What is PySpark Fillna and Fill Function in Databricks?
This recipe covers the PySpark Fillna and Fill function in Databricks - Learn how to handle missing data efficiently!
Recipe Objective - What is PySpark Fillna and Fill Function in Databricks?
Apache Spark is a powerful open-source data processing framework that has gained immense popularity in the world of big data and analytics. PySpark, the Python API for Apache Spark, makes it easier for data scientists and engineers to work with large datasets and perform various data manipulation tasks. In Databricks, a cloud-based platform for big data analytics and machine learning, PySpark is widely used for data processing and analysis. One essential aspect of PySpark data manipulation is handling missing data, and this is where the fillna and fill functions come into play.
Explore PySpark Machine Learning Tutorial to take your PySpark skills to the next level!
Table of Contents
- Recipe Objective - What is PySpark Fillna and Fill Function in Databricks?
- ‘fillna’ Function in PySpark
- ‘fill’ Function in PySpark
- Key Differences Between ‘Fill’ and ‘Fillna’ Function in PySpark
- How to Implement PySpark Fillna() and Fill() Function in Databricks?
- Master PySpark Functions with ProjectPro!
‘fillna’ Function in PySpark
The fillna function in PySpark is a versatile tool for dealing with missing values in a DataFrame. It allows you to replace or fill in null values with specified values. Here's a breakdown of how to use the fillna function in Databricks:
Basic Syntax
The basic syntax for using fillna is as follows:
DataFrame.fillna(value, subset=None)
-
value: The value to replace nulls with. This can be a scalar value (e.g., a string, integer, or float) or a dictionary specifying replacement values for specific columns.
-
subset (optional): A list of column names to restrict the replacement to. If not specified, the operation is applied to all columns in the DataFrame.
Examples
-
Replace Null with Empty String
df.fillna('')
This will replace all null values in the DataFrame df with empty strings.
-
Replace Null with 0 in a Specific Column
df.fillna({'column_name': 0})
This will replace null values in the specified column with the value 0.
-
Replace Null with Different Values in Multiple Columns
df.fillna({'col1': 'A', 'col2': 999})
This will replace null values in 'col1' with 'A' and in 'col2' with 999.
‘fill’ Function in PySpark
The fill function is another method in PySpark for filling missing or null values in a DataFrame. It's similar to fillna, but there are some differences to note.
Basic Syntax
The basic syntax for using fill is as follows:
DataFrame.fill(value, *cols)
-
value: The value to replace nulls with, which should be a scalar value.
-
*cols: A variable-length argument list of column names to restrict the replacement to.
Examples
-
Replace Null with 0 in a Specific Column
df.fill(0, 'column_name')
This will replace null values in the specified column with the value 0.
-
Replace Null with 0 in Multiple Columns
df.fill(0, 'col1', 'col2')
This will replace null values in 'col1' and 'col2' with 0.
End-to-End Big Data Project to Learn PySpark SQL Functions
Key Differences Between ‘Fill’ and ‘Fillna’ Function in PySpark
The key differences between the fillna and fill functions in PySpark lie in their flexibility and the way they handle missing values. fillna offers more versatility by allowing you to specify replacement values as a dictionary, making it suitable for handling different values in multiple columns. It also provides the option to use an optional subset parameter to target specific columns for replacement. On the other hand, the fill function is simpler and more concise, expecting a single scalar value and accepting a variable-length argument list of columns for replacement. While fill is suitable for straightforward and uniform replacements, fillna excels in more complex scenarios, offering greater customization and control over how null values are handled in a DataFrame.
How to Implement PySpark Fillna() and Fill() Function in Databricks?
System Requirements
-
Python (3.0 version)
-
Apache Spark (3.1.1 version)
Explore SQL Database Projects to Add them to Your Data Engineer Resume.
Implementing the fillna() function and fill() function in Databricks in PySpark
# Importing packages
import pyspark
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import MapType, StringType
from pyspark.sql.functions import col
from pyspark.sql.types import StructType,StructField, StringType

The Sparksession, Row, MapType, StringType, col, explode, StructType, StructField, StringType are imported in the environment so as to use fillna() function and fill() function in PySpark .
Learn to Transform your data pipeline with Azure Data Factory!
# Implementing the fillna() function and fill() function in Databricks in PySpark
spark = SparkSession.builder \
.master("local[1]") \
.appName("fillna() and fill() PySpark") \
.getOrCreate()
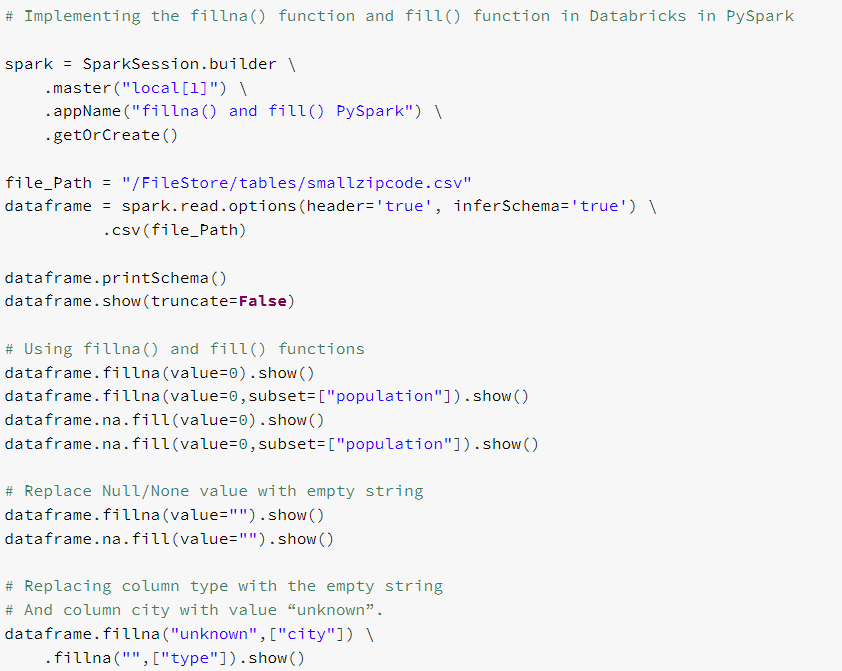
file_Path = "/FileStore/tables/smallzipcode.csv"
dataframe = spark.read.options(header='true', inferSchema='true') \
.csv(file_Path)
dataframe.printSchema()
dataframe.show(truncate=False)
# Using fillna() and fill() functions
dataframe.fillna(value=0).show()
dataframe.fillna(value=0,subset=["population"]).show()
dataframe.na.fill(value=0).show()
dataframe.na.fill(value=0,subset=["population"]).show()
# Replace Null/None value with empty string
dataframe.fillna(value="").show()
dataframe.na.fill(value="").show()
# Replacing column type with the empty string
# And column city with value “unknown”.
dataframe.fillna("unknown",["city"]) \
.fillna("",["type"]).show()

PySpark ETL Project-Build a Data Pipeline using S3 and MySQL
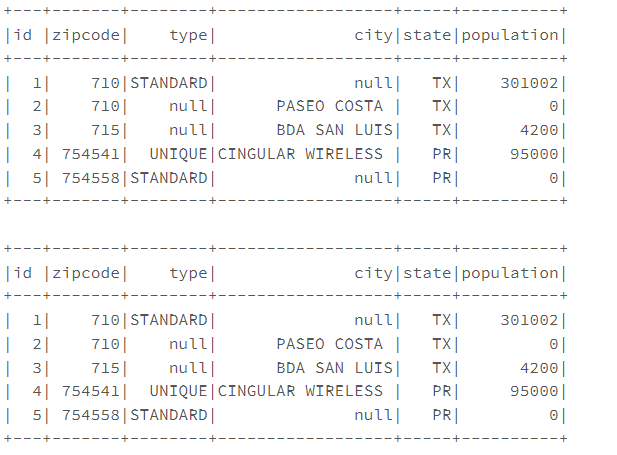

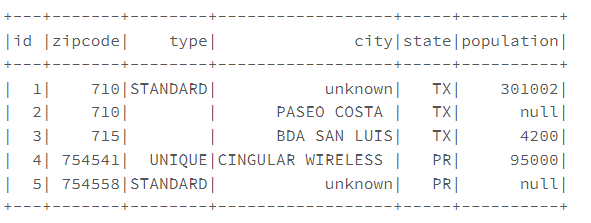
The Spark Session is defined. The "data frame" is defined using the smallzipcode.csv file. Further, the fill(value: Long) signatures are used to replace the NULL/None values with numeric values either zero(0) or any constant value for all the integer and long datatype columns of PySpark DataFrame or the Dataset so, it yields the output as it has just an integer column population with null values. While replacing Null/None values with the Empty String replaces all String type columns with empty/blank string for all the NULL values. Also, while replacing the column type with an empty string and column city with the value “unknown” yields the replacement of null values with an empty string for the type column and replaces it with a constant value “unknown” for the city column.
Master PySpark Functions with ProjectPro!
Learning how to use and implement PySpark functions like Fillna and Fill is essential for anyone looking to excel in the world of big data analytics. Practical experience gained through real-world projects is the key to becoming proficient in PySpark and other data science tools. ProjectPro offers a valuable opportunity to enhance your skills with its extensive repository of over 270+ projects, making it the ideal platform for those seeking to harness the power of PySpark and other data technologies in their professional journey. So, start your learning journey with ProjectPro and unlock the full potential of PySpark and its functions.
Download Materials
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Jingwei Li
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data.... Read More