










































Data Scientist, Boeing

Data Scientist, Inmobi

Data Science Consultant, Fractal Analytics

Senior Data Scientist, Mawdoo3 Ltd
In this big data project, you will use Hadoop, Flume, Spark and Hive to process the Web Server logs dataset to glean more insights on the log data.
Get started today
Request for free demo with us.
Schedule 60-minute live interactive 1-to-1 video sessions with experts.
Unlimited number of sessions with no extra charges. Yes, unlimited!
Give us 72 hours prior notice with a problem statement so we can match you to the right expert.
Schedule recurring sessions, once a week or bi-weekly, or monthly.
If you find a favorite expert, schedule all future sessions with them.
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
Source: ![]()
250+ end-to-end project solutions
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
15 new projects added every month
New projects every month to help you stay updated in the latest tools and tactics.
500,000 lines of code
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
600+ hours of videos
Each project solves a real business problem from start to finish. These projects cover the domains of Data Science, Machine Learning, Data Engineering, Big Data and Cloud.
Cloud Lab Workspace
New projects every month to help you stay updated in the latest tools and tactics.
Unlimited 1:1 sessions
Each project comes with verified and tested solutions including code, queries, configuration files, and scripts. Download and reuse them.
Technical Support
Chat with our technical experts to solve any issues you face while building your projects.
7 Days risk-free trial
We offer an unconditional 7-day money-back guarantee. Use the product for 7 days and if you don't like it we will make a 100% full refund. No terms or conditions.
Payment Options
0% interest monthly payment schemes available for all countries.
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic was "Credit Risk Modelling". To understand other domains, it is important to wear a thinking cap and that's where ProjectPro helped me. I also got a chance to talk to experts who have worked on these domains - they helped me by walking through the project. Kudos to the ProjectPro team!
Gautam Vermani
Data Consultant at Confidential
ProjectPro is a unique platform and helps many people in the industry to solve real-life problems with a step-by-step walkthrough of projects. A platform with some fantastic resources to gain hands-on experience and prepare for job interviews. I would highly recommend this platform to anyone looking to upskill and stay updated with the latest projects and solutions. Overall this platform is awesome and worth the money spent as we get a lot of value out of it and helps soar our career to greater heights.
Anand Kumpatla
Sr Data Scientist @ Doubleslash Software Solutions Pvt Ltd
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good theoretical knowledge, the practical approach, real word application, and deployment knowledge were missing. ProjectPro helped me bridge that gap. ProjectPro has real-time projects that helped me improve my skills. What I liked most is that I get exposure to so many projects, given the work nature I wouldn't have gotten exposure to such a variety of projects and their approaches. It is helping me apply knowledge to other projects too. I highly recommend ProjectPro to everyone who wants to excel in their DataScience career.
Ameeruddin Mohammed
ETL (Abintio) developer at IBM
I think that they are fantastic. I attended Yale and Stanford and have worked at Honeywell,Oracle, and Arthur Andersen(Accenture) in the US. I have taken Big Data and Hadoop,NoSQL, Spark, Hadoop Admin, Hadoop projects. I have been happy with every project. They have really brought me into the forefront of Data Science and Big data. I would recommend this to everyone. It is more than worth the price. After working with them I feel so much more employable for current projects.
Ray han
Tech Leader | Stanford / Yale University
Data Scientist, Boeing
Data Scientist, Inmobi
Data Science Consultant, Fractal Analytics
Senior Data Scientist, Mawdoo3 Ltd
Head of Data Science, Slated
Senior Data Platform Engineer, GoodRx
Big Data Engineer, Beyond Limits
Big Data & Analytics architect, Amazon
Principal Data Scientist - Cyber Security Risk Management, Verizon
Director of Data Science & AnalyticsDirector, ZipRecruiter
Head of Data science, OutFund
Director of Business Intelligence , CouponFollow
Data Scientist, Credit Suisse
Dev Advocate, Pinecone and Freelance ML
Global Data Community Lead | Lead Data Scientist, Thoughtworks
Senior Data Engineer, Publicis Sapient
NLP Engineer, Speechkit
Data Engineer, Microsoft
Principal Software Engineer, Afiniti
Chief Science Officer at DataPrime, Inc.
Data Engineer - Capacity Supply Chain and Provisioning, Microsoft India CoE
Senior Data Engineer, National Bank of Belgium
Data Engineering Manager, Microsoft Corporation
Senior Applied Scientist, Amazon
Data Science, Yelp
University of Economics and Technology, Instructor
Senior Data Engineer, Hogan Assessment Systems
Senior Data Engineer, Slintel-6sense company
Chief Scientific Officer, Machine Medicine Technologies
Data and Blockchain Professional
Machine Learning Manager, Adobe
Data Engineering Lead - Uber
Data Scientist, SwissRe
Agenda
Data processing is a crucial step in understanding any data. As a part of this video series, we understand various features and techniques available in Hadoop to store data in distributed manner on HDFS. We then use Hive to create projection of data stored in HDFS, Flume to ingest data from external systems to HDFS and Spark and Scala to process and transform the NASA log data to gain insights.
Aim:
In this project, you will use Hadoop, Flume, Spark and Hive to process the Web Server logs dataset to get more insights on the log data. As part of this, you will create Azure Virtual Machine and install Hadoop, Flume, Spark, Scala and Hive to perform Flume agent execution, Build Scala code, submit Spark jobs and Hive Queries using the dataset.
Data Format:
The logs are an ASCII file with one line per request, with the following columns:
host making the request. A hostname when possible. Otherwise the Internet address.
Timestamp in the format "DAY MON DD HH:MM:SS YYYY", where DAY is the day of the week, MON is the name of the month, DD is the day of the month, HH:MM:SS is the time of day using a 24-hour clock, and YYYY is the year. The timezone is -0400.
Request given in quotes.
HTTP reply code.
Bytes in the reply.
Tech Stack
➔ Language: Scala
➔ Services: Microsoft Azure, Hadoop, Hive, Flume, Spark
Scala
Scala is a multi-paradigm, general-purpose, high-level programming language. It's an object-oriented programming language that also supports functional programming. Scala applications can be converted to bytecodes and run on the Java Virtual Machine (JVM). Scala is a scalable programming language, and Javascript runtimes are also available.
Hive
Apache Hive is a fault-tolerant distributed data warehouse that allows for massive-scale analytics. Using SQL, Hive allows users to read, write, and manage petabytes of data. Hive is built on top of Apache Hadoop, an open-source platform for storing and processing large amounts of data. As a result, Hive is inextricably linked to Hadoop and is designed to process petabytes of data quickly. Hive is distinguished by its ability to query large datasets with a SQL-like interface utilizing Apache Tez or MapReduce.
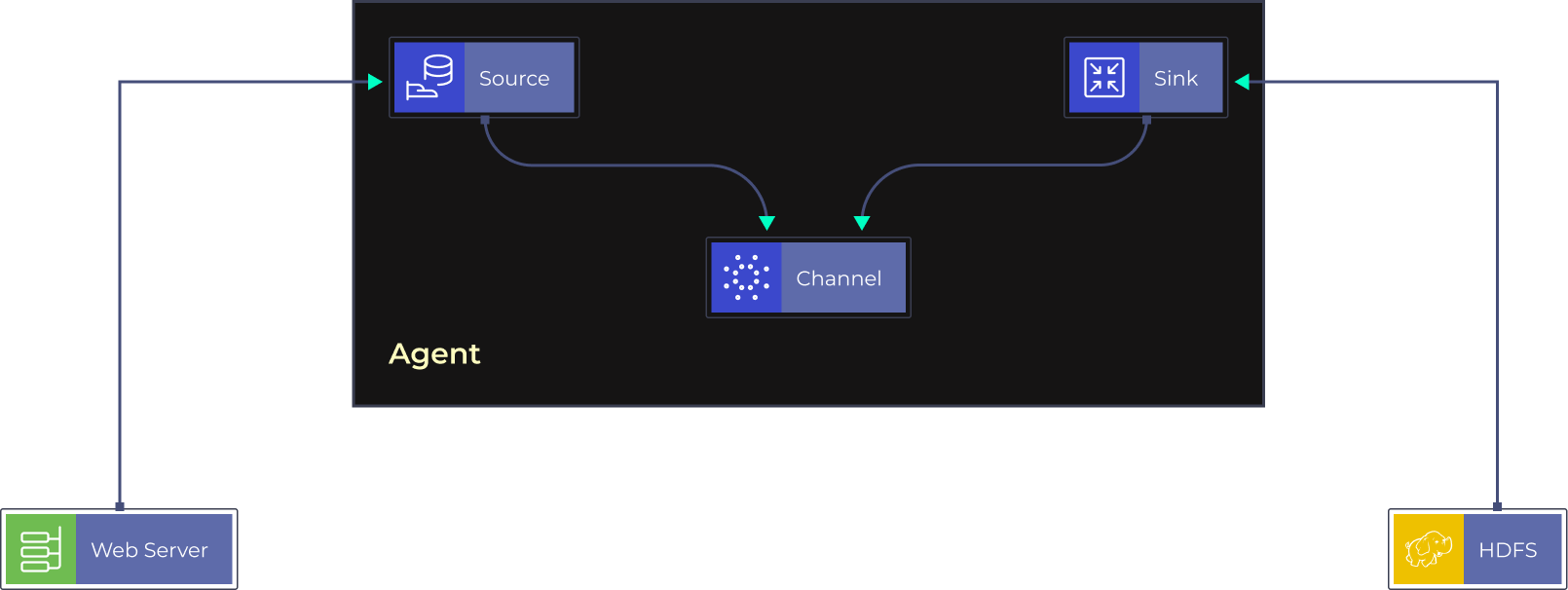
Flume
Flume is a service for rapidly gathering, aggregating, and transporting massive amounts of log data that is distributed, reliable, and available. Its architecture is simple and adaptable, based on streaming data flows. It has configurable reliability techniques as well as several failovers and recovery mechanisms, making it resilient and fault tolerant. It employs a straightforward extensible data model that enables online analytic applications.
Approach
Sign-in to the Microsoft Azure account
Create a virtual machine
Select the tab to create a new VM
Add the basic configuration details to create a VM instance.
Connect to the Virtual machine
Download and install the putty application
Add the configuration details.
Install hadoop, hive, flume, scala, spark
Execute the Scripts in code.Zip step by step.
Recommended
Projects
Learning Artificial Intelligence with Python as a Beginner
Explore the world of AI with Python through our blog, from basics to hands-on projects, making learning an exciting journey.
Generative AI Application Landscape: All That You Need to Know
Explore the Generative AI Application Landscape with industry expert Rajdeep Arora to explore insights on its evolution, challenges, and prospects | ProjectPro
Understanding LLM Hallucinations and Preventing Them
A beginner-friendly handbook for understanding LLM hallucinations and exploring various prevention methods.
Get a free demo
ProjectPro
![]()
![]()
![]()



































