How to apply Windows Functions using PySpark SQL
This recipe helps you apply Windows Functions using PySpark SQL
Recipe Objective: How to apply Windows Functions using PySpark SQL?
In most big data scenarios, data merging and aggregation are essential parts of big data platforms' day-to-day activities. In this scenario, we will use windows functions in which Spark needs you to optimize the queries so that you get the best performance from the Spark SQL.
Table of Contents
System requirements :
- Install Ubuntu in the virtual machine click here
- Install single-node Hadoop machine click here
- Install pyspark or spark in Ubuntu click here
- The below codes can be run in Jupyter notebook or any python console.
Step 1: Prepare a Dataset
Here we use the employees and departments related comma-separated values (CSV) datasets to read in a jupyter notebook from the local. Download the CSV file into your local download and download the data sets we are using in this scenario.
The output of the dataset:
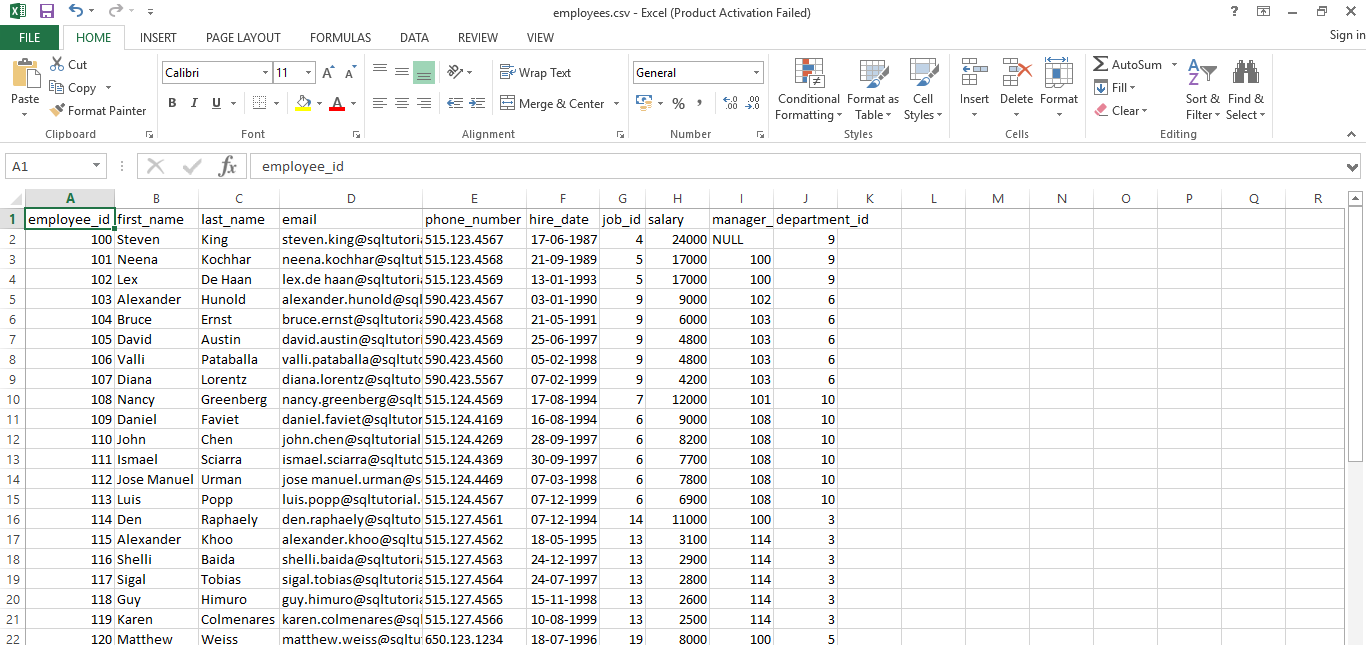
Here in this scenario, we will use window functions; these functions on vast volumes of data in a Big Data world it's going to add lots of performance constraints. Especially when we are joining big tables, there will be drastic performance degradation. So it is always a good practice to use these windows functions as pre-computed values and then use those values in the joins. We have to make sure we are using the PARTITION clause in the right manner.
The output of the departments' dataset:
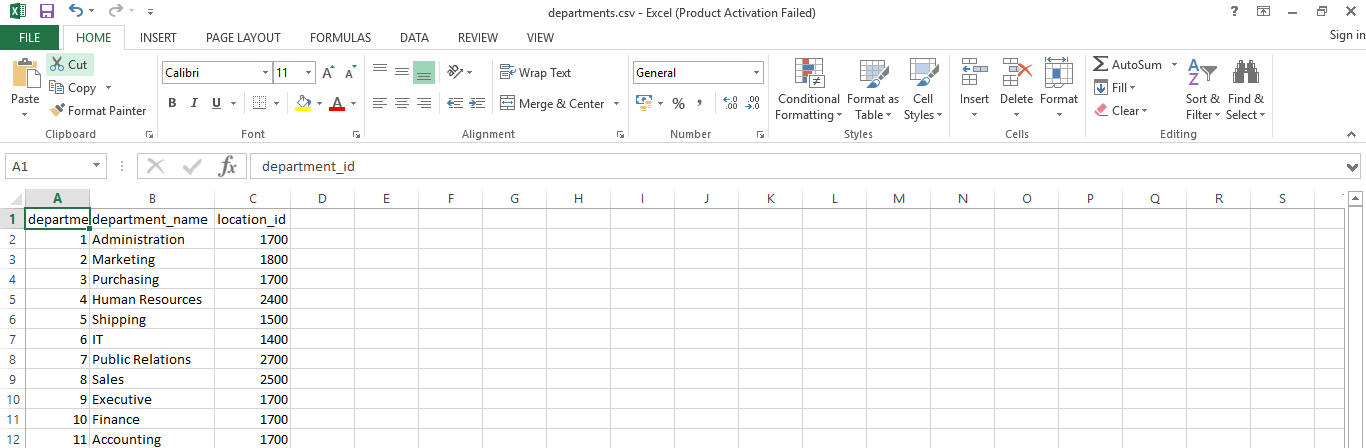
Step 2: Import the modules
In this scenario, we are going to import the pyspark and pyspark SQL modules and create a spark session as below:
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('How to Apply Windows Functions Using PySpark SQL').getOrCreate()
Step 3: Read CSV file
Here we will read the CSV file from the local where we downloaded the file, and also, we will let PySpark SQL infer the schema of the DataFrame. If we set the value of the inferSchema argument to True in the csv() function, PySpark SQL will try to infer the schema as below.
empDF = spark.read.csv('/home/bigdata/Downloads/Data_files/employees.csv',header=True,inferSchema=True)
deptDF = spark.read.csv('/home/bigdata/Downloads/Data_files/departments.csv',header=True,inferSchema=True)
To print the schema of the above-created data frames
empDF.printSchema()
deptDF.printSchema()
The output of the above code:

To print the top 5 lines of the above-created data frames as below
empDF.show(5)
deptDF.show(5)
The output of the above code:

Step 4: Create a Temporary view from DataFrames
Here we are going to create the temporary view from the above-created dataframes to perform queries on those views. To create views we use the createOrReplaceTempView() function as shown in the below code.
empDF.createOrReplaceTempView("EmpTbl")
deptDF.createOrReplaceTempView("DeptTbl")
Step 5: To Apply the windowing functions using pyspark SQL
Here, we will use the Rank Function to Get the Rank on all the rows without any window selection to use the rank function, which provides a sequential number for each row within a selected set of rows.
rank_fun=spark.sql("select first_name,email,salary,rank() over (order by first_name) as RANK from EmpTbl e join DeptTbl d ON (e.department_id = d.department_id)")
rank_fun.show()
The output of the above query:

Step 6: To Apply Partition By in a Rank Function
Here we will use Partition By in a Rank Function, the PARTITION clause, to classify the rows as multiple sets. We can visualize this as keeping a window over those sets of rows, as shown below.
mul_sets=spark.sql("select first_name,email,salary,department_name,rank() over (PARTITION BY department_name order by first_name ) as RANK from EmpTbl e join DeptTbl d ON (e.department_id = d.department_id)")
mul_sets.show()
The output Of the above query

Here we will filter on the rank column for values less than or equal to two as shown below query.
spark.sql("select first_name,email,salary,RANK from (select first_name,email,salary,department_name,rank() over (PARTITION BY department_name order by salary desc ) as RANK from EmpTbl e join DeptTbl d ON (e.department_id = d.department_id)) where RANK <= 2").show()
The output Of the above query

Conclusion
Here we learned to apply Windows Functions Using PySpark SQL.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ameeruddin Mohammed
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good... Read More