Impala Case Study: Web Traffic
Problem Statement
Data that has been generating over the network is increasing exponentially. But the existing data warehouse systems does not provide much scalability at less cost with higher performance.

Proposed Solution
Instead of using costly warehouse systems, with the help of commodity hardware and distribution process we can serve the customers at any scale. Even if the Data generated is exponential to 10, it could be scalable simply by using Hadoop. In this case we just need to add few more nodes to increase the Size of the cluster. Because, storage is cheaper than processor.
Technical Prerequisites
Impala is a distributed process runs on top of HDFS. It requires
- Running Hadoop Cluster with all the services.
- Active Hive
- MySQL or PostgreSQL which will be used as metastore for both Hive and Impala.
- Java Virtual Machine (JVM). Oracle JVM is suggested.
- For hardware requirements Impala H/W
- Multiple components need to be installed on various nodes of the cluster. (Suggested way of installing is by using Cloudera Manager, which gives automatic installation of components via graphical user interface)
Learn Hadoop by working on interesting Big Data and Hadoop Projects
Solution Design
Existing system runs on top of DB2 system. Data needs to be copied to HDFS on daily basis and tables in Impala needs to be updated(Configurable).
Code
Sqoop Command
sqoop import –connect jdbc:db2://networkio.com:50001/testdb –username dezyre –password password –table webtraffic_server –m 1 –target-dir /user/dezyre/internetio.db/webtraffic –fields-terminated-by ‘,’Impala
Now we have readily available data in hadoop file system, and we need to create table on top of it so that analysts can perform some operations and provide some sort of suggestions which could help in improving the network bandwidth and to take any performance action. Create a table using below command:-
create table webtraffic (count bigint, timestamp_server string,from_host string, to_host string) row format delimited fields terminated by ',' location ‘/user/dezyre/airport.db/webtraffic’;The above query creates a table in default database(default.db is default database if you don’t specify else it will create in the current database you are working). It has a column structure with various fields which describes the network source and target link and count.

Now let us fetch some sample records from the above created table just to see the format and data.
select * from webtraffic limit 5; 1 1257033601 theybf.com w.sharethis.com 1 1257033601 agohq.org 3 1257033601 twistysdownload.com adserving.com 1 1257033601 459.cim.meebo.com 459.cim.meebo.com 1 1257033601 boards.nbc.com change.menelgame.pl
So, now will perform some analytics and find out what is the host that is being used by most of the customers or which creates more requests to that host. Through this we can put this as a platform and we can make business by advertising the way most companies do.
select to_host,SUM(count) as tot from webtraffic where to_host is not null group by to_host order by tot desc limit 1; | to_host| tot| | facebook.com | 21055155 |
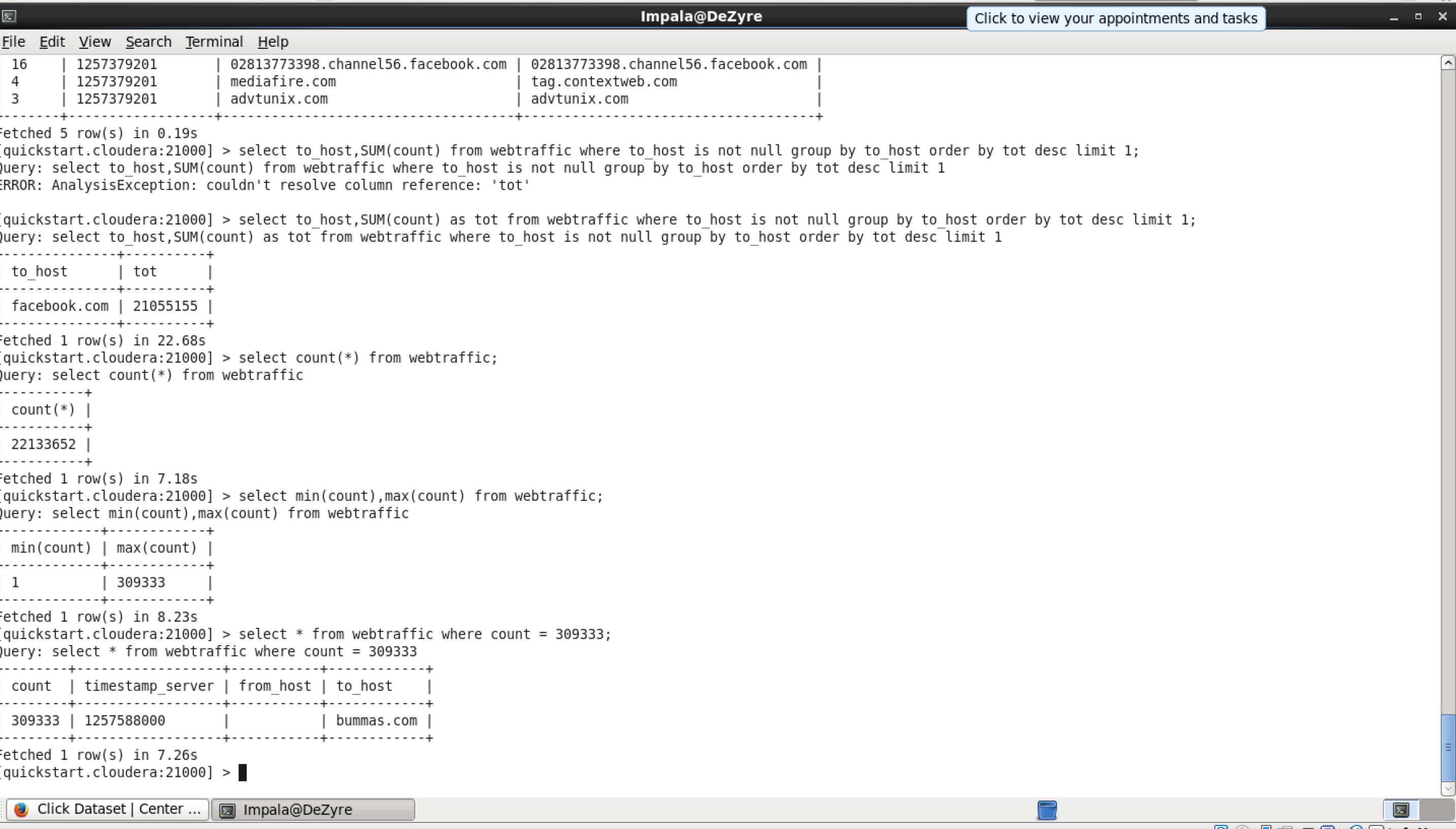
Using these interactive results business can take quick decisions and can provide faster solutions in real time. The main advantage is, if statistics says that the network crashes after x requests, we can have a check in real time for x and we can preventive measures.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization
Conclusion
Impala could be the best for analytics and for business to have quick insights on customer behavior and network traffic. These information could be plotted as a graph with nodes as routes traversed and edges as domains/hosts which will clearly explain the traffic with a pictorial representation.
