How to convert files from XML to CSV format in NiFi
This recipe helps you convert files from XML to CSV format in NiFi
Recipe Objective: How to convert files from XML format to CSV format in NiFi?
In most big data scenarios, Apache NiFi is used as open-source software for automating and managing the data flow between systems. It is a robust and reliable system to process and distribute data. It provides a web-based User Interface to create, monitor, and control data flows. Gathering data from databases is widely used to collect real-time streaming data in Big data environments to capture, process, and analyze the data. Conversion of CSV schema to XML is commonly used in big data-based large-scale environments.
Access Snowflake Real-Time Project to Implement SCD's
Table of Contents
- Recipe Objective: How to convert files from XML format to CSV format in NiFi?
- System requirements :
- Step 1: Configure the GetFile
- Step 2: Configure the UpdateAttribute
- Step 3: Configure the ConvertRecord and Create Controller Services:
- Step 4: Configure the UpdateAttribute to update the filename
- Step 5: Configure the UpdateAttribute to update file extension
- Step 6: Configure the PutFile
- Conclusion
System requirements :
- Install Ubuntu in the virtual machine Click Here
- Install Nifi in Ubuntu Click Here
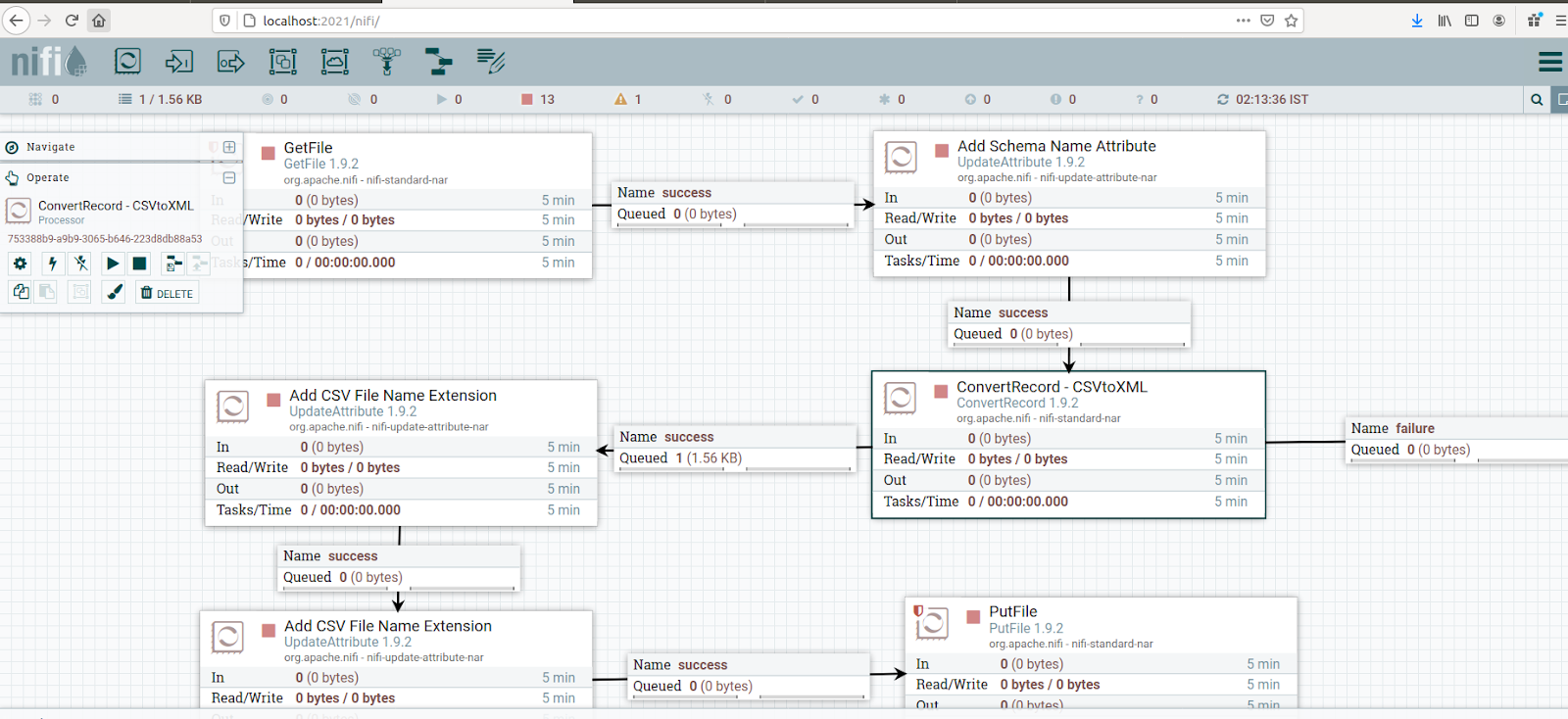
Step 1: Configure the GetFile
Creates FlowFiles from files in a directory. NiFi will ignore files it doesn't have at least read permissions for. Here we are getting the file from the local directory.

We scheduled this processor to run every 60 sec in the Run Schedule and Execution as the Primary node in the SCHEDULING tab. Here we are ingesting the drivers.xml file drivers data from a local directory; for that, we configured Input Directory and provided the file name.
Step 2: Configure the UpdateAttribute
Updates the Attributes for a FlowFile using the Attribute Expression Language and/or deletes the attributes based on a regular expression.
Here we will use the UpdateAttribute to update the schema name for the Avro schema registry as below.
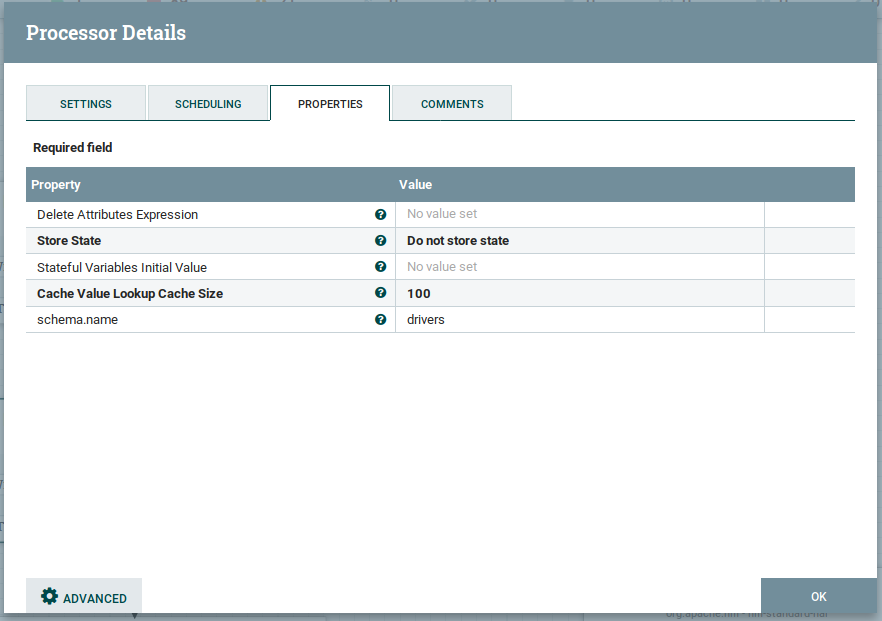
As shown above, we added a new attribute schema.name as drivers value.
Step 3: Configure the ConvertRecord and Create Controller Services:
Using an XMLReader controller service that references a schema in an AvroSchemaRegistry controller service
The AvroSchemaRegistry contains a "drivers" schema that defines information about each record (field names, field ids, field types)
Using a CSVRecordSetWriter controller service that references the same AvroSchemaRegistry schema.
In ConvertRecord processor, the properties tab in the RecordReader value column drop down will get as below, then click on create new service.
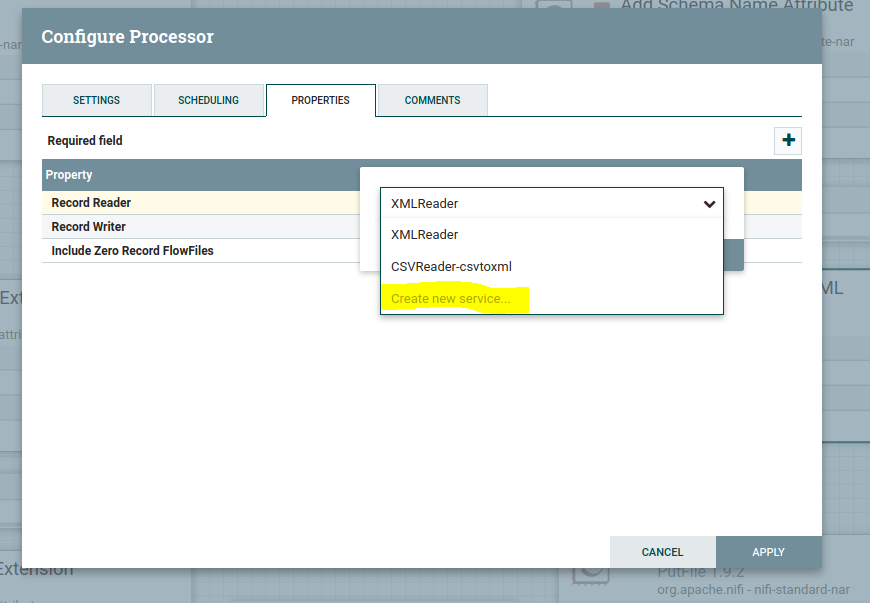
Then you will get the pop up as below select CSV reader in compatible controller service drop-down as shown below:
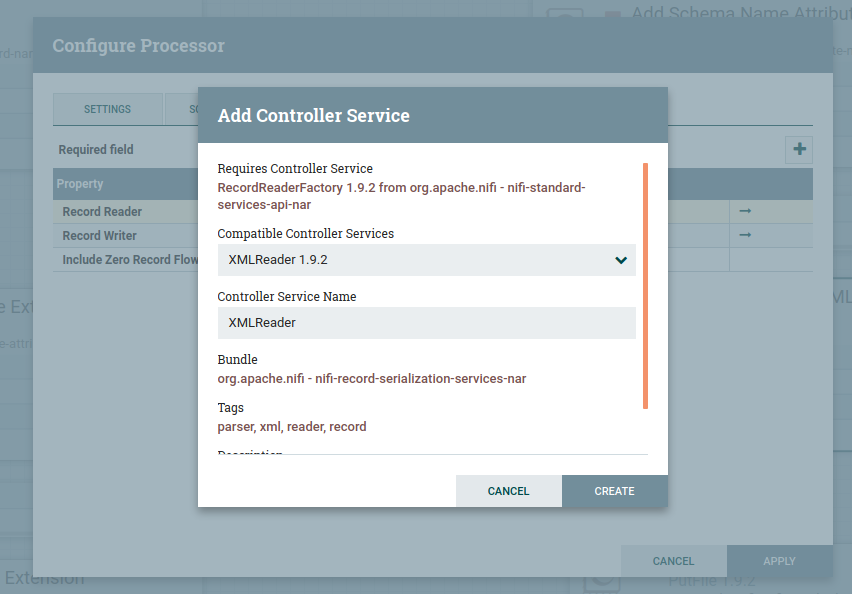
Follow the same steps to create controller service for the CSV record set writer as below

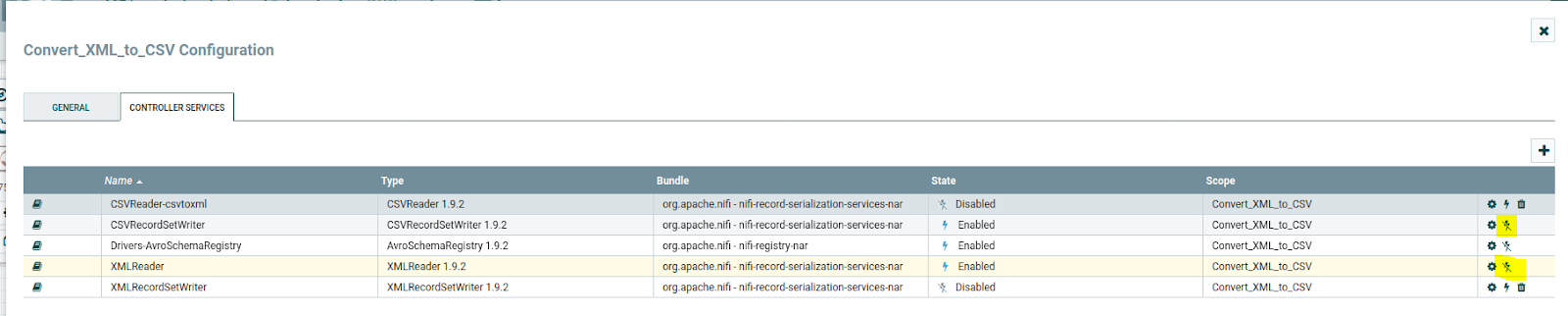
To Enable Controller Services Select the gear icon from the Operate Palette:
This opens the NiFi Flow Configuration window. Select the Controller Services tab:
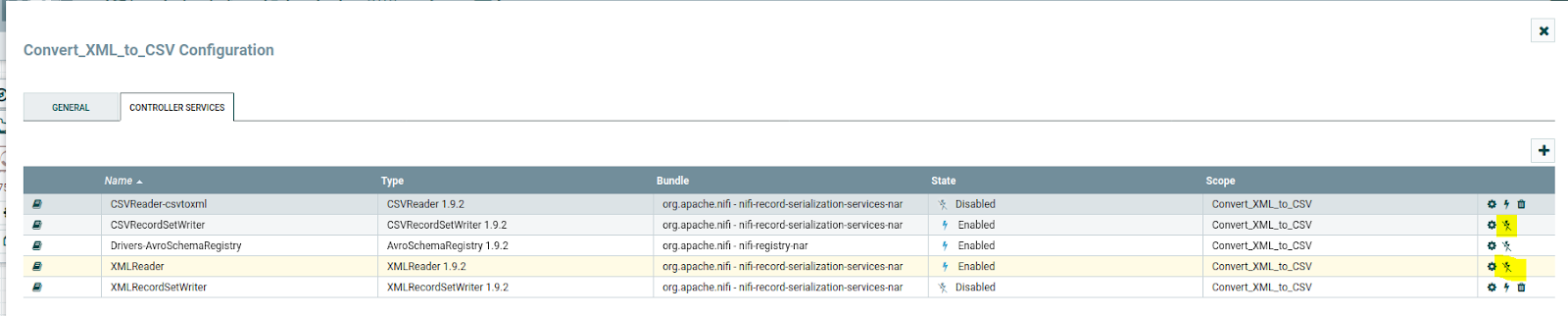
Click on the "+" symbol to add the Avro schema registry; it will add the Avro schema registry as the above image. Then click on the gear symbol and config as below:
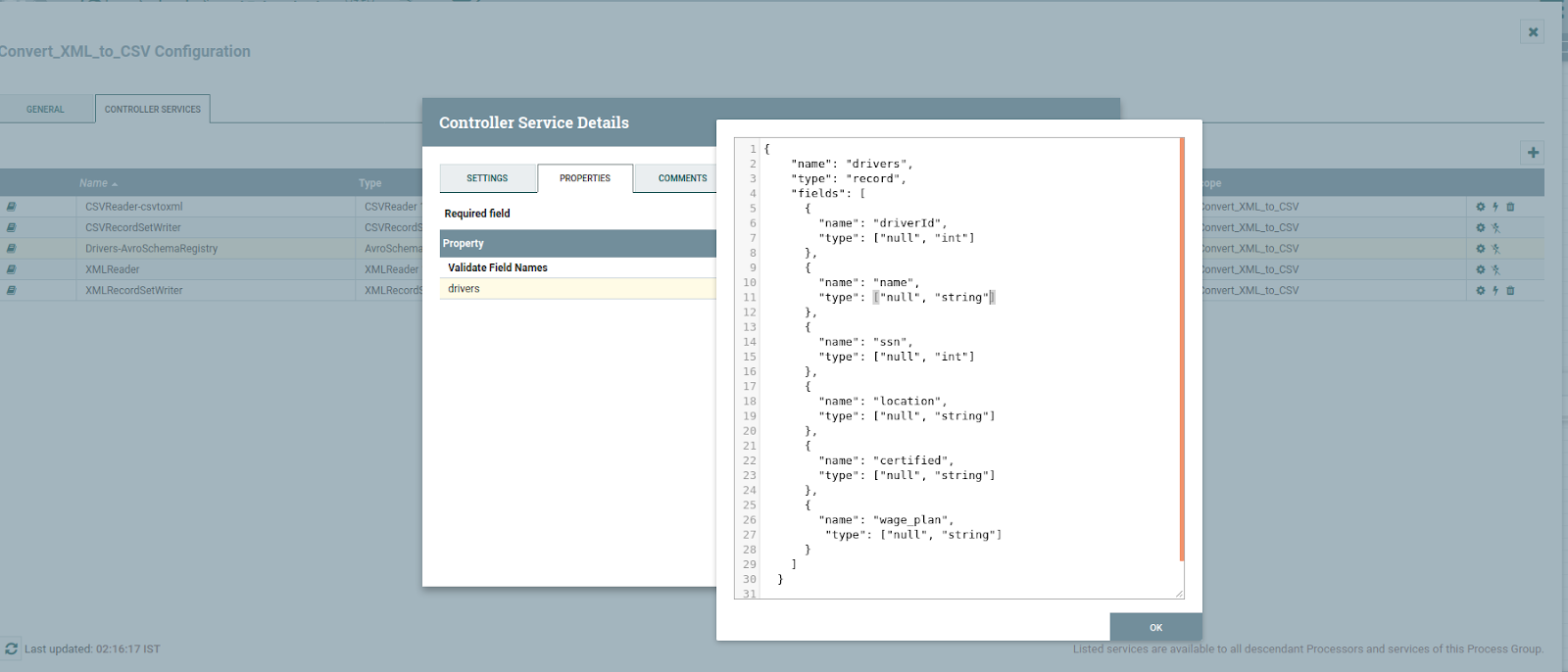
In the property, we need to provide the schema name, and in the value Avro schema, click ok and Enable AvroSchemaRegistry by selecting the lightning bolt icon/button. This will then allow you to enable the XMLReader and CSVRecordSetWriter controller services.
Configure the XMLReader as below:
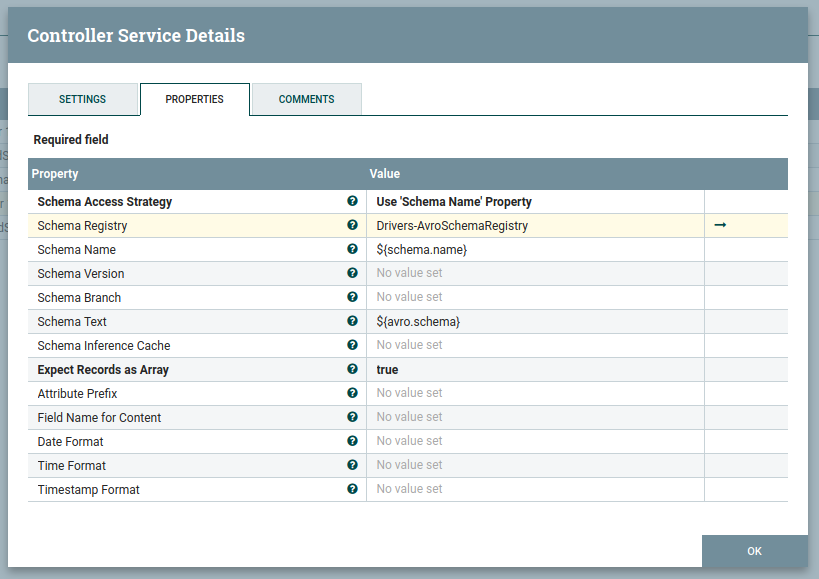
And also, configure the CSVRecordsetWriter as below :
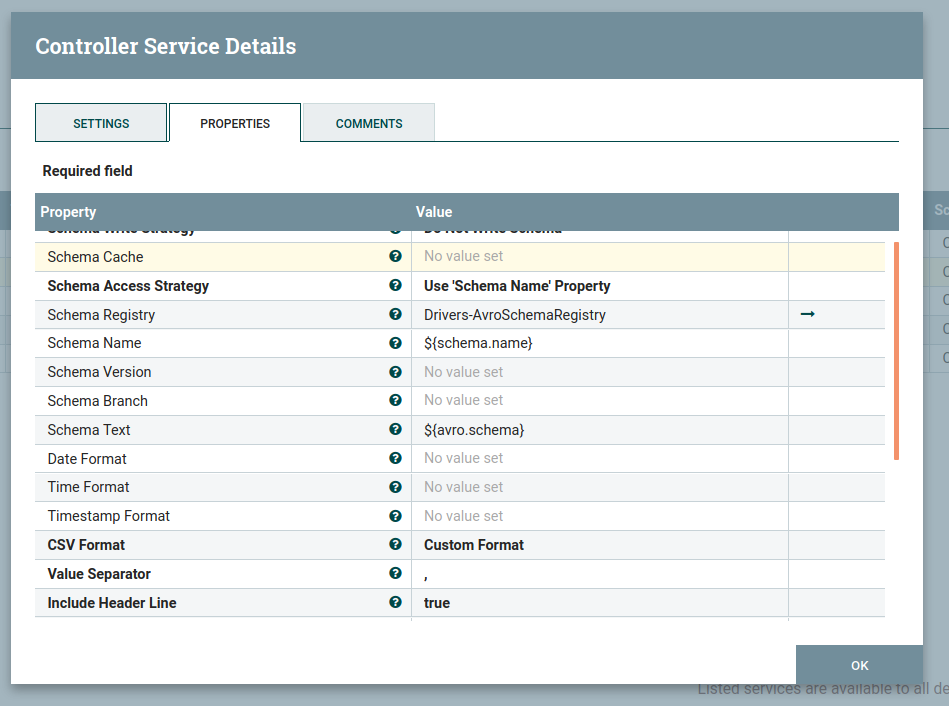
Then after that, click on apply, and then you will be able to see the XMLReader, and CSVRecordWriter controller services then Select the lightning bolt icons for both of these services. All the controller services should be enabled at this point.
Click on the thunder symbol and enable them.
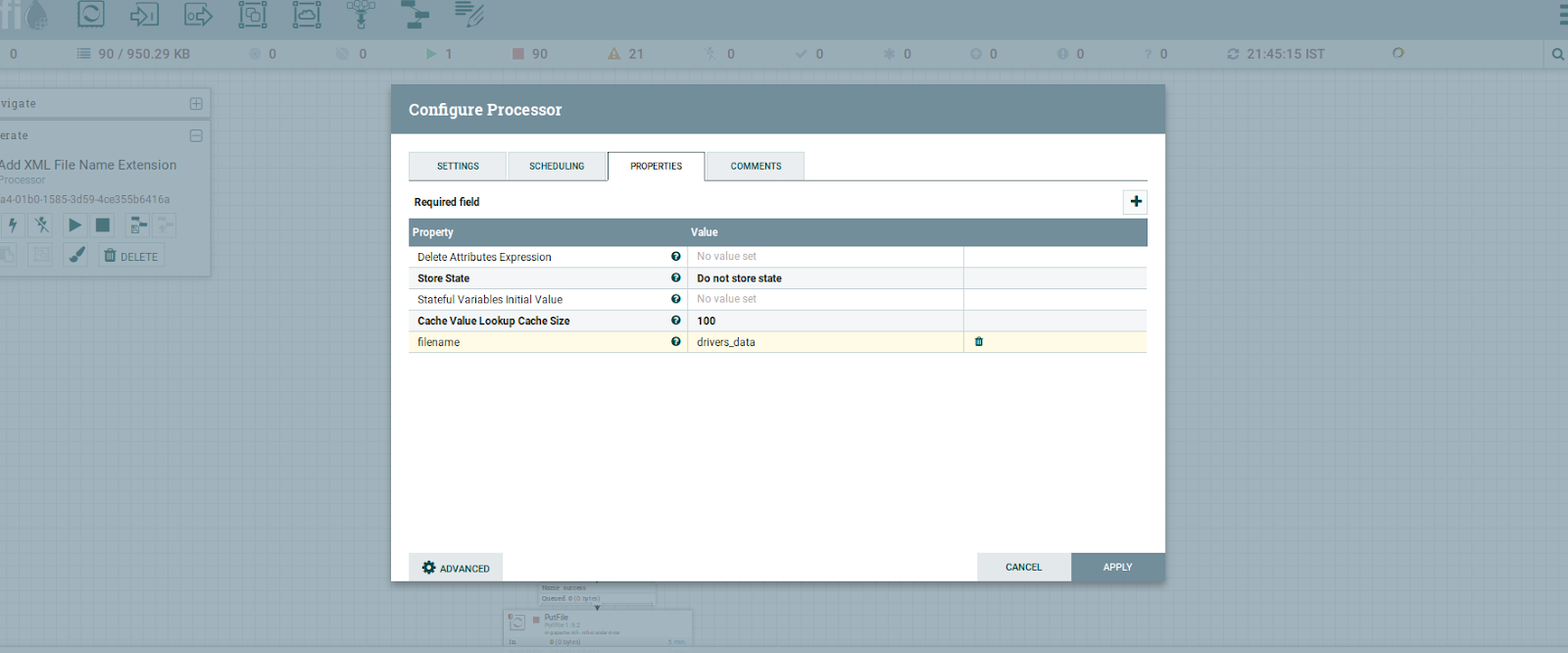
Step 4: Configure the UpdateAttribute to update the filename
Updates the Attributes for a FlowFile using the Attribute Expression Language and/or deletes the attributes based on a regular expression. Here, we are going to give the name for the FlowFile.
the output of the filename

Step 5: Configure the UpdateAttribute to update file extension
Updates the Attributes for a FlowFile by using the Attribute Expression Language and/or deletes the attributes based on a regular expression
Configured the update attribute processor as below, UpdateAttribute adds the file name with the CSV extension as an attribute to the FlowFile
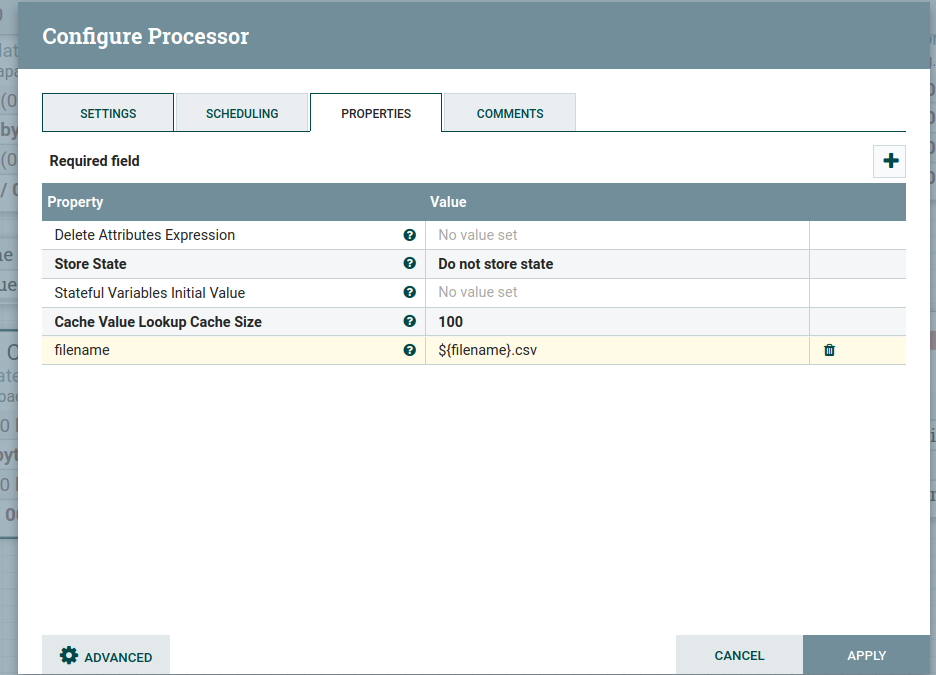
The output of the filename:

Step 6: Configure the PutFile
Writes the contents of a FlowFile to the local file system, it means that we are storing the converted CSV content in the local directory for that we configured as below:

As shown in the above image, we provided a directory name to store and access the file.
The output of the file stored in the local and data looks as below:

Conclusion
Here we learned to convert files from XML format to CSV format in NiFi.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Gautam Vermani
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic... Read More