Hadoop MapReduce Tutorial
Hadoop MapReduce is a programming paradigm at the heart of Apache Hadoop for providing massive scalability across hundreds or thousands of Hadoop clusters on commodity hardware. The MapReduce model processes large unstructured data sets with a distributed algorithm on a Hadoop cluster.
The term MapReduce represents two separate and distinct tasks Hadoop programs perform-Map Job and Reduce Job. Map job scales takes data sets as input and processes them to produce key value pairs. Reduce job takes the output of the Map job i.e. the key value pairs and aggregates them to produce desired results. The input and output of the map and reduce jobs are stored in HDFS.

What is MapReduce?
Hadoop MapReduce (Hadoop Map/Reduce) is a software framework for distributed processing of large data sets on computing clusters. It is a sub-project of the Apache Hadoop project. Apache Hadoop is an open-source framework that allows to store and process big data in a distributed environment across clusters of computers using simple programming models. MapReduce is the core component for data processing in Hadoop framework. In layman’s term Mapreduce helps to split the input data set into a number of parts and run a program on all data parts parallel at once. The term MapReduce refers to two separate and distinct tasks. The first is the map operation, takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs). The reduce operation combines those data tuples based on the key and accordingly modifies the value of the key.

Bear, Deer, River and Car Example
The following word count example explains MapReduce method. For simplicity, let's consider a few words of a text document. We want to find the number of occurrence of each word. First the input is split to distribute the work among all the map nodes as shown in the figure. Then each word is identified and mapped to the number one. Thus the pairs also called as tuples are created. In the first mapper node three words Deer, Bear and River are passed. Thus the output of the node will be three key, value pairs with three distinct keys and value set to one. The mapping process remains the same in all the nodes. These tuples are then passed to the reduce nodes. A partitioner comes into action which carries out shuffling so that all the tuples with same key are sent to same node.

The Reducer node processes all the tuples such that all the pairs with same key are counted and the count is updated as the value of that specific key. In the example there are two pairs with the key ‘Bear’ which are then reduced to single tuple with the value equal to the count. All the output tuples are then collected and written in the output file.
How is MapReduce used?
Various platforms are designed over Hadoop for easier querying, summarization. For instance, Apache Mahout provides machine learning algorithms that are implemented over Hadoop. Apache Hive provides data summarization, query, and analysis over the data stored in HDFS.
Learn Hadoop by working on interesting Big Data and Hadoop Projects
MapReduce is primarily written in Java, therefore more often than not, it is advisable to learn Java for Hadoop MapReduce.MapReduce libraries have been written in many programming languages. Though it is mainly implemented in Java, there are non-Java interfaces such as Streaming(Scripting Languages), Pipes(C++), Pig, Hive, Cascading. In case of Streaming API, the corresponding jar is included and the mapper and reducer are written in Python/Scripting language. Hadoop which in turn uses MapReduce technique has a lot of use cases. On a general note it is used in scenario of needle in a haystack or for continuous monitoring of a huge system statistics. One such example is monitoring the traffic in a country road network and handling the traffic flow to prevent a jam. One common example is analyzing and storage of twitter data. It is also used in Log analysis which consists of various summations.
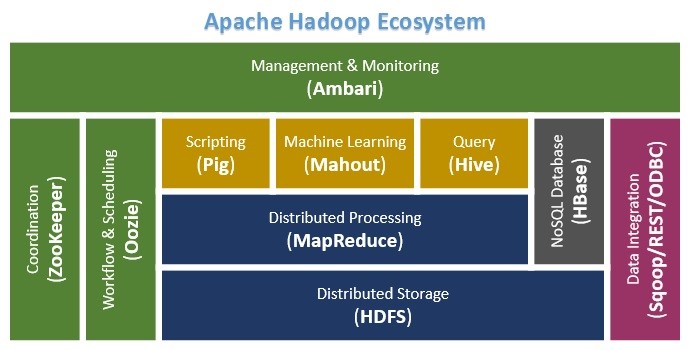

MapReduce Architecture
The figure shown below illustrates the various parameters and modules that can be configured during a MapReduce operation:
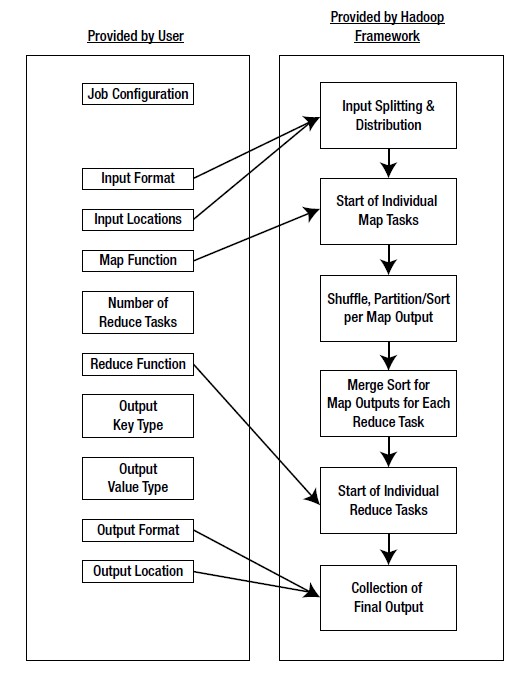
JobConf is the framework used to provide various parameters of a MapReduce job to the Hadoop for execution. The Hadoop platforms executes the programs based on configuration set using JobConf. The parameters being Map Function, Reduce Function, combiner , Partitioning function, Input and Output format. Partitioner controls the shuffling of the tuples when being sent from Mapper node to Reducer nodes. The total number of partitions done in the tuples is equal to the number of reduce nodes. In simple terms based on the function output the tuples are transmitted through different reduce nodes.
Input Format describes the format of the input data for a MapReduce job. Input location specifies the location of the datafile. Map Function/ Mapper convert the data into key value pair. For example let’s consider daily temperature data of 100 cities for the past 10 years. In this the map function is written such a way that every temperature being mapped to the corresponding city. Reduce Function reduces the set of tuples which share a key to a single tuple with a change in the value. In this example if we have to find the highest temperature recorded in the city the reducer function is written in such a way that it return the tuple with highest value i.e: highest temperature in the city in that sample data.

The number of Map and Reduce nodes can also be defined. You can set Partitioner function which partitions and transfer the tuples which by default is based on a hash function. In other words we can set the options such that a specific set of key value pairs are transferred to a specific reduce task. For example if your key value consists of the year it was recorded, then we can set the parameters such that all the keys of specific year are transferred to a same reduce task. The Hadoop framework consists of a single master and many slaves. Each master has JobTracker and each slave has TaskTracker. Master distributes the program and data to the slaves. Task tracker, as the name suggests keep track of the task directed to it and relays the information to the JobTracker. The JobTracker monitors all the status reports and re-initiates the failed tasks if any.
Combiner class are run on map task nodes. It takes the tuples emitted by Map nodes as input. It basically does reduce operation on the tuples emitted by the map node. It is like a pre- reduce task to save a lot of bandwidth. We can also pass global constants to all the nodes using ‘Counters’. They can be used to keep track of all events in map and reduce tasks. For example we can pass a counter to calculate the statistics of an event beyond a certain threshold.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization
Basic Command and Syntax for MapReduce
Java Program:
$HADOOP_HOME/bin/hadoop jar / org.myorg.WordCount /input-directory /output-directoryOther Scripting languages:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar -input myInputDirs -output myOutputDir -mapper /bin/cat -reducer /bin/wcInput parameter mentions the input files and the output parameter mentions the output directory. Mapper and Reducer mentions the algorithm for Map function and Reduce function respectively. These have to be mentioned in case Hadoop streaming API is used i.e; the mapper and reducer are written in scripting language. The commands remains the same as for Hadoop. The jobs can also be submitted using jobs command in Hadoop. All the parameters for the specific task has to be mentioned in a file called ‘job-file’ and submitted to Hadoop using the following command.
The following are the commands that are useful when a job file is submitted:
hadoop job -list Displays all the ongoing jobs
hadoop job-status Prints the map and reduce completion percentage
hadoop job -kill Kills the corresponding job.
hadoop job -set-priority Set priority for Queued jobs
