How to initiate a streaming query in Pyspark
This recipe helps you initiate a streaming query in Pyspark
Recipe Objective: How to Initiate a streaming query in Pyspark?
In most big data scenarios, data merging and data aggregation are an essential part of the day-to-day activities in big data platforms. Spark Streaming is an extension of the core Spark API that allows data engineers and data scientists to process real-time data from various sources, including (but not limited to) Kafka, Flume, and Amazon Kinesis. This processed data can be pushed out to file systems, databases, and live dashboards. In this scenario, we are going to initiate a streaming query in Pyspark.
Table of Contents
System requirements :
- Install Ubuntu in the virtual machine click here
- Install single-node Hadoop machine click here
- Install pyspark or spark in Ubuntu click here
- The below codes can be run in Jupyter notebook or any python console.
Step 1: Import the modules
In this scenario, we are going to import the pyspark and pyspark SQL modules and create a spark session as below :
Import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType
spark = SparkSession.builder\
.master("local").appName("pyspark_stream_setup").getOrCreate()
Step 2: Create Schema
Here we are going to create a schema and assign it to the newly created DataFrame.
schooldrivers_Schema = StructType() \
.add("school_year", "string")\
.add("vendor_name", "string")\
.add("type_of_service", "string")\
.add("active_employees", "string")\
.add("job_type", "string")
Then we are going to print the content of the schema. Please follow the below code.
schooldrivers_Schema.simpleString()
The output of the code:

In the output, we can see both the columns just added in the schema.
Step 3: Create Dataframe from Streaming
Here we are going to create the DataFrame from streaming as shown in the below code.
schooldrivers_stream_Df = spark.readStream\
.option("sep", ",")\
.schema(schooldrivers_Schema)\
.csv("/home/hduser/school_drives")
To make sure the DataFrame is in streaming mode, we use the isStreaming method shown below here.
schooldrivers_stream_Df.isStreaming
The output of the dataframe is in streaming mode:

Step 4: Write to Stream
Here we will create a stream using the writeStream method, which will write into the console and keep on appending the incoming data.
query = schooldrivers_stream_Df.writeStream\
.format("console").outputMode("append").start()
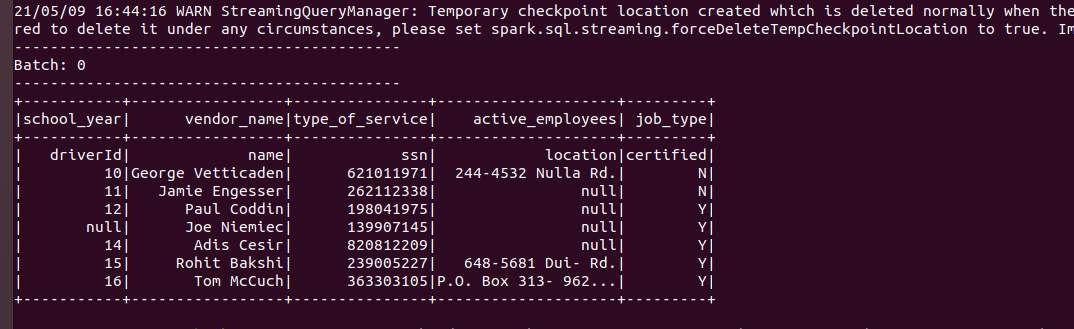
When you run code, you will not see any output. When you place the drivers-1.csv file into the school_drivers directory, notice what happens then. You can observe the following output in the console where you start the jupyter notebook.

The output of the streaming data: when we placed drivers-1.csv, it gave an output.
Conclusion
Here we learned to Initiate a streaming query in Pyspark.
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Savvy Sahai
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of... Read More