How to implement OVER clause with MIN and MAX in Hive
This recipe helps you implement OVER clause with MIN and MAX in Hive
Recipe Objective: How to implement the OVER clause with MIN and MAX in Hive?
Hive has become one of the leading tools in the extensive data ecosystem and a standard for SQL queries over petabytes of data in Hadoop. As it deals with large amounts of data, aggregation and windowing help gather and express the data in summary to get more information about particular groups based on specific conditions. In this recipe, we implement the windowing functions MAX and MIN with the OVER clause.
Access Source Code for Airline Dataset Analysis using Hadoop
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure Single node Hadoop and Hive are installed on your local EC2 instance. If not already installed, follow the below link to do the same.
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if HDFS and Hive are installed. If not installed, please find the links provided above for installations.
- Type “<your public IP>:7180” in the web browser and log in to Cloudera Manager, where you can check if Hadoop is installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the “Add Services” in the cluster to add the required services in your local instance.
Implementing OVER clause with MIN and MAX in Hive:
Throughout the recipe, we used the “user_info” table present in the “demo” database. Firstly, enter the database using the use demo; command and list all the tables in it using the show tables; command. Let us also look at the user_info table schema using the describe user_info; command.

MAX(): The MAX function is used to compute the maximum rows in the column or expression. Let us try implementing this by calculating most of the reviews given by the users concerning each profession. We partition the entire data over the profession column and pass the reviews column to the MAX function to implement this. Query to do the same is given below.
SELECT profession, MAX(reviews) OVER (PARTITION BY profession) FROM user_info;

Sample output is given below:

MIN(): Similar to the MAX function, we compute the minimum of the rows in the column or expression. Let us try implementing this by calculating the minimum of the reviews given by the users concerning each profession. We partition the entire data over the profession column and pass the reviews column to the MIN function to implement this. Query to do the same is given below.
SELECT profession, MIN(reviews) OVER (PARTITION BY profession) FROM user_info;
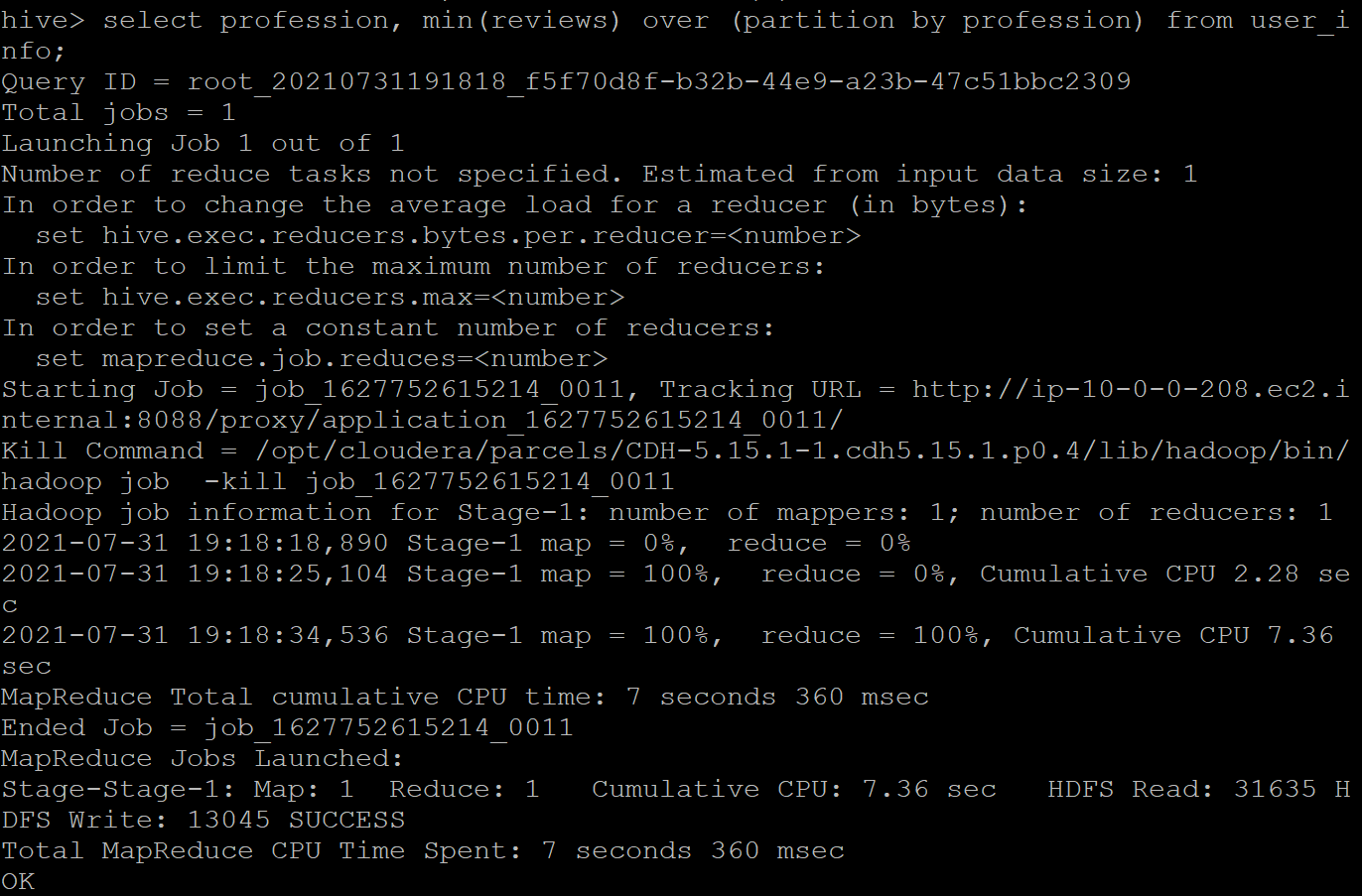
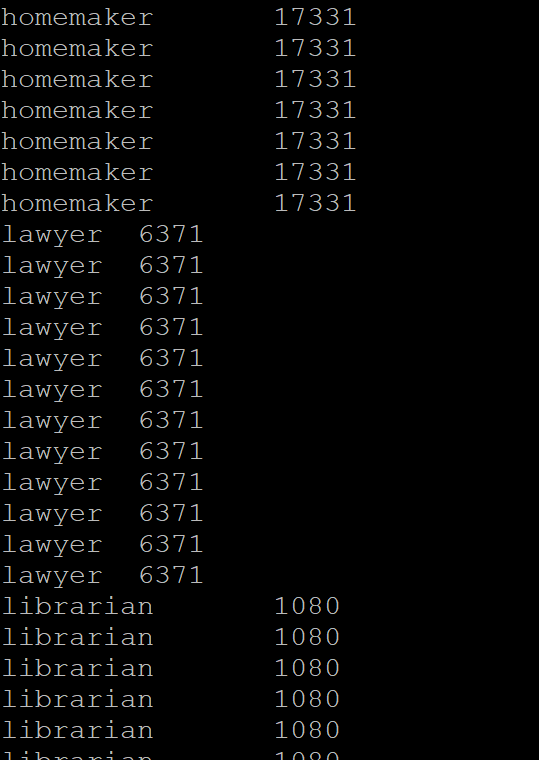
The sample output is given below.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Gautam Vermani
Having worked in the field of Data Science, I wanted to explore how I can implement projects in other domains, So I thought of connecting with ProjectPro. A project that helped me absorb this topic... Read More