How to select the Files to Import using Sqoop
This recipe helps you select the Files to Import using Sqoop
Recipe Objective: How to select the Files to Import using Sqoop?
This recipe teaches us to select files present in RDBMS and insert them into HDFS using the Sqoop tool. It was designed to transfer data between HDFS and RDBMS using a JDBC driver to connect.
Prerequisites:
Before proceeding with the recipe, make sure the following installations are done on your local EC2 instance.
- Single node Hadoop - click here
- Apache Sqoop -click here
- MySQL - click here
Steps to set up the environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance.
- To do this, type “<your public IP>:7180” in the web browser and log in to Cloudera Manager, where you can check if Hadoop and Sqoop are installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the “Add Services” in the cluster to add the required services in your local instance.
Transferring files from MySQL to HDFS:
The following steps are involved in pulling the data present in the MySQL table and inserting it into HDFS. We see how sqoop is used to achieve this. In this example, we created apriori using the “retailinfo” table present in our “test” database.
Step 1: Log in to MySQL using
mysql -u root -p;
Enter the required credentials.
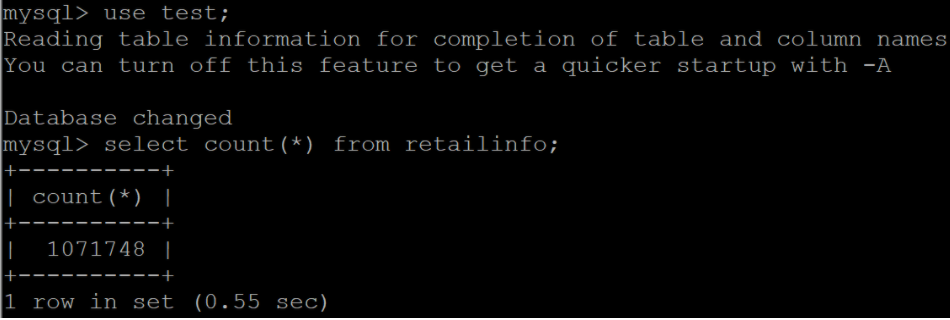
Step 2:Before transferring the selected file, check how many records are present in it. To do this, change to the required database using.
use <database name>
Now, check the number of records present in the table, i.e., the file we select to move its data into HDFS, using “count(*).”
select count(*) from <tablename>
Step 3: Before running the “sqoop import” command, ensure that the target directory is not already present. Otherwise, the import command throws an error. To check this, let us try deleting the directory that we wish to use as our target directory.
hadoop fs -rm -r < target directory >

Step 4: Let us now do the “sqoop import” job to pull the data from the selected file from MySQL and insert it into HDFS using the command:
sqoop import \
--connect jdbc:mysql://localhost/<database name> \
--table <table name> \
--username <username> --password <password> \
--target-dir <target location in HDFS> \
-m <no. of Mapper jobs you wish to create>
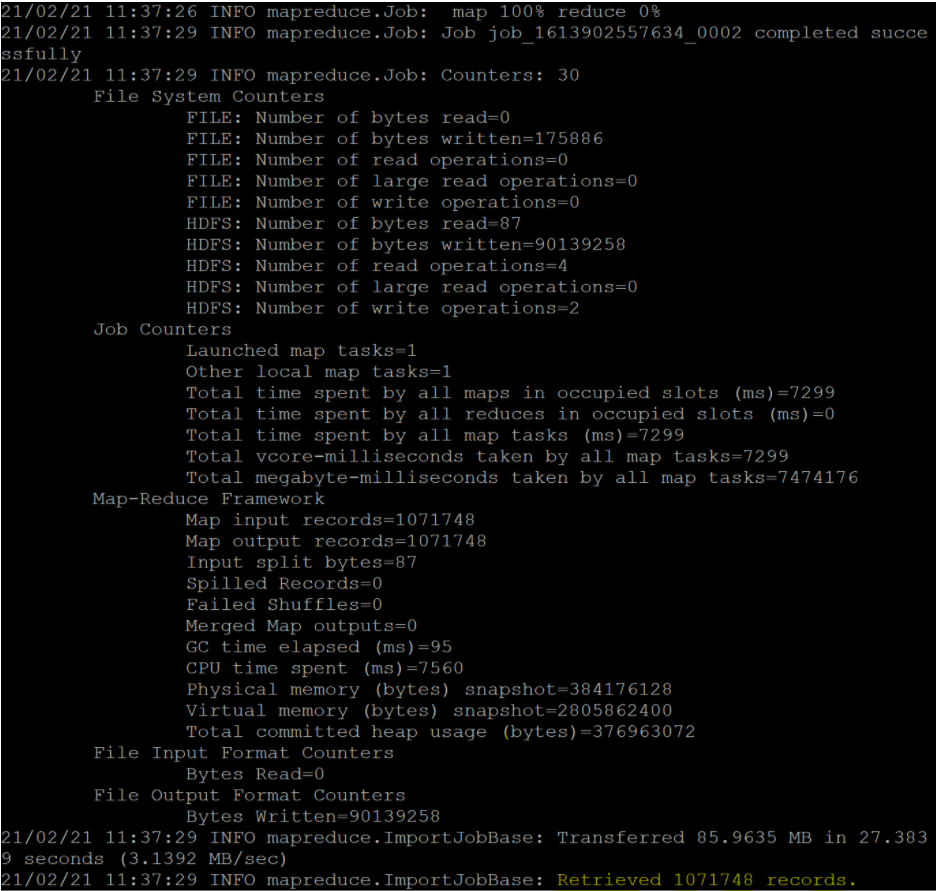
In our example, the database is “test,” the selected file is the table “retailinfo,” and our target location in HDFS is in the directory “/user/root/online_basic_command.” We proceeded with only one mapper job.

Upon successful data transfer, the output looks similar to:

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ray han
I think that they are fantastic. I attended Yale and Stanford and have worked at Honeywell,Oracle, and Arthur Andersen(Accenture) in the US. I have taken Big Data and Hadoop,NoSQL, Spark, Hadoop... Read More