How to save a dataframe as a JSON file using PySpark
This recipe helps you save a dataframe as a JSON file using PySpark
Recipe Objective: How to save a dataframe as a JSON file using PySpark?
In this recipe, we learn how to save a dataframe as a JSON file using PySpark.
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure the following installations are done on your local EC2 instance.
- Single node Hadoop - click here
- Apache Hive - click here
- Apache Spark -click here
- PySpark - click here
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if PySpark is installed. If not installed, please find the links provided above for installations.
- Type “<your public IP>:7180” in the web browser and log in to Cloudera Manager, where you can check if Hadoop, Hive, and Spark are installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the “Add Services” in the cluster to add the required services in your local instance.
Steps to save a dataframe as a JSON file:
Step 1: Set up the environment variables for Pyspark, Java, Spark, and python library. As shown below:

Please note that these paths may vary in one’s EC2 instance. Provide the full path where these are stored in your instance.
Step 2: Import the Spark session and initialize it. You can name your application and master program at this step. We provide appName as “demo,” and the master program is set as “local” in this recipe.

Step 3: We demonstrated this recipe using the “user.csv” file. Make sure that the file is present in the HDFS. Check for the same using the command:
hadoop fs -ls <full path to the location of file in HDFS>
Read the CSV file into a dataframe using the function spark.read.load().
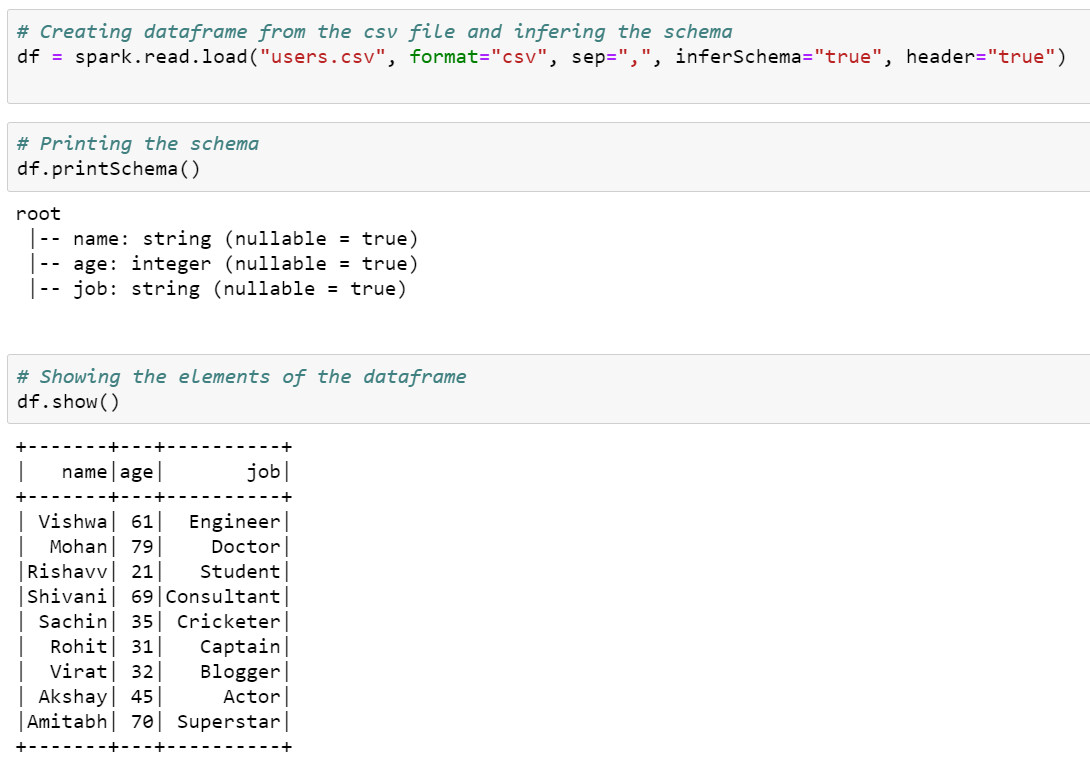
Step 4: Call the method dataframe.write.json() and pass the name you wish to store the file as the argument.

Now check the JSON file created in the HDFS and read the “users_json.json” file.

This is how a dataframe can be converted to JSON file format and stored in the HDFS.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ray han
I think that they are fantastic. I attended Yale and Stanford and have worked at Honeywell,Oracle, and Arthur Andersen(Accenture) in the US. I have taken Big Data and Hadoop,NoSQL, Spark, Hadoop... Read More