Data aggregation on dataframe grouped on multiple key pyspark
This recipe helps you perform data aggregation on a DataFrame grouped on multiple keys in pyspark. PySpark is an interface for Apache Spark in Python and it supports most of Spark’s features such as Spark SQL, DataFrame.
Recipe Objective: How to perform data aggregation on a DataFrame, grouped on multiple keys in pyspark?
Data merging and data aggregation are essential parts of big data platforms' day-to-day activities in most big data scenarios. In this scenario, we will perform data aggregation on a DataFrame, grouped on multiple keys.
Build Log Analytics Application with Spark Streaming and Kafka
Table of Contents
System requirements :
- Install Ubuntu in the virtual machine click here
- Install single-node Hadoop machine click here
- Install pyspark or spark in Ubuntu click here
- The below codes can be run in Jupyter notebook or any python console.
Step 1: Prepare a Dataset
Here we use the employee-related comma-separated values (CSV) dataset to read in jupyter notebook from the local. Download the CSV file into your local download, download the data set which we are using in this scenario
The output of the dataset:

Step 2: Import the modules
In this scenario, we are going to import the pyspark and pyspark SQL modules and create a spark session as below :
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
from pyspark.sql.types import ArrayType, DoubleType, BooleanType
from pyspark.sql.functions import col,array_contains
Create a spark session as below
spark = SparkSession.builder.appName('Aggregation on multi cols').getOrCreate()
Read the CSV file below
Salesdf = spark.read.csv("/home/bigdata/Downloads/salesrecords.csv")
Salesdf.printSchema()
The output of the above lines:

Step 3: Create a schema
Here we are creating a StructField for each column. Then we will develop a schema of the full DataFrame. We can make that using a StructType object, as the following code line as below:
schema = StructType() \
.add("Region",StringType(),True) \
.add("Country",StringType(),True) \
.add("Item Type",StringType(),True) \
.add("Sales Channel",StringType(),True) \
.add("Order Priority",StringType(),True) \
.add("Order ID",IntegerType(),True) \
.add("Units Sold",IntegerType(),True) \
.add("Unit Price",DoubleType(),True) \
.add("Unit Cost",DoubleType(),True) \
.add("Total Revenue",DoubleType(),True) \
.add("Total Cost",DoubleType(),True) \
.add("Total Profit",DoubleType(),True)
Step 4: Read CSV file
Here we are going to read the CSV file from local where we downloaded the file, and also we are specifying the above-created schema to CSV file as below code:
SalesSchemaDf=spark.read.format("csv") \
.option("header", True) \
.schema(schema) \
.load("/home/bigdata/Downloads/salesrecords.csv")
SalesSchemaDf.printSchema()
The output of the above lines
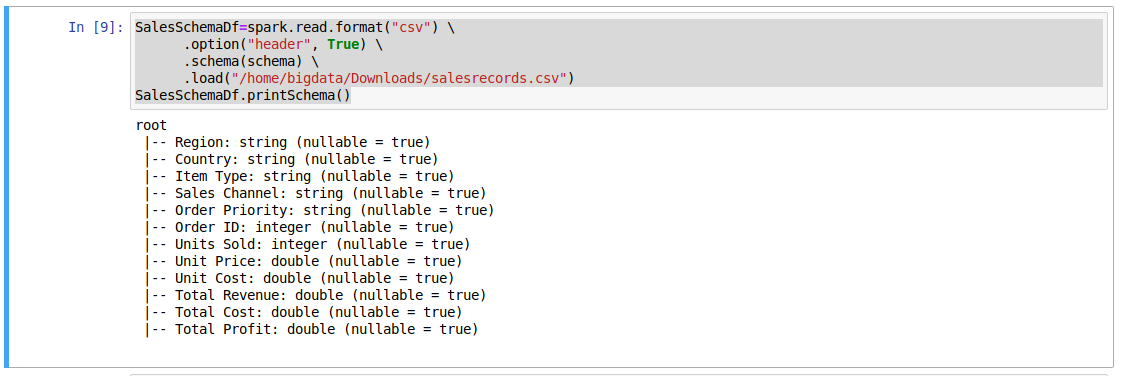
To show the top 4 lines from the dataframe
SalesSchemaDf.show(4)
The output of the above line
Step 5: To Perform Aggregation data on multiple column key
We are going to group data on the gender column using the groupby() function. After that, we are going to apply the mean() function.
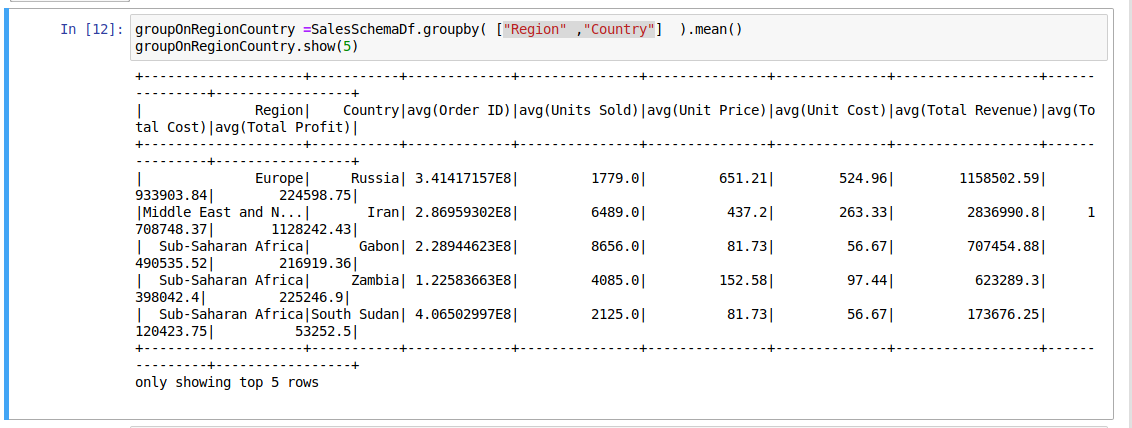
To Calculating mean value group by Region and country as shown in below
groupOnRegionCountry =SalesSchemaDf.groupby( ["Region" ,"Country"] ).mean()
groupOnRegionCountry.show(5)
The output of the above lines:
To calculate the sum of total profit using sum() function and group by groupby() function
sumofTotalprofit =SalesSchemaDf.groupby("Country").sum("Total Profit")
sumofTotalprofit.show()
The output of the above lines:

Here we are going to find out the distinct count of the Region, country, and ItemType as shown below
from pyspark.sql.functions import countDistinct
dist_counts = SalesSchemaDf.select(countDistinct("Region" ,"Country","Item Type"))
dist_counts.show(5)
The output of the above code:

Conclusion
Here we learned to perform data aggregation on a DataFrame, grouped on multiple keys in pyspark.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ameeruddin Mohammed
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good... Read More