How to perform xgboost algorithm with sklearn
This recipe helps you perform xgboost algorithm with sklearn. Xgboost is an ensemble machine learning algorithm that uses gradient boosting. Its goal is to optimize both the model performance and the execution speed.
Recipe Objective - How to perform xgboost algorithm with sklearn?
Xgboost is an ensemble machine learning algorithm that uses gradient boosting. Its goal is to optimize both the model performance and the execution speed. It can be used for both regression and classification problems. xgboost (extreme gradient boosting) is an advanced version of the gradient descent boosting technique, which is used for increasing the speed and efficiency of computation of the algorithm.
Access Avocado Machine Learning Project for Price Prediction
Table of Contents
Links for the more related projects:-
https://www.projectpro.io/projects/data-science-projects/deep-learning-projects
https://www.projectpro.io/projects/data-science-projects/neural-network-projects
Example:-
Step:1 Load necessary libraries
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import xgboost as xgb
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
boston = load_boston()
# shape of boston data
print(boston.data.shape)
print(boston.keys())
print(boston.feature_names)
(506, 13)
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
bost_df = pd.DataFrame(boston.data)
bost_df.columns = boston.feature_names
bost_df.head()
bost_df['PRICE'] = boston.target
bost_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null float64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null float64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 PRICE 506 non-null float64
dtypes: float64(14)
memory usage: 55.5 KB
bost_df.describe()

X, y = bost_df.iloc[:,:-1],bost_df.iloc[:,-1]
# convert the dataset into an optimized data structure called Dmatrix that XGBoost supports
data_dmatrix = xgb.DMatrix(data=X,label=y)
Step:2 Splitting data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
Step:3 XGBoost regressor
xg_reg = xgb.XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1,max_depth = 5, alpha = 10, n_estimators = 10)
# fitting the model
xg_reg.fit(X_train,y_train)
# predict model
pred = xg_reg.predict(X_test)
print(pred)
[10.670782 17.886362 23.993221 10.971137 20.656567 17.063112
17.413216 7.1758337 11.684821 17.894796 18.901701 14.567413
10.806006 15.261372 12.66772 14.075861 13.288725 24.107811
13.454856 11.560353 11.525483 11.551982 19.228527 23.993221
20.524649 13.448225 10.661165 15.404765 16.191902 13.140589
14.916252 21.076527 8.176096 14.827184 15.909969 21.041925
16.428032 9.314631 12.319548 23.573265 18.292862 13.454856
9.351014 22.248753 13.000366 16.475197 14.159811 15.230242
12.319548 11.772567 21.076527 16.024069 14.159811 8.882479
13.588928 10.661165 11.776985 7.1758337 19.659273 9.299877
12.806547 13.811639 11.339502 13.683961 14.075861 16.993258
16.206121 12.02784 15.3576 18.292862 13.223848 16.329927
12.808572 16.679268 11.476205 11.564092 7.552598 14.554543
19.411613 6.434427 18.412857 8.1538725 15.640896 14.134584
12.580408 15.946352 9.314631 15.61432 13.968452 20.656567
8.923061 18.412857 13.22853 16.84799 21.603022 18.147593
10.726895 20.656567 14.729023 22.39871 14.827184 10.388706 ]
Step:4 Compute the rmse by invoking the mean_sqaured_error
rmse = np.sqrt(mean_squared_error(y_test, pred))
print("RMSE: %f" % (rmse))
RMSE: 10.423243
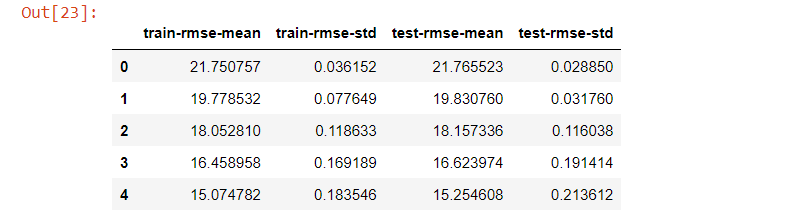
Step:5 k-fold Cross Validation using XGBoost
params = {"objective":"reg:linear",'colsample_bytree': 0.3,'learning_rate': 0.1,'max_depth': 5, 'alpha': 10}
cv_results = xgb.cv(dtrain=data_dmatrix, params=params, nfold=3,num_boost_round=50,early_stopping_rounds=10,metrics="rmse", as_pandas=True, seed=123)
cv_results.head()
# Extract and print the final boosting round metric
print((cv_results["test-rmse-mean"]).head())
49 3.99692
Name: test-rmse-mean, dtype: floa
Step:6 Visualize Boosting Trees and Feature Importance
xg_reg = xgb.train(params=params, dtrain=data_dmatrix, num_boost_round=10)
import matplotlib.pyplot as plt
xgb.plot_importance(xg_reg)
plt.rcParams['figure.figsize'] = [5, 5]
plt.show()


What Users are saying..

Ray han
I think that they are fantastic. I attended Yale and Stanford and have worked at Honeywell,Oracle, and Arthur Andersen(Accenture) in the US. I have taken Big Data and Hadoop,NoSQL, Spark, Hadoop... Read More