the row key.
3. Fast scans across tables.
How to fix corrupt Hadoop HDFS?
The following command gives an list of problematic files.
hdfs fsck /
Once we have the list, we need to search through the output lis tto find corrupt of missing blocks. The following command will generate a meaningful output on a large HDFS.
hdfs fsck . | egrep -v '^\.+$' | grep -v eplica
The purpose of the above mentioned command is to find corrupt files, while ignoring lines with replication and lines only with dots. Once a corrupt file is found, then you need to locate its block by using the following command.
hdfs fsck /path/to/corrupt/files -location -block -files
How to use sorting in Apache Pig?
In Apache Pig, the function ORDER BY sorts a relation based on singular or multiple fields. Below mentioned is the syntax to sort using ORDER BY
relation1 = ORDER relation2 BY {*[ASC|DESC]|field_relation1[, field_relation2[ASC|DESC]...]}[PARALLEL n];
Here, ASC is used for sorting in ascending order whereas DESC is used for sorting in descending order.
What is MapReduce in simple terms?
MapReduce is a way to analyze bulk amount of data in parallel with no requirement of redundant scripting (usually looping) other than the required mapper and reduce function. The map function takes input data and gives out processed results. A large number of Map function tasks can be executed in parallel. The objective of the reduce function is to minimize the data-set vector to a scalar value.
For an example, consider the following SQL statement:
Select SUM(marks) FROM students WHERE marks>50 GROUP BY departmentname
For this example we can use map to filter the vector of students in order to obtain subset of students with marks greater than 50. Reduce will add up each of these groups and give you the required result.
How to import third party library in Python MapReduce?
While writing a MapReduce job in Python, you would wish to use some third party library (for example, chardet). For a Python MapReduce job, you need to import the third party library by using the "zipimport" command.
importer = zimimport.zimimporter('module.mod')
chardet = importer.load_module('library_name')
Add the following command in the Hadoop Streaminng:
-file module.mod
After this you can use the library in your Python script.
How to chain multiple MapReduce Jobs in Hadoop?
Consider a situation where you deal with a multi-step algorithm:
Map1, Reduce1, Map2, Reduce2, etc.
In such a case output of the first reduce can be used as an input to the second map. Once the pipeline has been successfully completed, the ideal action is to delete the intermediate data. Cascading jobs is the simplest way to do this. Consecutive jobs in MapReduce can be done using the following command:
JobClient.run(Job_Number)
First, create a JobConf object "1-job", which will represent the first job. Set the parameters with input data set and the output as "temp" in the output directory. For the consecutive job, follow the same procedure; except for second job set all the parameters to "temp" and "output" in the output directory.
JobClient.run(1-job) JobClient.run(2-job)
How to convert the output of HiveQL to a CSV file?
The following syntax can be used to convert the output of a Hive query to a csv output.
INSERT OVERWRITE LOCAL DIRECTORY '/home/lvermeer/temp'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
select books from table;
How to merge reducer outputs to a single file?
FileUtil.copyMerge can be used to merge multiple outputs after running MapReduce jobs. This method is used by running -getmerge command. FileUtil.copyMerge takes input of two FileSystems as an arguments and Path.getFileSystem is used to obtain an OutputStream to save the single merged output file.
Alternatively, a single output file can be created by setting just a singe reducer in the code.
Job.setNumberOfReducer(1);
How do I copy files from S3 to Amazon EMR HDFS?
The simplest way to copy any file straight from S3 to HDFS is to use Hadoop's "distcp" command.
% ${HADOOP_HOME}/bin/hadoop distcp s3n://Folder/Thefile /root/destinationfile
The above mentioned command will copy the file named "Thefile" from the S3 "Folder" bucket to /root/destinationfile in HDFS. This command will work assuming that S3 file system is being used in the "native" mode; which means that each object in S3 is accessible to Hadoop. However if S3 is being used in the block mode, then the same command can be used with slight altercations:
% ${HADOOP_HOME}/bin/hadoop distcp s3://Folder/Thefile /root/destinationfile
What are the differences between HDFS and FS (normal file system)?
When working with Hadoop HDFS, hadoopers often come across two syntaxes for querying HDFS –
1) Hadoop fs
2) Hadoop dfs
Usually on executing the commands on the command line, the output will be the same when executing various hadoop shell commands then why two different syntaxes for the same purpose is what often confuses hadoop developers. FS (File System) refers to a generic file system that will point to any other file system locally or even to HDFS. However, DFS (distributed file system) is specific to Hadoop HDFS and can perform operation only with HDFS and not any local file system.
How to create an external table in Hive?
Whenever developers need to process the data through ETL jobs and want tp load the resultant dataset into hive without manual intervention then external tables in Hive are used. External tables are also helpful when the data is not just being used by Hive but also other applications are using it. Here’s how we can create an External Table in Hive –
CREATE EXTERNAL TABLE ProjectPro_Course (
CourseId BIGINT,
CourseName String,
No_of_Enrollments INT
)
COMMENT ‘ProjectPro Course Information’
LOCATION /user/dezyre/datastore/ProjectPro_Course
The above piece of HiveQL code will create an external table in Hive named ProjectPro_Course. The location specifies where the data files would be put in.Name of the folder and the table name should always be the same.
What is the purpose of Hadoop Cluster Configuration files?
There are four hadoop cluster configuration files present in the hadoop/conf directory which should be configured to run HDFS. These configuration files should be modified accordingly based on the requirements of the Hadoop infrastructure. To configure Hadoop, the following four cluster configuration files have to be modified –
- Core-site.xml file – This cluster configuration file details on the memory allocated for HDFS, memory limit, size of the read and write buffers and the port number that will be used for Hadoop instance.
- Hdfs-site.xml – This cluster configuration file contains the details on where you want to store the hadoop infrastructure i.e. it contains NameNode and DataNode paths along with the value of replication data.
- Mapred-site.xml – This cluster configuration file contains the details on as to which MapReduce framework is in use. The default value for this is YARN.
- Yarn-site.xml – This cluster configuration file is used to configure YARN into Hadoop.
What kind of hardware scales best for Apache Hadoop?
Hadoop scales best with dual core machines or processors having 4 to 8 GB of RAM that use ECC memory based on the requirements of the workflow. The machines chosen for hadoop clusters must be economical i.e. they should cost ½ to 2/3 rd of the cost of production application servers but should not be desktop class machines. When purchasing hardware for Hadoop, the utmost criteria is look for quality commodity equipment so that the hadoop clusters keep running efficient. When buying hardware for hadoop clusters, there are several factors to be considered including the power, network and any other additional components that might be included in large high-end big data applications.
What is a NameNode in Hadoop architecture?
NameNode is the single point of failure (centrepiece) in a hadoop cluster and stores the metadata of the Hadoop Distributed File System. NameNode does not store the actual data but consists of the directory tree of all the files present in the hadoop distributed file system. NameNode in Hadoop is configured with lots of memory and is a critical component of the HDFS architecture because if the NameNode is down, the hadoop cluster becomes out-of-the-way.
With examples to enhance the effectiveness of understanding Hadoop concepts, these Hadoop tutorials include the most commonly encountered problems while working with Hadoop and include the solutions as well. Professionals can refer to these tutorials at any time, more like a helpful guide - if they get stuck with a particular Hadoop concept. These Hadoop tutorials help professionals briefly review the Hadoop sessions with the help of quick recaps, after they have understood the concepts in the class.
Hadoop Short Tutorials
- Similar to the online Hadoop training classes, these short Hadoop tutorials will not interfere with learner's time and the students can refer to these tutorials at any time during the class or after the class when practicing hands-on in Hadoop environment.
- These Hadoop tutorials are aimed at capturing 100% of learner's concentration on a specific topic. After completing Hadoop training, little details on each component in the Hadoop ecosystem do matter to work on a big data project and this is what the tutorials are aimed at.
- You can try and tweak the solution mentioned in the short tutorial as many times as you want. There is nobody to howl at you even if you practice and implement the solution any number of time unlike in a class where you have to follow the instructor. You only learn by experience and the tutorials serve this purpose.
Load More
-
![Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem]() Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem
Difference between Pig and Hive-The Two Key Components of Hadoop Ecosystem -
![Hadoop MapReduce vs. Apache Spark Who Wins the Battle?]() Hadoop MapReduce vs. Apache Spark Who Wins the Battle?
Hadoop MapReduce vs. Apache Spark Who Wins the Battle? -
![Top 50 Hadoop Interview Questions]() Top 50 Hadoop Interview Questions
Top 50 Hadoop Interview Questions -
![5 Job Roles Available for Hadoopers]() 5 Job Roles Available for Hadoopers
5 Job Roles Available for Hadoopers -
![Top 6 Hadoop Vendors providing Big Data Solutions in Open Data Platform]() Top 6 Hadoop Vendors providing Big Data Solutions in Open Data Platform
Top 6 Hadoop Vendors providing Big Data Solutions in Open Data Platform -
![Big Data Analytics- The New Player in ICC World Cup Cricket 2015]() Big Data Analytics- The New Player in ICC World Cup Cricket 2015
Big Data Analytics- The New Player in ICC World Cup Cricket 2015 -
![5 Reasons why Java professionals should learn Hadoop]() 5 Reasons why Java professionals should learn Hadoop
5 Reasons why Java professionals should learn Hadoop