How to work with Import and Export commands in Hive
This recipe helps you work with Import and Export commands in Hive
Recipe Objective: How to work with Import and Export commands in Hive?
Hive supports the import and export of data between Hive and DBMS. In this recipe, we work with the Import and Export commands in Hive. The EXPORT command exports the data of a table or partition and the metadata into a specified output location. And the IMPORT command moves data from DBMS to Hive.
ETL Orchestration on AWS using Glue and Step Functions
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure Single node Hadoop and Hive are installed on your local EC2 instance. If not already installed, follow the below link to do the same.
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if HDFS and Hive are installed. If not installed, please find the links provided above for installations.
- Type “<your public IP>:7180” in the web browser and log in to Cloudera Manager, where you can check if Hadoop is installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the “Add Services” in the cluster to add the required services in your local instance.
Working with Export/Import commands in Hive:
Throughout this recipe, we used the “user_info” table present in our database. Following is the schema of the table.
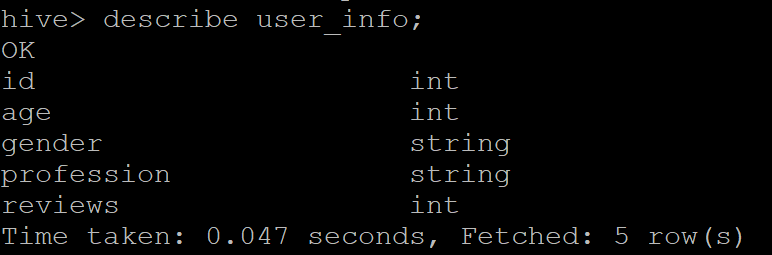
Simple Export command:
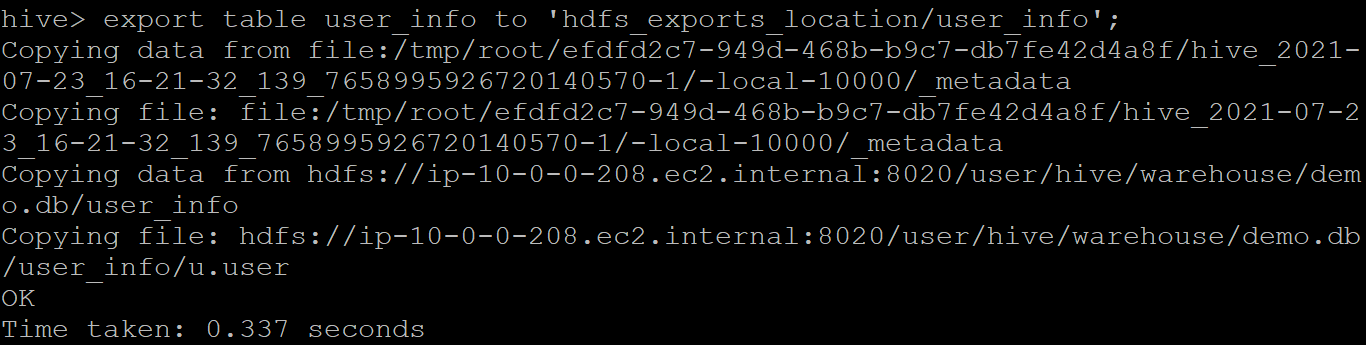
It exports the specified table to the location mentioned in the “hdfs_exports_location.” For example, if we wish to export the “user_info” table to a location named “user_info” in the hdfs, the query would be
export table user_info to 'hdfs_exports_location/user_info';
Sample output:
Simple Import command:
It imports the specified table from the location mentioned in the “hdfs_exports_location.” Please note, if the file we are importing is named the same as an existing table in the database, the hive import command throws an error. For example, if we wish to import the “user_info” table from hdfs_exports_location, it throws an error as we already have a table with the name “user_info.” The sample output is given below.

In such scenarios, we rename the table during import.
Rename table on import:
The query to rename a table on import is :
import table <new table name> from 'hdfs_exports_location/<loc>';
Sample output where we are importing the “user_info” table renamed as “user_info_2”.

Check if the table is successfully imported by listing the tables present in that database.

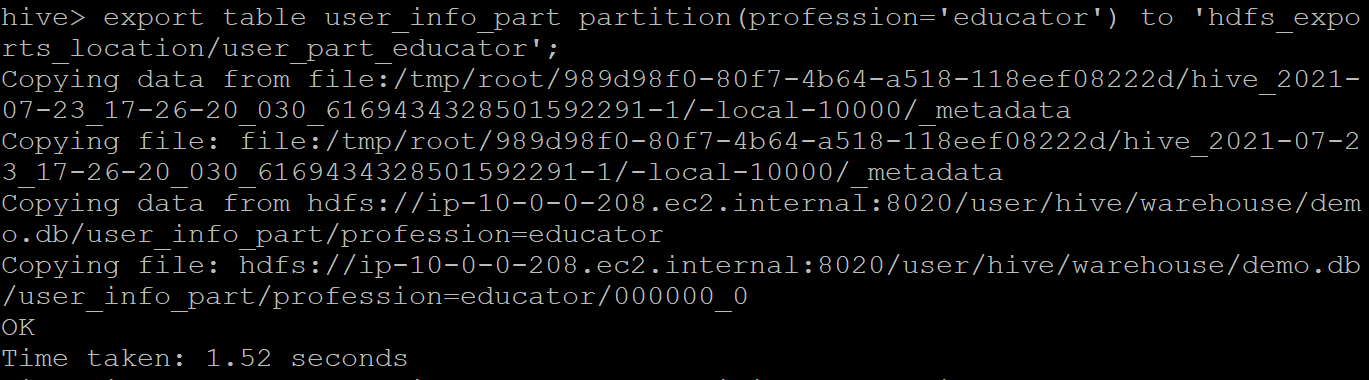
Export table partition:
Let us now see how a table partition can be exported. We have a partition table “user_info_part” that is created by partitioning the “user_info” table where the user profession is “educator.” Query to export table partition:
export table <table partition> partition(<partition condition>) to 'hdfs_exports_location/<loc>';
Sample output:
Import table partition:
The query to import table partition would be:
import table <partition table name> partition(<partition condition>) from 'hdfs_exports_location/<loc>';
Make sure the imported table partition name is not present in the database. Else the query would throw an error. Sample output for importing partition is given below.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Gautam Vermani
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic... Read More