Fetch data from HDFS and store it into the MySQL table in NiFi
This recipe helps you fetch data from HDFS and store it into the MySQL table in NiFi. Apache NiFi is used as open-source software for automating and managing the data flow between systems in most big data scenarios. It is a robust and reliable system to process and distribute data.
Recipe Objective: How to fetch data from HDFS and store it into the MySQL table in NiFi?
In most big data scenarios, Apache NiFi is used as open-source software for automating and managing the data flow between systems. It is a robust and reliable system to process and distribute data. It provides a web-based User Interface to create, monitor, and control data flows. Gathering data using rest API calls is widely used to collect real-time streaming data in Big data environments to capture, process, and analyze the data. Here in this scenario, we will fetch data from HDFS and store it into the MySQL table.
Table of Contents
System requirements :
- Install Ubuntu in the virtual machine. Click Here
- Install Nifi in Ubuntu Click Here
Here is my local Hadoop; we have a CSV file fetching CSV files from the HDFS. The file looks as shown in the below image.

Step 1: Configure The GetHDFS
Fetch files from Hadoop Distributed File System (HDFS) into FlowFiles. This processor will delete the file from HDFS after fetching it. To configure the GetHDFS processor, provide information as shown below.
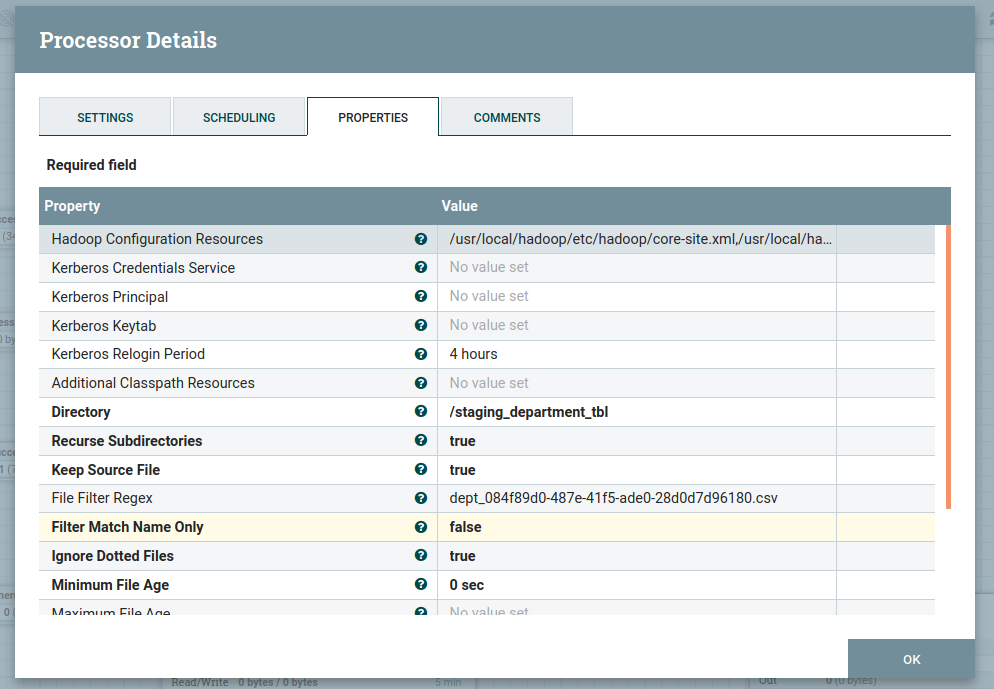
As shown in the above image, we need to provide the Hadoop resource configurations, A file, or a comma-separated list of files that contain the Hadoop file system configuration. Without this, Hadoop will search the classpath for a 'core-site.xml' and 'hdfs-site.xml' file or revert to a default configuration.
Provide the Directory Path to fetch data from and also provide file filter Regex as shown above. This processor will delete the file from HDFS after fetching it to keep it to fetch without deleting it from HDFS "Keep Source File" property value as True.
We scheduled this processor to run every 60 sec in the Run Schedule and Execution as the Primary node in Scheduling Tab.
Step 2: Configure The UpdateAttribute
Here we are configuring updateAttribute to added attribute "Schema.name" to configure the Avro schema registry.
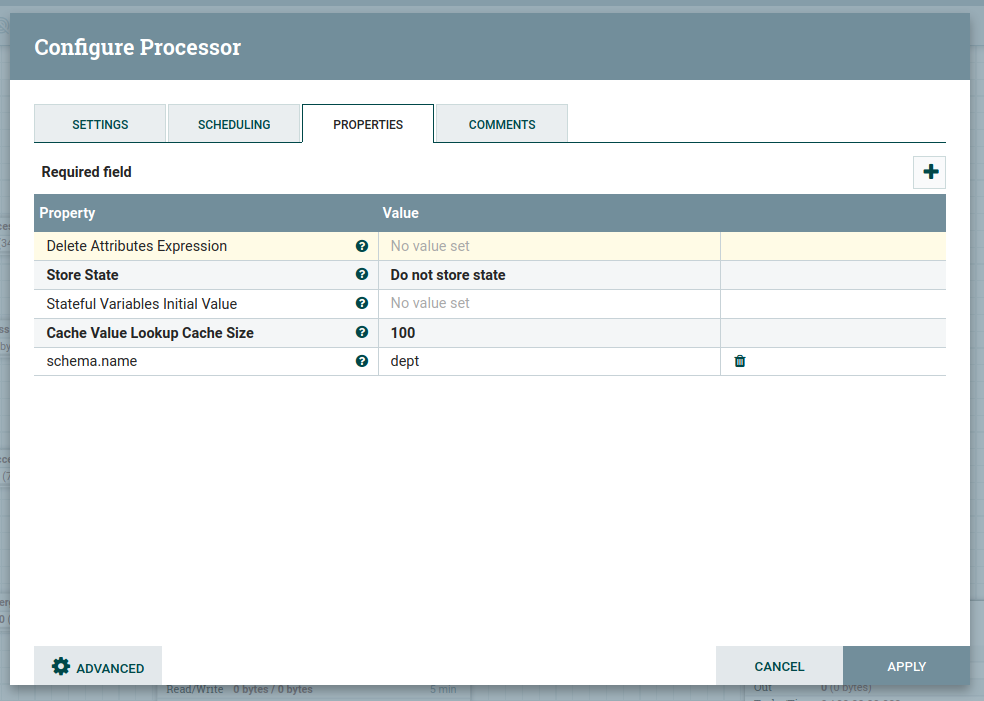
As shown in the above, we added a new attribute schema.name as dept is value.
Step 3: Configure the ConvertRecord and Create Controller Services
Using a CSV Reader controller service that references a schema in an AvroSchemaRegistry controller service. The AvroSchemaRegistry contains a "parlament_department" schema which defines information about each record (field names, field ids, field types), Using a Json controller service that references the same AvroSchemaRegistry schema.
In Convert record processor, the properties tab in the RecordReader value column drop down will get as below, then click on create new service.
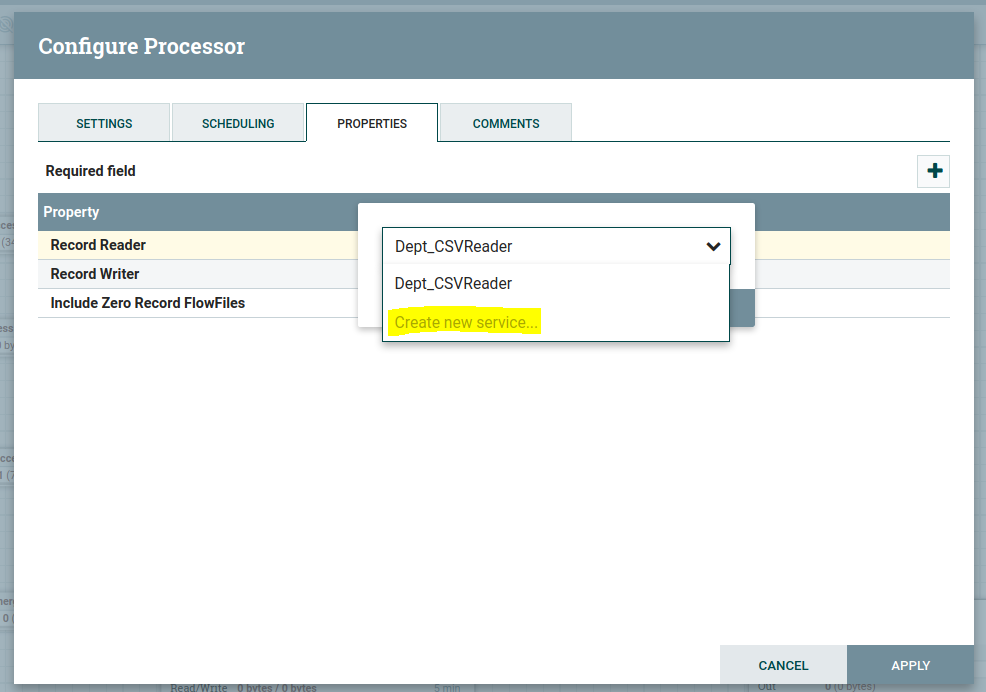
Then you will get the pop-up as below, select CSVReader in compatible controller service drop-down as shown below; we can also provide a name to the Controller service. Then click on Create.
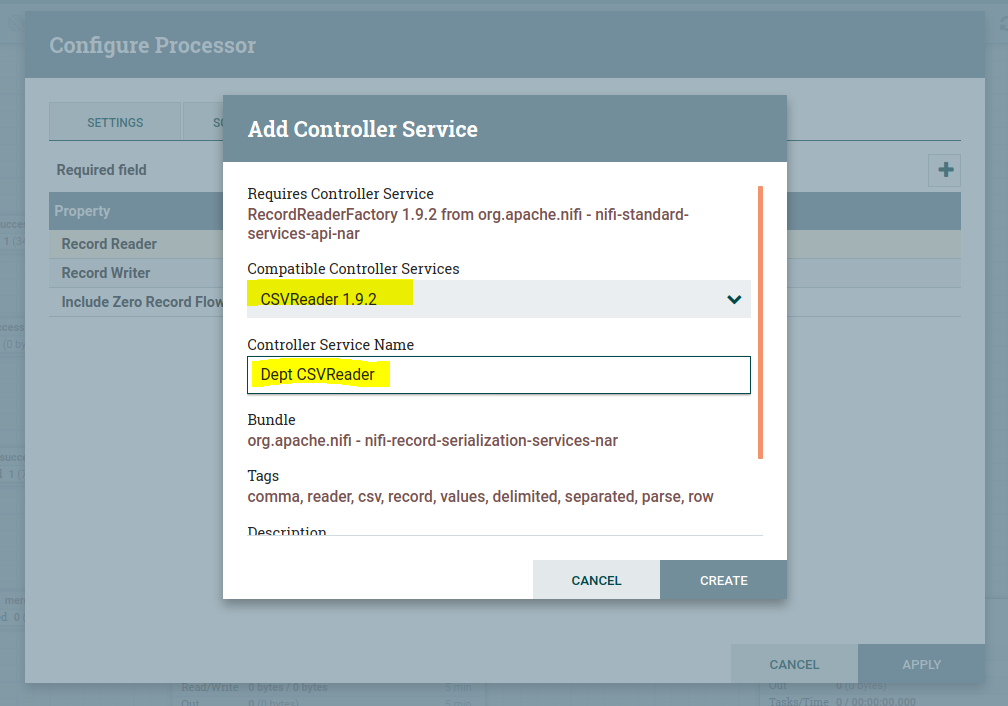
Follow the same steps to create a controller service for the JSON RecordSetWriter as below.
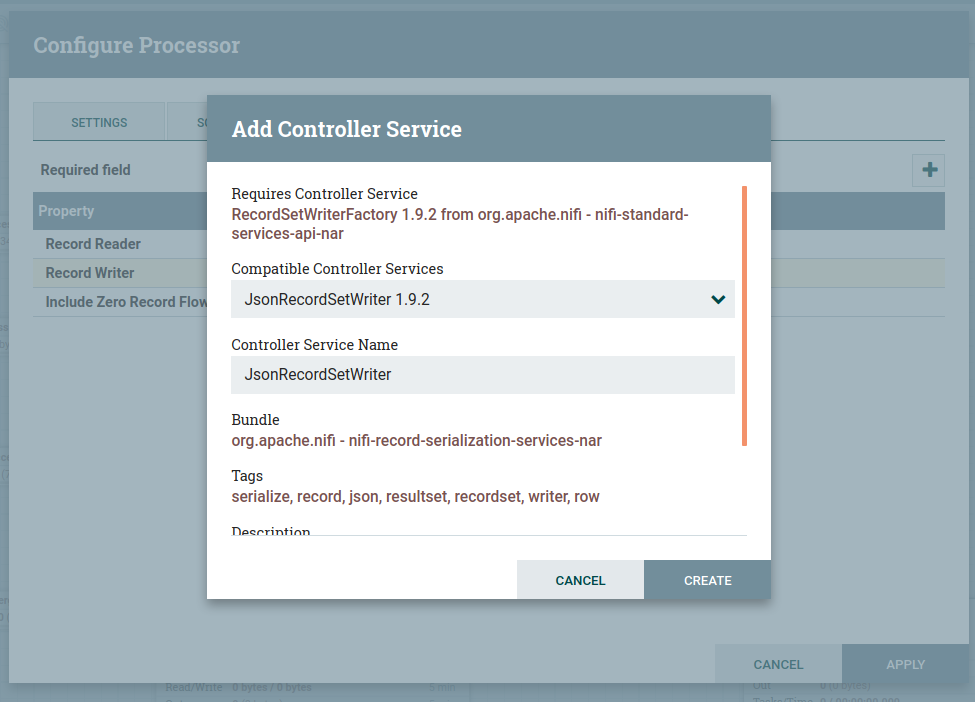
To Enable Controller Services Select the gear icon from the Operate Palette:
The output of the data:
Step 4: Configure the Split JSON
Splits a JSON File into multiple, separate FlowFiles for an array element specified by a JsonPath expression. Each generated FlowFile is compressed of an element of the specified array and transferred to relationship 'split,' with the original file transferred to the 'original' relationship. If the specified JsonPath is not found or does not evaluate an array element, the original file is routed to 'failure,' and no files are generated.
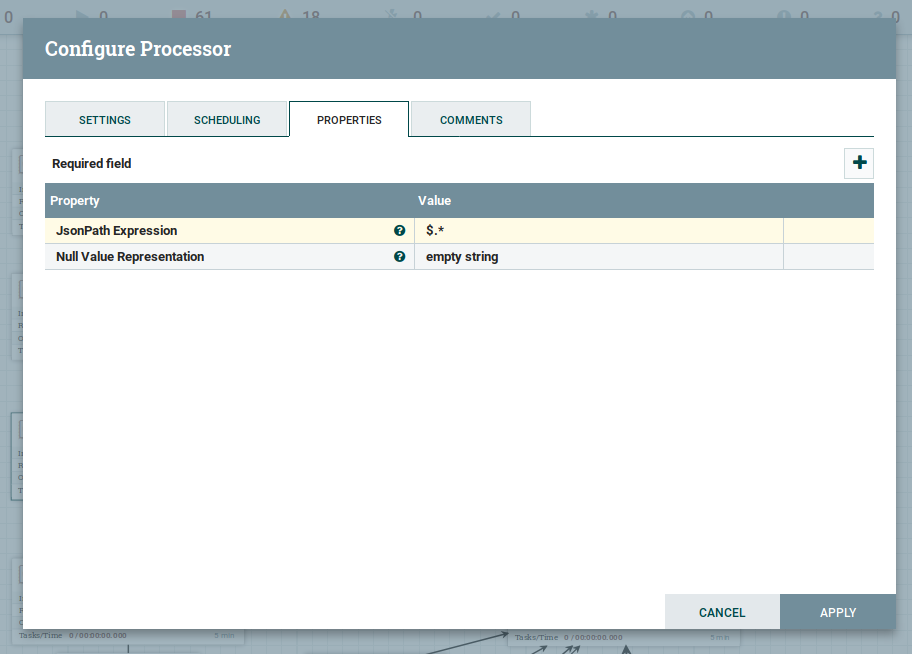
Since we have a JSON array in the output of the JSON data, we need to split the JSON object to call the attributes easily, so we are splitting the JSON object into a single line object as above.
Explore SQL Database Projects to Add them to Your Data Engineer Resume.
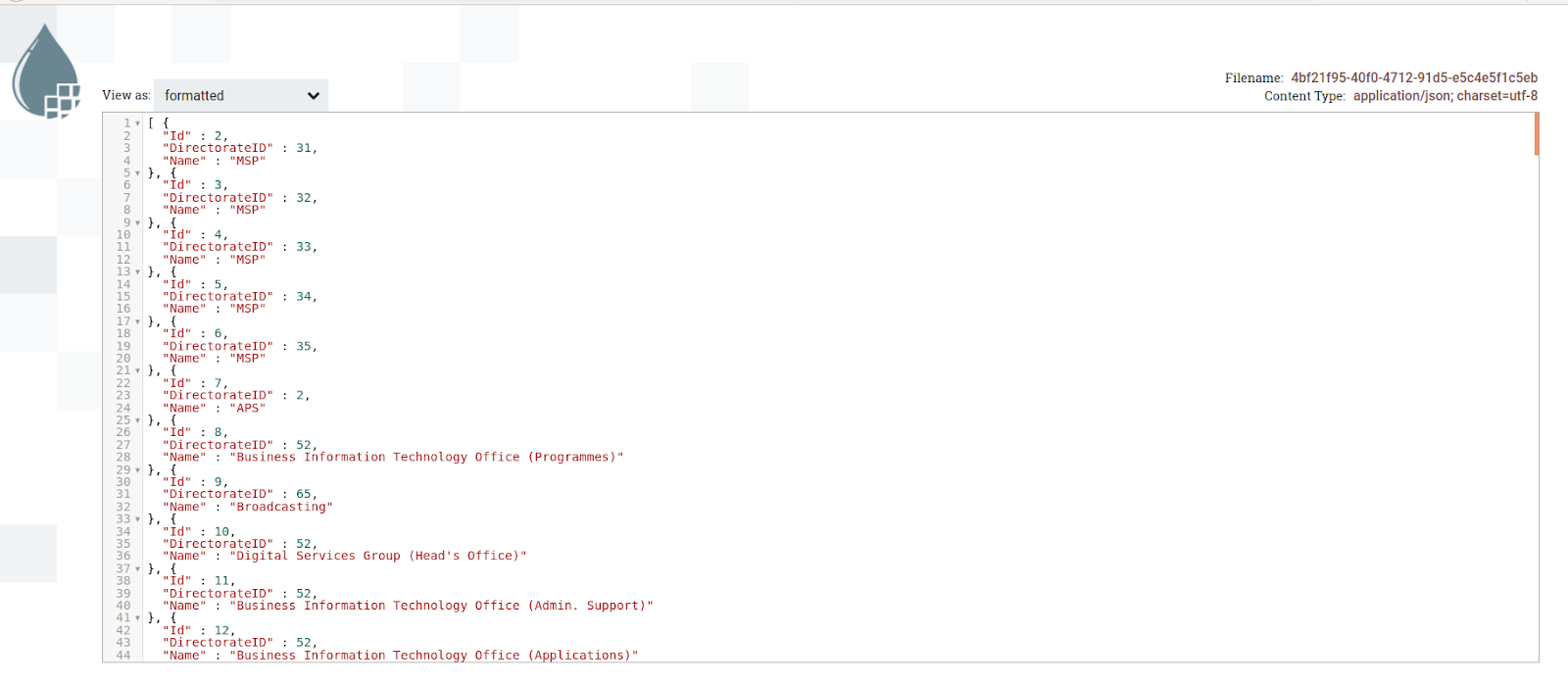
The output of the JSON data after splitting JSON object:

Step 5: Configure the ConvertJsonToSQL
Converts a JSON-formatted FlowFile into an UPDATE, INSERT, or DELETE SQL statement. The incoming FlowFile is expected to be a "flat" JSON message, meaning that it consists of a single JSON element, and each field maps to a simple type. Suppose a field maps to a JSON object, that JSON object will be interpreted as Text. If the input is an array of JSON elements, each element in the array is output as a separate FlowFile to the 'SQL' relationship.

Here we need to specify the JDBC Connection Pool (MySQL JDBC connection) to convert the JSON message to a SQL statement. The Connection Pool is necessary to determine the appropriate database column types. Also, we need to specify the statement type and Table name to insert data into that table, as shown in the above image.
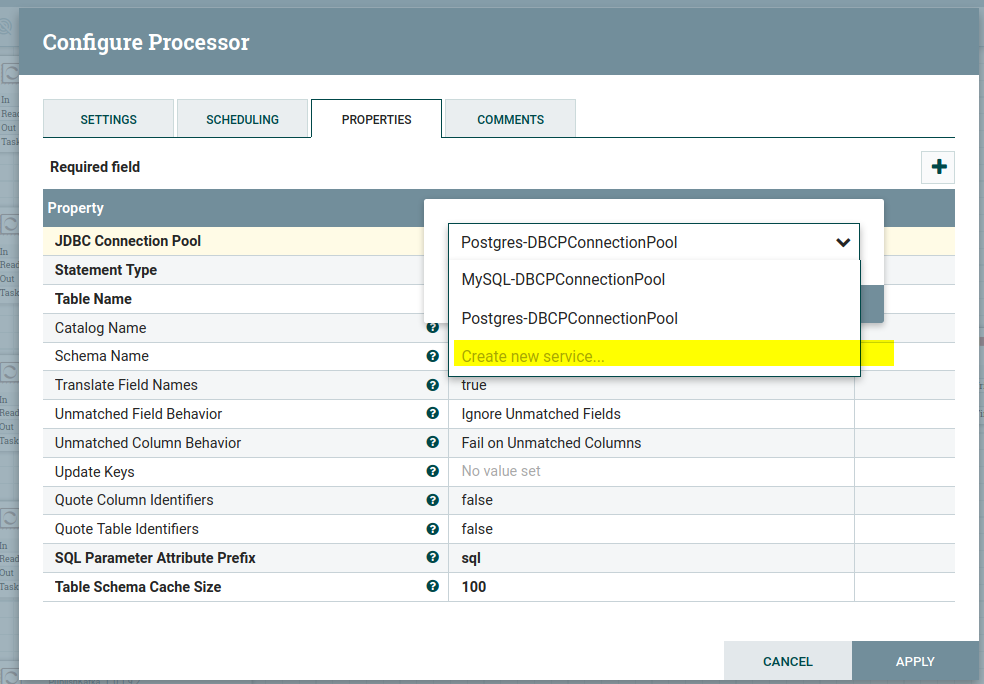
In the Database Connection Pooling service drop-down. Create a new service, DBCPConnectionPool, as shown above.
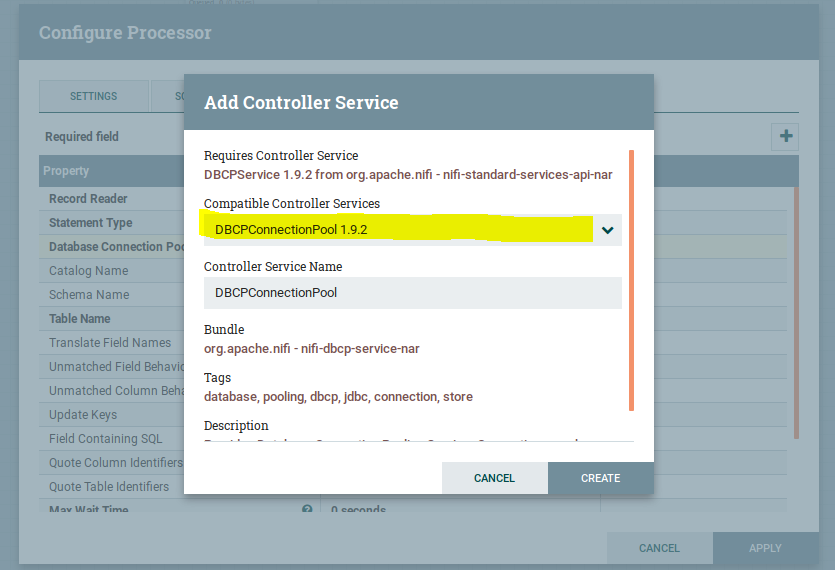
Select the DBCP connection in the drop-down and click on the create then it will create, then after providing the information in the configuration as below:
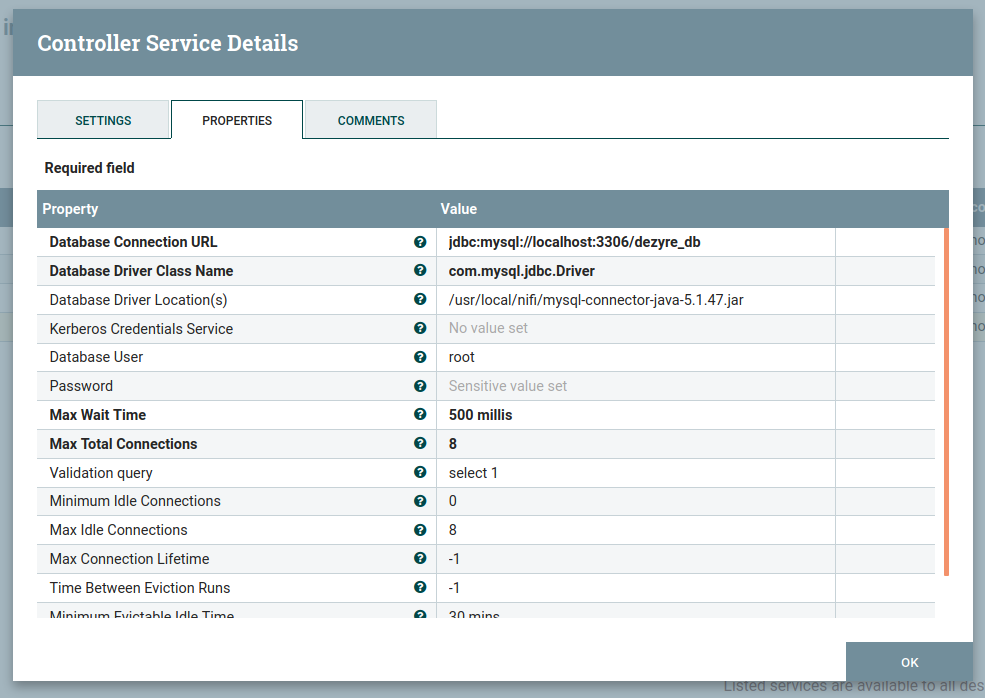
Provide the connection URL, Driver class Name, and the location driver, username, and password of the MySQL as shown in the image, then click on the apply to save the information .then after we get the below dialog box.

Then after we enable the controller service by clicking on the thunder symbol and Enable it.
Before running the flow, please create a table in the MySQL database as we specified in DBCPConnectionPool.
To Create a table in the MySQL database as shown below:

The output of the statement after converting JSON to SQL statement:
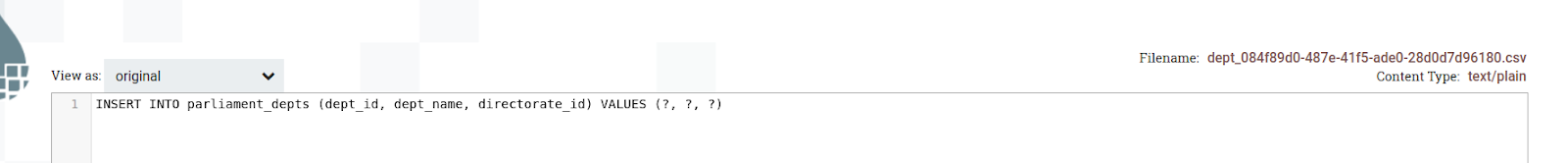
Step 6: Configure the PutSQL
Executes a SQL UPDATE or INSERT command. The content of an incoming FlowFile is expected to be the SQL command to execute. The SQL command may use the? to escape parameters. In this case, the parameters to use must exist as FlowFile attributes with the naming convention SQL.args.N.type and SQL.args.N.value, where N is a positive integer. The SQL.args.N.type is expected to be a number indicating the JDBC Type. The content of the FlowFile is expected to be in UTF-8 format.
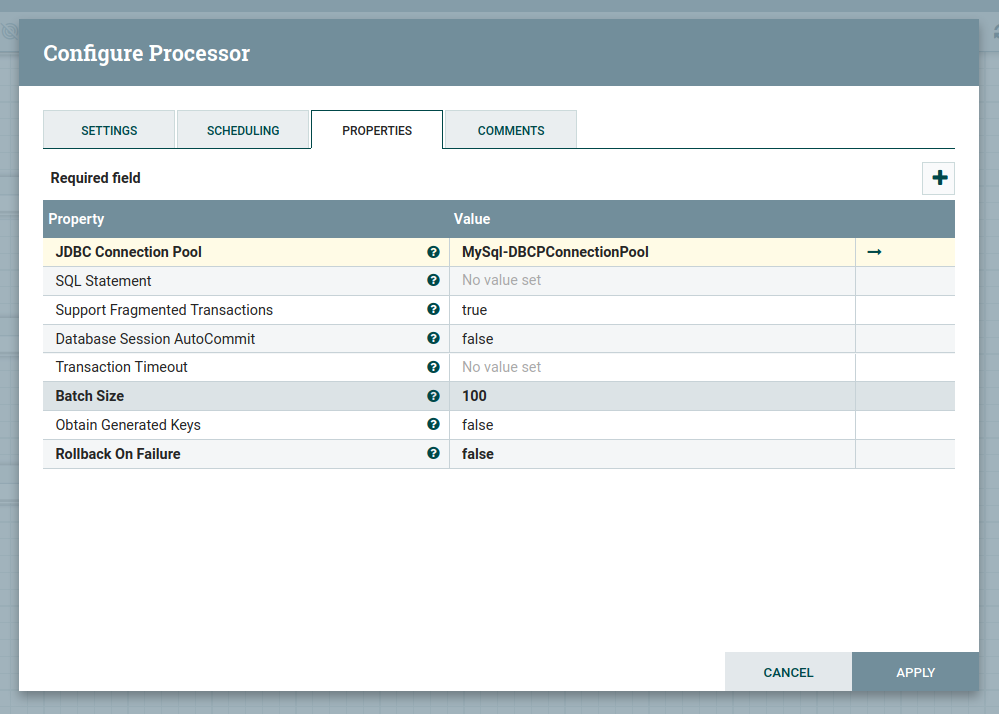
Here we need to select the JDBC connection pool as we created the connection in the above step.
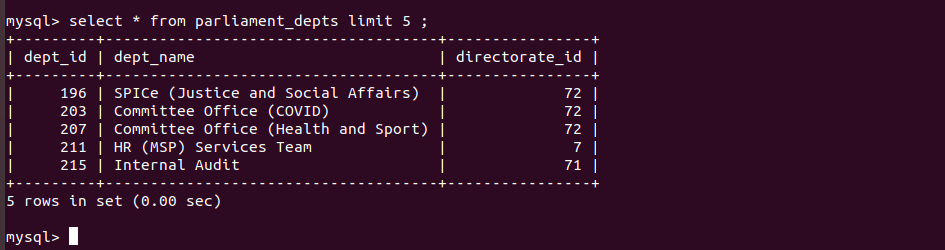
Output table data after insert into the table:
Conclusion
Here we learned to fetch data from HDFS and store it into the MySQL table in NiFi.
Download Materials
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Gautam Vermani
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic... Read More