







































Data Engineering Manager, Microsoft Corporation

Head of Data Science, Slated

Dev Advocate, Pinecone and Freelance ML

Senior Data Engineer, National Bank of Belgium
In this spark project, you will use the real-world production logs from NASA Kennedy Space Center WWW server in Florida to perform scalable log analytics with Apache Spark, Python, and Kafka.
Get started today
Request for free demo with us.
Schedule 60-minute live interactive 1-to-1 video sessions with experts.
Unlimited number of sessions with no extra charges. Yes, unlimited!
Give us 72 hours prior notice with a problem statement so we can match you to the right expert.
Schedule recurring sessions, once a week or bi-weekly, or monthly.
If you find a favorite expert, schedule all future sessions with them.
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
250+ end-to-end project solutions
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
15 new projects added every month
New projects every month to help you stay updated in the latest tools and tactics.
500,000 lines of code
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
600+ hours of videos
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
Cloud Lab Workspace
New projects every month to help you stay updated in the latest tools and tactics.
Unlimited 1:1 sessions
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
Technical Support
Chat with our technical experts to solve any issues you face while building your projects.
7 Days risk-free trial
We offer an unconditional 7-day money-back guarantee. Use the product for 7 days and if you don't like it we will make a 100% full refund. No terms or conditions.
Payment Options
0% interest monthly payment schemes available for all countries.
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic was "Credit Risk Modelling". To understand other domains, it is important to wear a thinking cap and that's where ProjectPro helped me. I also got a chance to talk to experts who have worked on these domains - they helped me by walking through the project. Kudos to the ProjectPro team!
Gautam Vermani
Data Consultant at Confidential
I think that they are fantastic. I attended Yale and Stanford and have worked at Honeywell,Oracle, and Arthur Andersen(Accenture) in the US. I have taken Big Data and Hadoop,NoSQL, Spark, Hadoop Admin, Hadoop projects. I have been happy with every project. They have really brought me into the forefront of Data Science and Big data. I would recommend this to everyone. It is more than worth the price. After working with them I feel so much more employable for current projects.
Ray han
Tech Leader | Stanford / Yale University
I come from Northwestern University, which is ranked 9th in the US. Although the high-quality academics at school taught me all the basics I needed, obtaining practical experience was a challenge. This is when I was introduced to ProjectPro, and the fact that I am on my second subscription year only goes to prove that the ROI is satisfactory. I managed to switch to analytics companies, only because of the relevant practical experience this product served me with. I now work at a leading healthcare startup as a Senior Analytics Consultant. I am a customer who is not only satisfied with ProjectPro but also mighty impressed by how Dezyre bends over backward to ensure customer satisfaction. I have had a couple of interactions with Binny and each time I was left happy and content. I also had a conversation with their investors, and I was really glad to articulate my appreciation of the product. They not only have enterprise-grade projects, but also set up 1:1 sessions with seasoned experts in case we get stuck, or are having trouble understanding a certain concept. As the cherry on the icing, there are experts to guide you with resume writing and interview preparation as well, to culminate the whole process of making you job-ready. Kudos to ProjectPro!
Abhinav Agarwal
Graduate Student at Northwestern University
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of them too, and that's when I came across ProjectPro while watching one of the SQL videos on the E-Learning Bridge YouTube channel. One of the standout features was that it featured real projects on topics I just read about, across different job descriptions at the time. The main issue was the right path to guide us in using these tools and adding to the resume, and that's exactly what ProjectPro got me through. The fact that I can have a reliable route and videos explaining each tool in detail really motivated me to continue with the platform. Another thing we all struggle with is how to really connect with someone if we're stuck somewhere because there are so many solutions. But this has also been solved by experts we can chat with and believe me when I say this they will do whatever it takes to solve your problem even if it takes longer than expected. In my sophomore year of college and getting hands-on exposure to technologies like PySpark, NLP, Kafka, etc, and being able to really apply the theory and work on a project from start to finish really boosted my confidence in general!
Savvy Sahai
Data Science Intern, Capgemini
Data Engineering Manager, Microsoft Corporation
Head of Data Science, Slated
Dev Advocate, Pinecone and Freelance ML
Senior Data Engineer, National Bank of Belgium
University of Economics and Technology, Instructor
Global Data Community Lead | Lead Data Scientist, Thoughtworks
Chief Science Officer at DataPrime, Inc.
Data Science, Yelp
Senior Data Scientist, Mawdoo3 Ltd
Data Engineering Lead - Uber
Chief Scientific Officer, Machine Medicine Technologies
Data Engineer - Capacity Supply Chain and Provisioning, Microsoft India CoE
Big Data Engineer, Beyond Limits
Data Scientist, Boeing
Data Engineer, Microsoft
Senior Data Engineer, Slintel-6sense company
Director of Data Science & AnalyticsDirector, ZipRecruiter
Principal Data Scientist - Cyber Security Risk Management, Verizon
Data Scientist, Credit Suisse
Data and Blockchain Professional
Head of Data science, OutFund
Senior Data Engineer, Hogan Assessment Systems
Principal Software Engineer, Afiniti
Big Data & Analytics architect, Amazon
Machine Learning Manager, Adobe
Director of Business Intelligence , CouponFollow
NLP Engineer, Speechkit
Senior Data Engineer, Publicis Sapient
Data Scientist, Inmobi
Senior Data Platform Engineer, GoodRx
Data Scientist, SwissRe
Senior Applied Scientist, Amazon
Data Science Consultant, Fractal Analytics
The process of evaluating, indexing, understanding, and comprehending computer-generated documents known as logs is known as log analytics. Many programmable technologies produce logs, including networking devices, operating systems, apps, and more. A log is a collection of messages in chronological order describing what is happening in a system. Log files can be broadcast to a log collector over an active network or saved in files for later analysis. Regardless, log analysis is the subtle technique of evaluating, indexing, and interpreting these messages to get deeper insights into any system's underlying functioning. Web server log analysis can offer important insights into everything from security to customer service to SEO. The information collected in web server application logs can help you with the following:
Network troubleshooting efforts
Development and quality assurance
Identifying and understanding security issues
Customer service
Maintaining compliance with corporate and government policies
The common log-file format is as follows:
remotehost rfc931 authuser [date] "request" status bytes
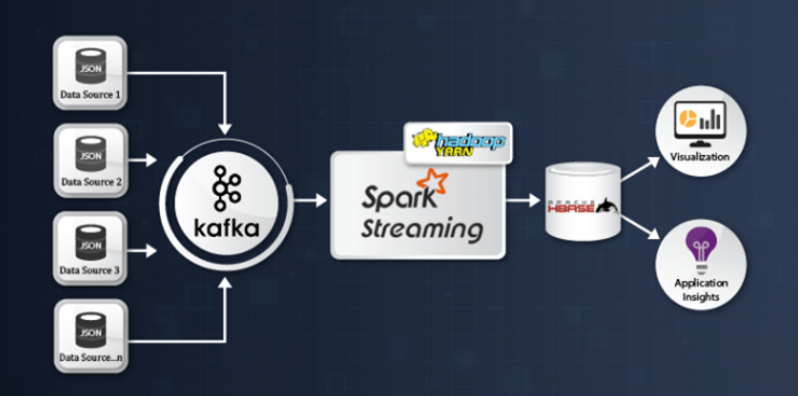
Real-time log analytics allows for the processing, parsing, and analyzing of the large volume of log data generated by an organization's internal systems and applications. Organizations like NASA can easily acquire, analyze, and store log data in real-time by using tools like Kafka, Spark, and Cassandra. This enables them to monitor system performance, identify anomalies, detect patterns, and act promptly. This also enables organizations like NASA to optimize their operations, enhance mission efficiency, and ensure the reliability and safety of its space exploration initiatives.
Imagine you are attending a music festival with thousands of people, and a team of experts is monitoring the festival grounds in real-time, analyzing the crowd's behavior and feedback. This is how real-time log analytics works!
Real-Time Log Analytics refers to analyzing and monitoring log data in real-time to gain valuable insights and detect critical events as they happen. It involves collecting, parsing, and analyzing log files generated and stored by various systems and applications in real-time.
This Python log analyzer project uses Kafka Streaming with Spark and Cassandra to analyze real-time NASA log data using various tools and services and visualize data using web apps like Dash and Plotly Python library.
In this Kafka Log Analyzer Project, we will use the NASA Kennedy Space Center WWW (Florida) Log data collection available on Kaggle.
This section mentions the various tools and technologies this Kafka Log Processing project uses.
Language: Python
Tools and Technologies: Apache Kafka, AWS EC2, Apache NiFi, Spark Streaming, Cassandra, Docker
Here are the key learning takeaways from this Real-time Log Analytics Using Kafka and Spark project-
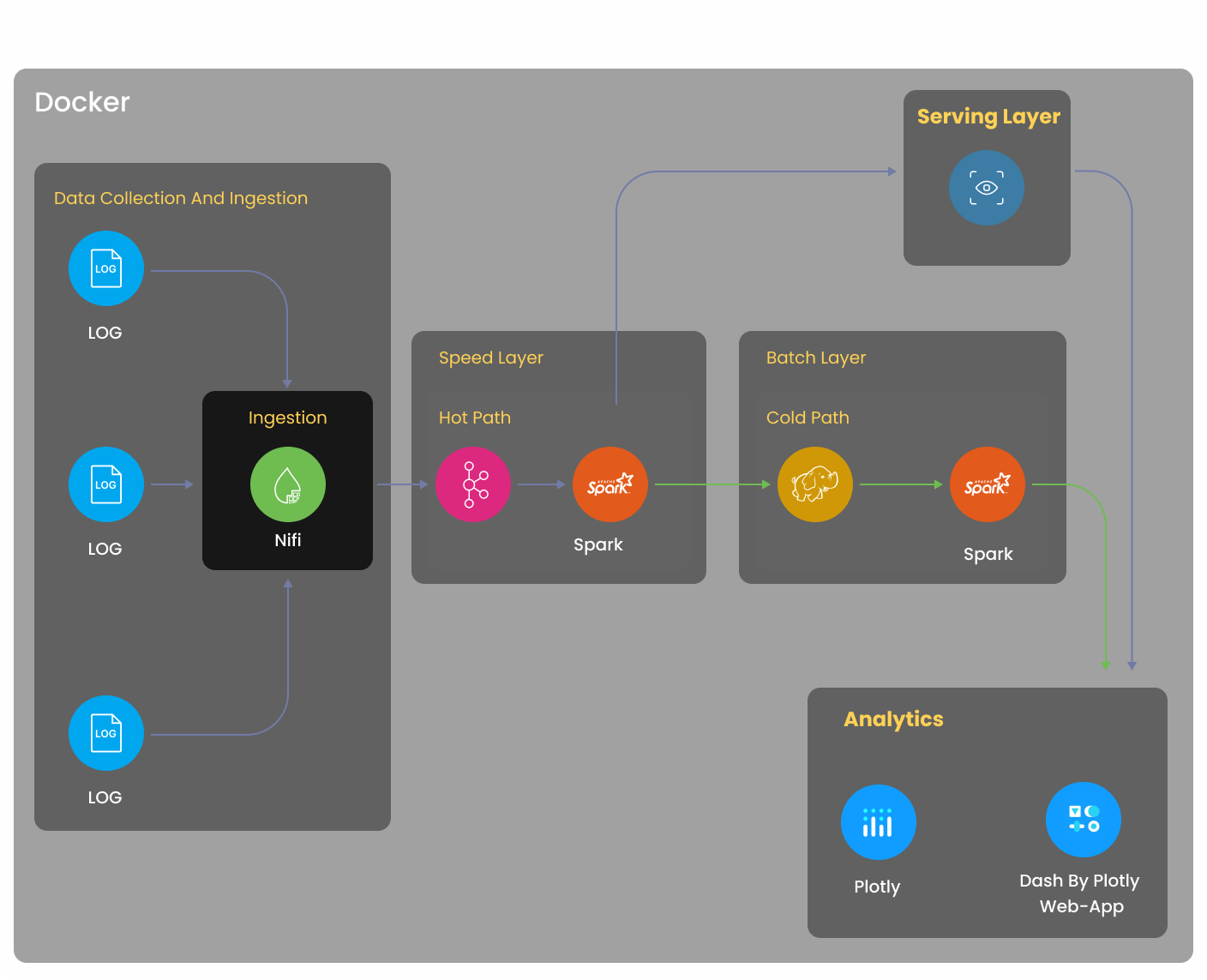
Working on this project will help you understand the Lambda Architecture while also introducing you to Docker, Apache Kafka, Apache NiFi, Spark Streaming, Cassandra, and HDFS.
You will learn how to use NiFi for data ingestion, Kafka for data consumption, and how to integrate Kafka and Spark.
You will learn how to integrate Spark with Cassandra and HDFS and how to visualize data and create dashboards using Dash and Plotly.
The project agenda involves Real-time log analysis with the visualization web app. We will launch an EC2 instance on AWS and install Docker with tools like Apache Spark, Apache NiFi, Apache Kafka, Jupyter Lab, Plotly, and Dash. Then, we will preprocess sample data, parse it into individual columns, clean it, and format the timestamp. It will be followed by the Extraction of the NASA access log dataset using Apache NiFi and Apache Kafka, followed by Transformation and Load using Cassandra and HDFS, and finally, Visualizing it using Python Plotly and Dash with the usage of graph and table app call-back.
The various steps involved in this Real-time Kafka Spark log analysis project are discussed in detail below-
The NASA log file consists of various fields, such as
remote hostname- Remote hostname (or IP number if DNS hostname is unavailable or DNSLookup is Off.
Timestamp- Date and time of the request.
request type and path- The request line exactly as it came from the client.
request status- The HTTP status code returned to the client.
size of the content - The content-length of the document transferred

This project dataflow architecture involves various steps you will follow while working on the project solution approach. The first step of this big data project is to create an EC2 instance, then install Docker, and you will put all the log file data inside the Docker container. Then, you will use NiFi to ingest the log file data into the Kafka topic as real-time streaming data in a Lambda environment, allowing you to process real-time data and batch data in the same pipeline. Now, there are three layers within this Lambda architecture- Speed, Batch, and Serving Layer. The Speed Layer continuously ingests real-time data from the Kafka Topic using Spark Structured Streaming API to a Cassandra database in the Serving Layer. Also, you will read the same data into a ‘cold storage location’ like HDFS for future analysis. You will then visualize the latest, or ‘real-time’ data, from the Cassandra database in Dash and Plotly web apps in a live dashboard.
The first step in this Spark log analysis project is to create a t2.xlarge EC2 instance with the required storage and security ports, and connect to the instance using a private SSH key. You will also copy files from the local system to the newly-created EC2 instance using the secure copy command. You will then install Docker in the EC2 machine using the command- sudo yum install docker and install docker-compose using the command- sudo curl -L "https://github.com/docker/compose/releases/download/1.29.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose. You can start and stop Docker using the commands- sudo systemctl start docker and sudo systemctl stop docker respectively. Then, you will create a new notebook in Jupyter Lab and also, add the processor in NiFi for future configuration. You will also create a new database for collection in Mongo Express.
You will first parse the log data in the common log format and split the single-line records from log data into multiple fields within a dataframe. You will import Spark Session, create a Spark Session object, and use regular expressions to query and transform the single-line records from the actual log file into multiple fields in a new dataframe.
Once you have parsed the data, it’s time to clean any null values in the dataframe. You will check the index data and replace the null values stored in all the dataframe columns with integer values (0 or zero). You will also fix any errors in the timestamp column data by converting the existing UTC-timezone data into local timezone data.
The next step is to download the NASA dataset from Kaggle and upload the CSV file to the Jupyter Lab. Next, you will open the Docker container in NiFi and copy the data there using the command- mkdir -p nasa logs && cp /opt/workspace/nifi/Input Data/data.csv nasa_logs/data.csv. You will use NiFi to ingest the data from the NiFi container and publish it to the Kafka topic.
The data ingestion phase of this project involves several steps, such as creating a Kafka topic, setting the NiFi dataflow, ingesting data from NiFi to the Kafka topic, etc.
To create the Kafka topic, you must enter the Kafka shell via CLI and create a Kafka topic using the command- kafka-topics.sh --create--topic nasa logs demo-partitions 1--replication-factor 1 --if-not-exists --zookeeper zookeeper: 2183. You can use various commands to describe a topic, delete a topic, and read data from a topic.
Go to NiFi and add the required components, such as process group, split text, processor, etc. Next, you must connect all these components by adding the configuration details. Once you connect these components, you can continue splitting and configuring the flow files in NiFi.
The final step in this phase is configuring the flow files/process group so that these files will continue pushing data to the Kafka topic. Once you start the process group, you will see that the data ingestion process begins automatically. You will then run the required command in the Kafka_Docker container to consume/read the same data from the Kafka topic.
The next step in this project solution involves loading the data from the Kafka topic into Cassandra and HDFS locations. First, you will create a keyspace (‘LogAnalysis’) and table in Cassandra using CQL commands. Then, you will also create a folder in HDFS. Next, you will create a schema with multiple fields and read the data from the Kafka topic using Spark structured streaming API by providing Kafka topic and server details.
You will then write the data to Cassandra and HDFS using Spark Streaming API. You will perform this step using the ‘foreachBatch’ method in Spark Streaming. For each batch of data you get from Kafka, pass this method that accesses the Spark Streaming dataframe from the configured Kafka and writes it into Cassandra and HDFS folder.
The final step of this project involves visualizing the live data and the batch data in three different dashboards- real-time, hourly, and daily, using the Plotly Python library and Dash. You will create a Spark Session and write the necessary functions to retrieve data from Cassandra and HDFS. You will also create a multi-page Dash application, specifying the header and table styles, page layout, etc. You will create three pages for the three dashboards, including various charts, such as scatter charts, bar graphs, etc. You will write a ‘main()’ function to execute the Dash application, allowing you to view the live, hourly, and daily dashboards.
Real-time Log Analytics enables businesses to improve operational efficiency, enhance customer experiences, and optimize decision-making by leveraging valuable real-time insights and performance metrics from their machine data and log events. Let us look at a few real-world examples of how various industries are leveraging real-time log analytics to get operational insights and metrics to accelerate their success-
Retail- Imagine walking into a store and receiving tailored promotions based on past purchases- but how does that happen? Retail stores leverage real-time analytics to monitor and analyze customer behavior. Retailers can gain real-time insights into customer preferences, buying patterns, and inventory levels by integrating point-of-sale systems, inventory management logs, etc. This allows them to optimize store layouts, ensure stock availability, and deliver personalized offers to customers.
Food and Beverages- Real-time log analytics plays a highly significant role in the food and beverages industry- for instance, restaurants can integrate point-of-sale systems, reservation logs, and customer feedback to analyze real-time data on table occupancy, popular dishes, and customer satisfaction. This enables them to optimize seating arrangements, adjust staffing levels, and address customer complaints promptly, ensuring a wonderful dining experience for all customers. So, if you visit a restaurant and experience prompt service with a personalized dining experience, you know what goes behind it all!
Consumer Goods- The consumer goods industry benefits significantly from real-time log analytics as manufacturers can analyze real-time supply chain and inventory management logs, monitor production levels, track shipments, and identify potential bottlenecks or delays. This allows them to optimize production schedules, ensure timely deliveries, and avoid stockouts or overstock scenarios. Imagine your favorite snack always being stocked on the store shelves, thanks to real-time log analysis that keeps the supply chain running smoothly!
Stream processing refers to continuous and real-time data processing as it is generated. On the other hand, real-time processing refers to the ability to process and analyze data and respond to it in real-time with minimal latency.
Apache Kafka is a popular framework/tool that can be used for real-time stream processing, which offers several features to users like distributed messaging support and event streaming services.
An example of real-time data streaming is a ride-hailing service like Uber. As passengers request rides and drivers accept those requests, a continuous data stream is generated and processed in real time, including information such as passenger location, driver availability, and real-time traffic updates.
An example of a streaming architecture is the Lambda Architecture, which combines batch and stream processing to handle and analyze large data volumes in real time.
Recommended
Projects
Learning Artificial Intelligence with Python as a Beginner
Explore the world of AI with Python through our blog, from basics to hands-on projects, making learning an exciting journey.
A comprehensive guide on LLama2 architecture, applications, fine-tuning, tokenization, and implementation in Python.
Data Products-Your Blueprint to Maximizing ROI
Explore ProjectPro's Blueprint on Data Products for Maximizing ROI to Transform your Business Strategy.
Get a free demo
ProjectPro
![]()
![]()
![]()