How to implement GROUPING SETS clause in Hive
This recipe helps you implement GROUPING SETS clause in Hive
Recipe Objective: How to implement the GROUPING SETS clause in Hive?
Hive supports the GROUPING SETS clause in GROUP BY that specifies more than one GROUP BY option in the same record set. In this recipe, we look at the implementation of this GROUPING SETS clause in Hive.
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure Single node Hadoop and Hive are installed on your local EC2 instance. If not already installed, follow the below link to do the same.
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if HDFS and Hive are installed. If not installed, please find the links provided above for installations.
- Type "<your public IP>:7180" in the web browser and log in to Cloudera Manager, where you can check if Hadoop is installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the "Add Services" in the cluster to add the required services in your local instance.
Implementing GROUPING SETS clause in Hive:
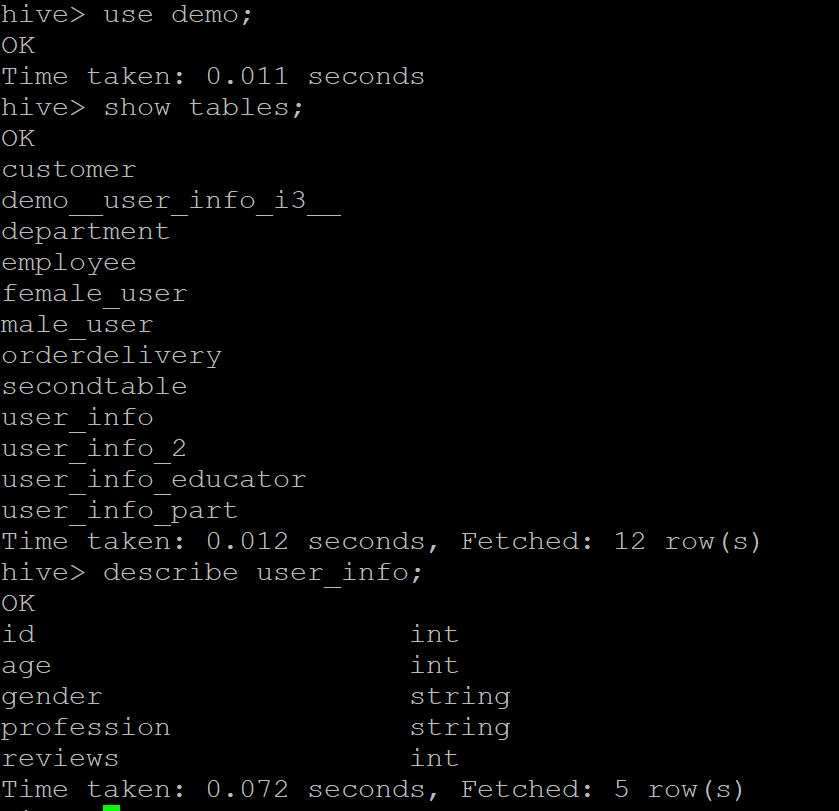
Throughout the recipe, we used the "user_info" table present in the "demo" database. Firstly, enter the database using the use demo; command and list all the tables in it using the show tables; command. Let us also look at the user_info table schema using the describe user_info; command.
Check Out Top SQL Projects to Have on Your Portfolio
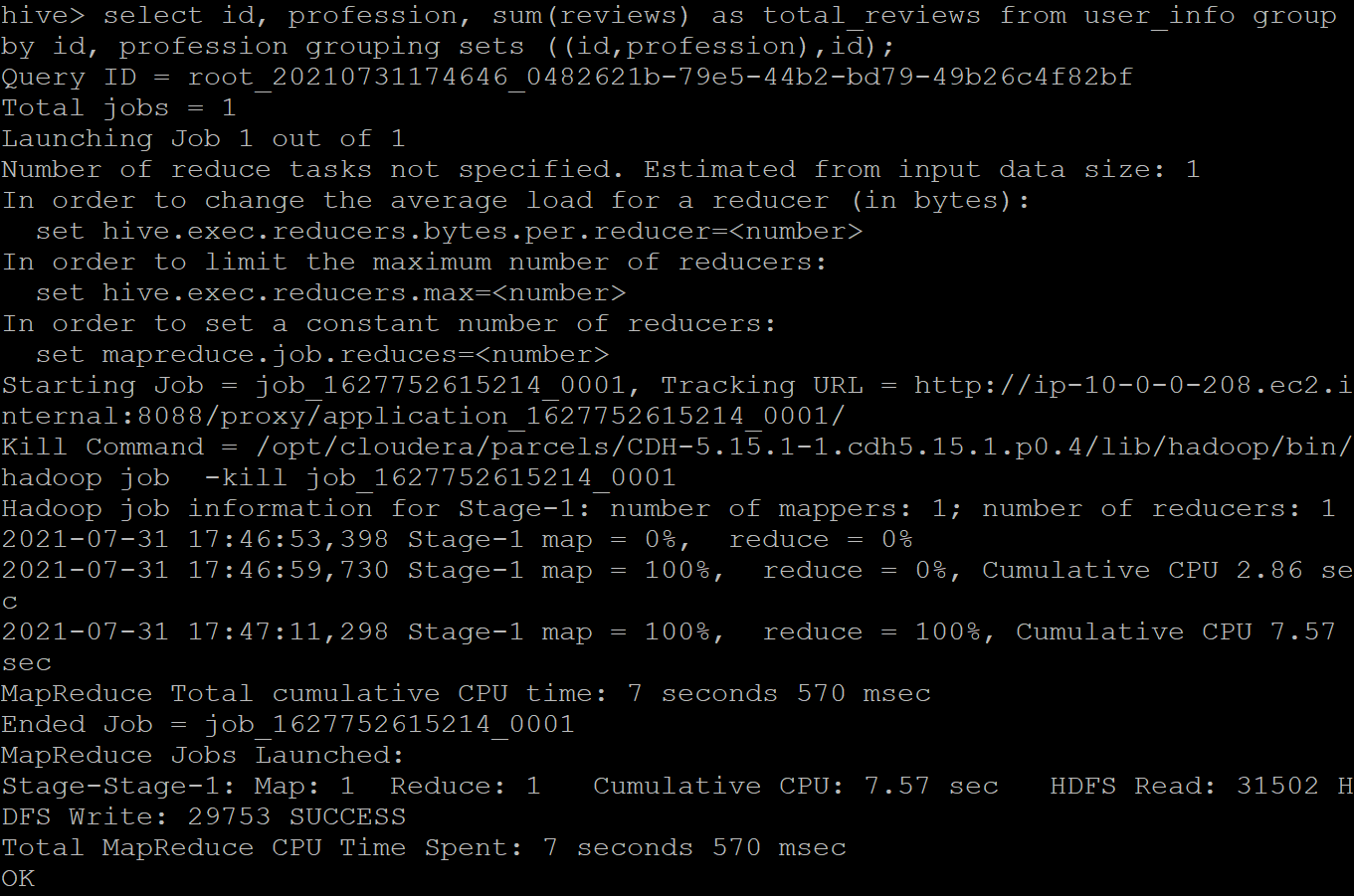
Implementing the GROUPING SETS clause over the attributes- id, profession, and reviews to fetch these details of the user grouped by the (id, profession) set. The query for the same is given below:
SELECT id, profession, sum(reviews) as total_reviews FROM user_info GROUP BY id, profession GROUPING SETS ((id,profession),id);
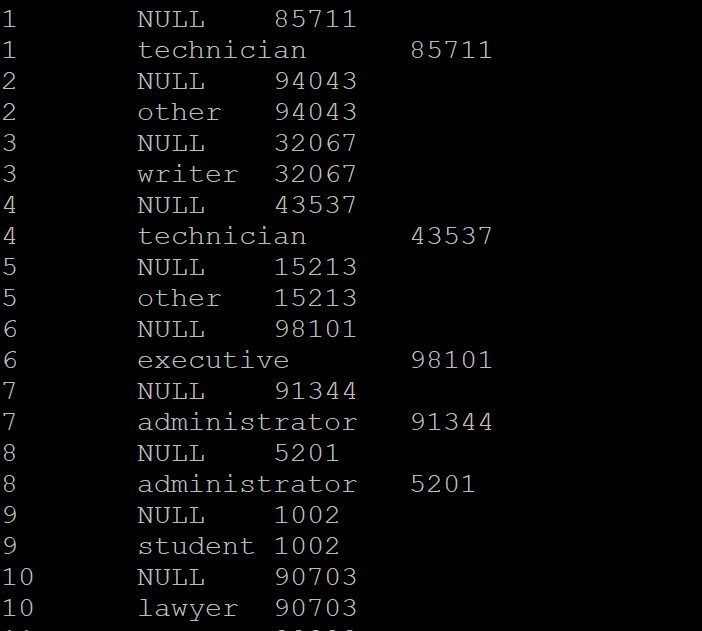
The above query calculates the number of users present in each profession and the total reviews given by all the users belonging to the same profession. Where the profession column is null, we have the total sum of reviews users' reviews across all the professions. The sample output is given below.
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Jingwei Li
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data.... Read More