How to work with virtual columns in Hive
This recipe helps you work with virtual columns in Hive
Recipe Objective: How to work with virtual columns in Hive?
Like many other databases, Hive provides virtual columns that are not stored in the datafiles but can be accessed in queries. Usually, they provide some metadata that can be very handy. One is INPUT__FILE__NAME, which is the input file's name for a mapper task, and the other is BLOCK__OFFSET__INSIDE__FILE, which is the current global file position. The block compressed file is the current block's file offset, which is the current block's first byte's file offset. In this recipe, we work with virtual columns in Hive.
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure Single node Hadoop and Hive are installed on your local EC2 instance. If not already installed, follow the below link to do the same.
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if HDFS and Hive are installed. If not installed, please find the links provided above for installations.
- Type "<your public IP>:7180" in the web browser and log in to Cloudera Manager, where you can check if Hadoop is installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the "Add Services" in the cluster to add the required services in your local instance.
Working with Virtual columns in Hive:
Step 1: Start a database using the use <database name> command. Here, "demo." The command show tables; lists all the tables present in that database.

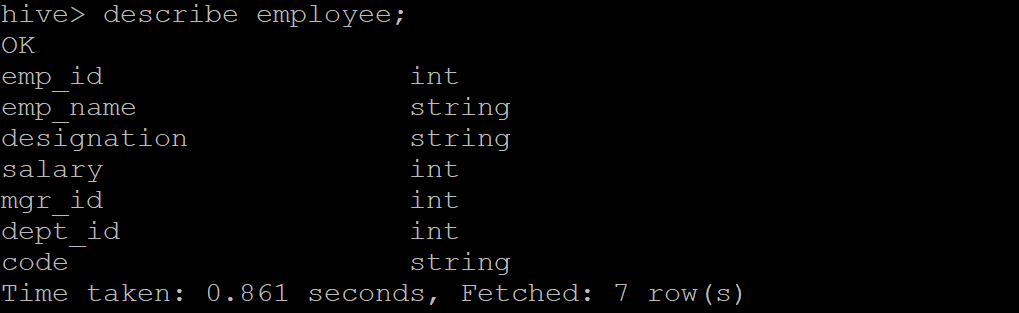
Step 2: Look at the table schema by giving the describe <table name> command. Here, "employee."
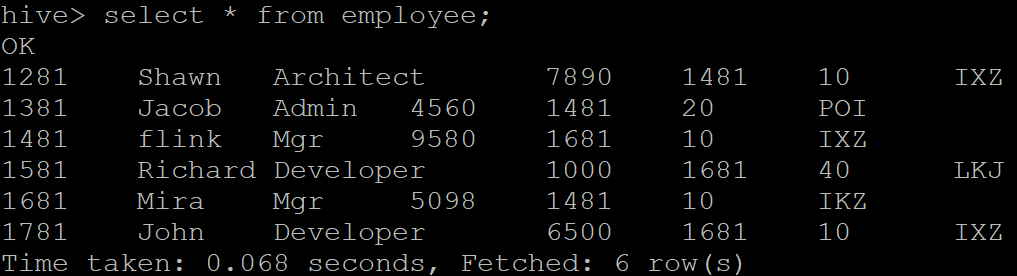
Step 3: Check the data present in the table using the select * from <table name> command.
Step 4: We can retrieve the file name for this mapper task by providing the virtual column - "INPUT__FILE__NAME" in the select statement and "BLOCK__OFFSET__INSIDE__FILE" to see the current global file position. Let us now try passing these two virtual columns along with the "emp_id" from the employee table and observe the output. The output contains three values for each record: mapper task file name, current global file position, and emp_id.

{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ed Godalle
I am the Director of Data Analytics with over 10+ years of IT experience. I have a background in SQL, Python, and Big Data working with Accenture, IBM, and Infosys. I am looking to enhance my skills... Read More