How to change the owner of files in HDFS
This recipe helps you change the owner of files in HDFS
Recipe Objective: How to change the owner of files in HDFS?
This recipe demonstrates how to change the owner of files in the HDFS.
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure Single node Hadoop is installed on your local EC2 instance. If not already installed, follow the below link to do the same.
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if HDFS is installed. If not installed, please find the links provided above for installations.
- Type “<your public IP>:7180” in the web browser and log in to Cloudera Manager, where you can check if Hadoop is installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the “Add Services” in the cluster to add the required services in your local instance.
Changing the owner of files in the HDFS:
Firstly, switch to root user from ec2-user using the “sudo -i” command. And let us create a directory in the HDFS by changing it as the HDFS user. Commands for the same are listed below.
sudo -i
su - hdfs

Let us create a directory “test-dir” in the hdfs using the mkdir command. And check if the owner of the directory is “hdfs,” as required. Run the following commands to create the directory and list the directories in hdfs to check the owner of the newly-created directory.
hadoop fs -mkdir /user/test-dir/
hadoop fs -ls /user
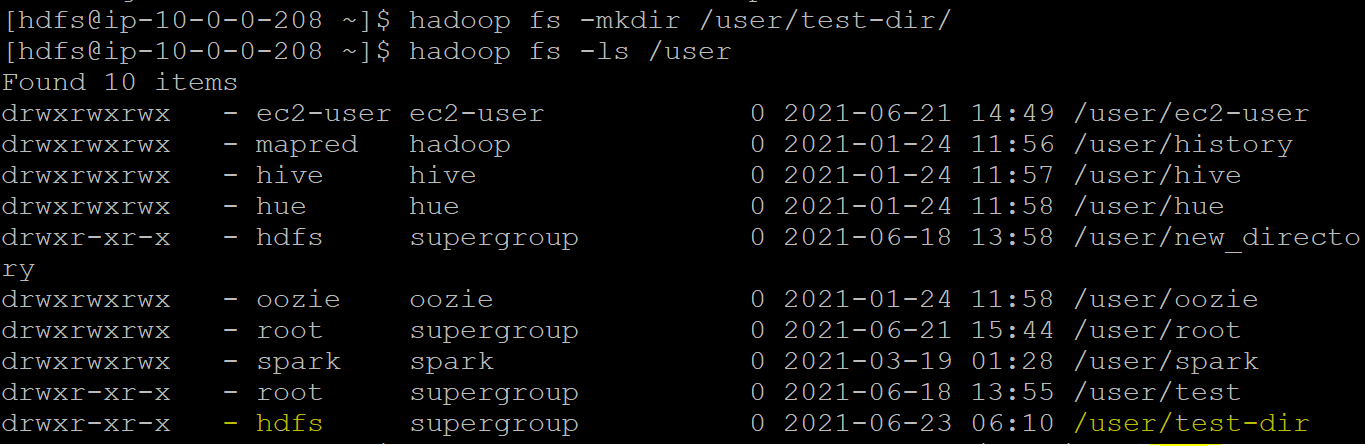
To send a file from any directory to the hdfs directory, the owner inside hdfs should be changed to the directory from which we are sending the file. For example: If you have to send a file from the root user to the “test-dir” directory inside hdfs, the owner of that directory inside hdfs should be changed to root. Run the following command to change the owner of the directory.
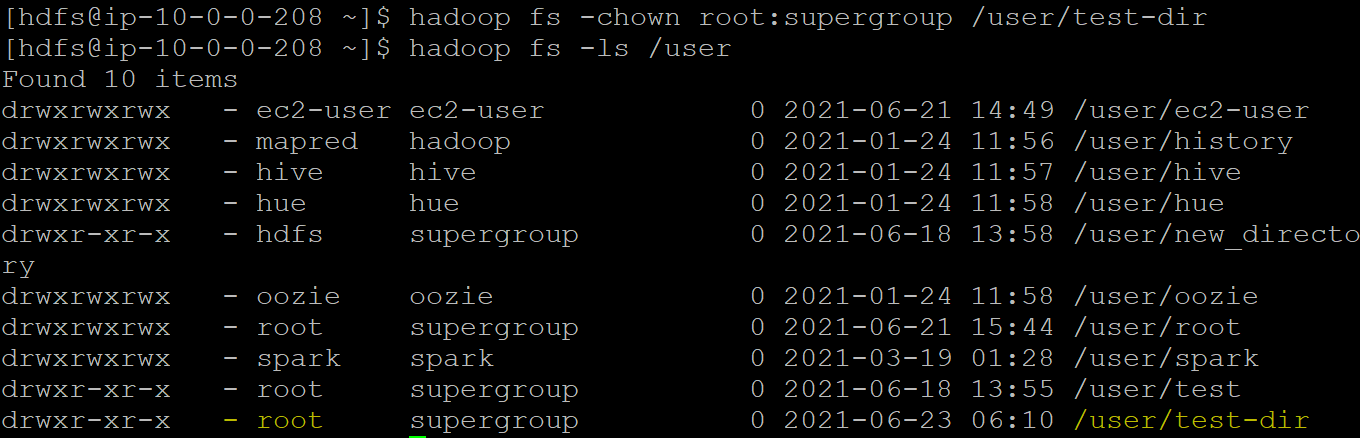
hadoop fs -chown root:supergroup /user/test-dir
Upon changing, list the files in the “user” to check if the owner of test-dir is changed from hdfs to root.
Sample output:
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ameeruddin Mohammed
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good... Read More