Metrics for Evaluating Machine Learning Algorithms
The next step after implementing a machine learning algorithm is to find out how effective is the model based on metric and datasets. Different performance metrics are used to evaluate different Machine Learning Algorithms. For example a classifier used to distinguish between images of different objects; we can use classification performance metrics such as, Log-Loss, Average Accuracy, AUC, etc. If the machine learning model is trying to predict a stock price, then RMSE (rot mean squared error) can be used to calculate the efficiency of the model. Another example of metric for evaluation of machine learning algorithms is precision recall or NDCG, which can be used for sorting algorithms primarily used by search engines. Therefore, we see that different metrics are required to measure the efficiency of different algorithms, also depending upon the dataset at hand.

Testing Data
The next important question while evaluating the performance of a machine learning model is what dataset should be used to evaluate model performance. The machine learning model cannot be simply tested using the training set, because the output will be prejudiced, because the process of training the machine learning model has already tuned the predicted outcome to the training dataset. Therefore in order to estimate the generalization error, the model is required to test a dataset which it hasn’t seen yet; giving birth to the term testing dataset.
Therefore for the purpose of testing the model, we would require a labelled dataset. This can be achieved by splitting the training dataset into training dataset and testing dataset. This can be achieved by various techniques such as, k-fold cross validation, jackknife resampling and bootstrapping. Techniques like A/B testing are used to measure performance of machine learning models in production against response from real user interaction.
Recommended Reading:
Classification Metrics
Classification model predict the class labels for given input data. In binary and multi-class classification, we have two output classes and more than two output classes, respectively. The metrics discussed in this tutorials will be focused on binary classification, which can be extended to the case of multi-class classification problems. Let’s take example of binary classification problem, when the model is required to classify an image as a facial image or a non-facial image. Here the input data is a RGB image matrix. For sake of simplicity we can name the classes as ‘Class F’ & ‘Class NF’.

Class F Image
Several methods could be used to measure the performance of the classification model. Some of them are log-loss, AUC, confusion matrix, and precision-recall.
Accuracy is the measure of correct prediction of the classifier compared to the overall data points. Simply put, it is the ratio of the units of correct predictions and total number of predictions made by the classifiers. However accuracy doesn’t give us the best picture of the cost of misclassification or unbalanced testing data set. Therefore we look at the confusion matrix which treats the failed examples of Class F and Class NF images differently.

Before we have a deeper look at the Confusion matrix, let’s look at these two terms:
- False Positive
- False Negative
When the classifier labels a non-facial image as facial image, it is case of False Positive. Similarly, when a classifier identifies a facial image as a non-facial image, it would called an instance False Negative. The confusion matrix for any model, takes into account all these things and presents a clear picture of correct and incorrect classifications for each class of objects.
Another metrics that we can use is known as per-class accuracy, which is the average of the accuracy for each class. This happens when there is an imbalance in the dataset for each classes in the testing dataset. Since there are plenty more examples of one class compared to the other, we have a distorted view of accuracy in prediction. Hence the concept of calculating average of accuracy for each class.
Get Closer To Your Dream of Becoming a Data Scientist with 70+ Solved End-to-End ML Projects
Let’s look into the case when the output of the classifier isn’t a clear cut binary classification; rather it is a numeric probability signifying the confidence of how likely that data point belongs to a certain class. Logarithmic Loss (log-loss) is a soft measurement of the accuracy accounting for the probabilistic confidence of the classifier model. The formula to calculate logarithmic loss for a binary class classifier is mentioned below:
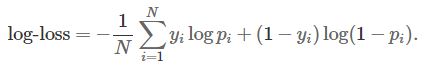
- pi is the probability of ith object belonging class 1, as calculated by classifier.
- yi is the actual label of the ith object; could be either 0 or 1.
Those who are familiar with the information theory, would know that logarithmic loss if the cross entropy between the distribution of true labels and the model predictions and is also defined as relative entropy or Kullback-Leibler divergence in some cases. Therefore in order to increase the efficiency of the classifier, we need to minimize the cross-entropy of the model.
Learn Data Science by working on interesting Data Science Projects
ROC curve (Receiver Operating Characteristics Curve) is another metrics to measure the performance of a classifier model, ROC curve depicts the locus of rate of true positives with respect to rate of false positives, this highlights the sensitivity of the classifier model. The ideal classifier will have an ROC where the graph would hit a true positive rate of 100% with zero development of x-axis (false positives). Since that is improbable in reality, we measure how many correct positive classification are being gained with increment in rate of false positives. A sample example of an ROC curve is mentioned below:

Area under the ROC curve is one of the good ways to estimate the accuracy of the model. Because an ideal ROC curve will have lot more AUC (Area Under Curve) than compared to poor classifier’s ROC.
Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization
