How to extract values from XML data in NiFi
This recipe helps you extract values from XML data in NiFi
Recipe Objective: How to Extract values from XML data in NiFi?
In most big data scenarios, Apache NiFi is used as open-source software for automating and managing the data flow between systems. It is a robust and reliable system to process and distribute data. It provides a web-based User Interface to create, monitor, and control data flows. Gathering data from databases is widely used to collect real-time streaming data in Big data environments to capture, process, and analyze the data. The XML data is commonly used in big data-based large-scale environments. We will split the XML file into multiple XML documents and extract the attributes and their values from the XML Data in this scenario.
Build a Real-Time Dashboard with Spark, Grafana and Influxdb
Table of Contents
- Recipe Objective: How to Extract values from XML data in NiFi?
- System requirements :
- Step 1: Configure the GetFile
- Step 2: Configure the SplitXML
- Step 3: Configure the EvaluateXPath
- Step 4: Configure the ReplaceText
- Step 5: Configure the MergeContent
- Step 6: Configure the UpdateAttribute to update the filename
- Step 7: Configure the UpdateAttribute to update file extension
- Step 8: Configure the PutFile
- Conclusion
System requirements :
- Install Ubuntu in the virtual machine. Click Here
- Install Nifi in Ubuntu Click Here
Step 1: Configure the GetFile
Creates FlowFiles from files in a directory. NiFi will ignore files it doesn't have at least read permissions for. Here we are getting the file from the local directory.

We scheduled this processor to run every 60 sec in the Run Schedule and Execution as the Primary node in the SCHEDULING tab. Here we are ingesting the drivers_data.xml file drivers data from a local directory; we configured Input Directory and provided the filename.
Step 2: Configure the SplitXML
Splits an XML File into multiple separate FlowFiles, each comprising a child or descendant of the original root element.

In the above, we mentioned split Depth 1. A depth of 1 means split the root's children, whereas a depth of 2 means split the root's children's children and so forth.
The output of the split XML data:

To evaluate the attributes from the XML data, we will be going to use the EvaluateXpath processor.
Step 3: Configure the EvaluateXPath
This processor Evaluates one or more XPaths against the content of a FlowFile. The results of those XPaths are assigned to FlowFile Attributes or are written to the FlowFile itself, depending on the configuration of the processor. XPaths are entered by adding user-defined properties; the property's name maps to the Attribute Name. The result will be placed (if the Destination is flowfile-attribute; otherwise, the property name is ignored). The value of the property must be a valid XPath expression.

As shown in the above image, we are evaluating the attribute values from the XML data. In the data .” row" is parent and "location" is children.
The output of the Evaluated attribute values:

Step 4: Configure the ReplaceText
Updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.

After evaluating the required attributes and their values, we arrange them column by column using ReplaceText below.

The output of the data is as below:

Step 5: Configure the MergeContent
Merges a Group of FlowFiles based on a user-defined strategy and packages them into a single FlowFile. We are merging the single row of 1000 rows as a group; we need to configure it below.

In the above, we need to specify the Delimiter Strategy as Text and In Demarcator value press shift button + Enter then click ok because we need to add every row in the new line.
The output of the data:
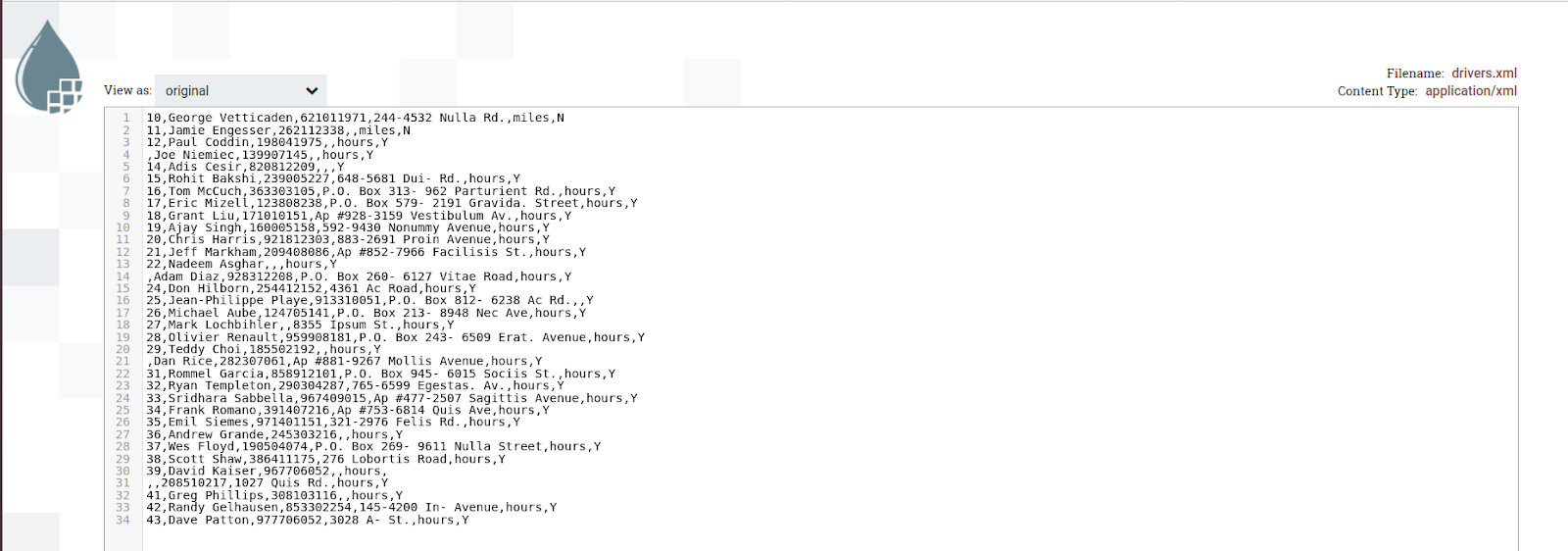
Step 6: Configure the UpdateAttribute to update the filename
Updates the Attributes for a FlowFile using the Attribute Expression Language and/or deletes the attributes based on a regular expression. Here, we will give the name for the FlowFiles.

The output of the file name:

Step 7: Configure the UpdateAttribute to update file extension
Configured the update attribute processor as below; UpdateAttribute adds the file name with the XML extension as an attribute to the FlowFiles.

The output of the file name:

Step 8: Configure the PutFile
Writes the contents of a FlowFile to the local file system, it means that we are storing the converted CSV content in the local directory for that we configured as shown below:

As shown in the above image, we provided a directory name to store and access the file.
The output of the file stored in the local and data looks as below:
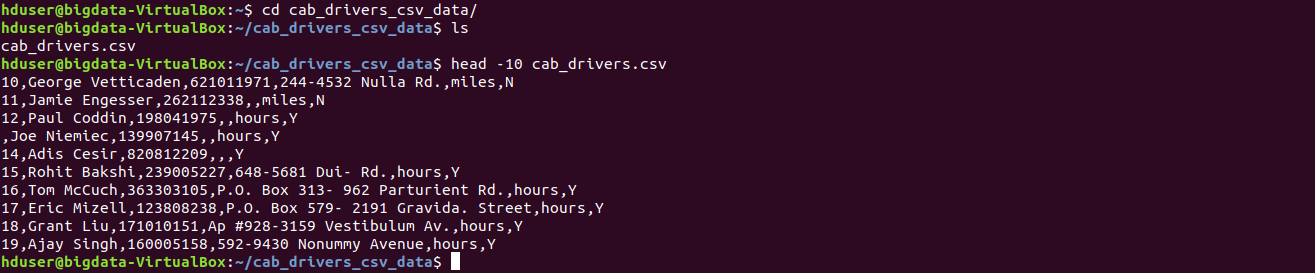
Conclusion
Here we learned to Extract values from XML data in NiFi.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Jingwei Li
ProjectPro is an awesome platform that helps me learn much hands-on industrial experience with a step-by-step walkthrough of projects. There are two primary paths to learn: Data Science and Big Data.... Read More