How to filter columns from a dataframe using PySpark
This recipe helps you filter columns from a dataframe using PySpark
Recipe Objective
In this recipe, we learn how to filter columns from a dataframe using PySpark. The filter() function returns a new dataset formed by selecting those elements of the source on which the function returns true. So, it retrieves only the elements that satisfy the given condition. Let us learn how this can be achieved. Data filtering is majorly used in data cleaning and transformation operations in large-scale distributed big data environments, narrowing the results to only required information in the data, which reduces the query latency on the whole data.
Prerequisites:
Before proceeding with the recipe, make sure the following installations are done on your local EC2 instance.
- Single node Hadoop - click here
- Apache Hive - click here
- Apache Spark -click here
- PySpark - click here
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if PySpark is installed. If not installed, please find the links provided above for installations.
- Type "<your public IP>:7180" in the web browser and log in to Cloudera Manager, where you can check if Hadoop, Hive, and Spark are installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the "Add Services" in the cluster to add the required services in your local instance.
Filtering data in a dataframe using PySpark:
Setup the environment variables for Pyspark, Java, Spark, and python library. As shown below:

Please note that these paths may vary in one's EC2 instance. Provide the full path where these are stored in your instance.
Import the Spark session and initialize it. You can name your application and master program at this step. We provide appName as "demo," The master program is set as "local" in this recipe.
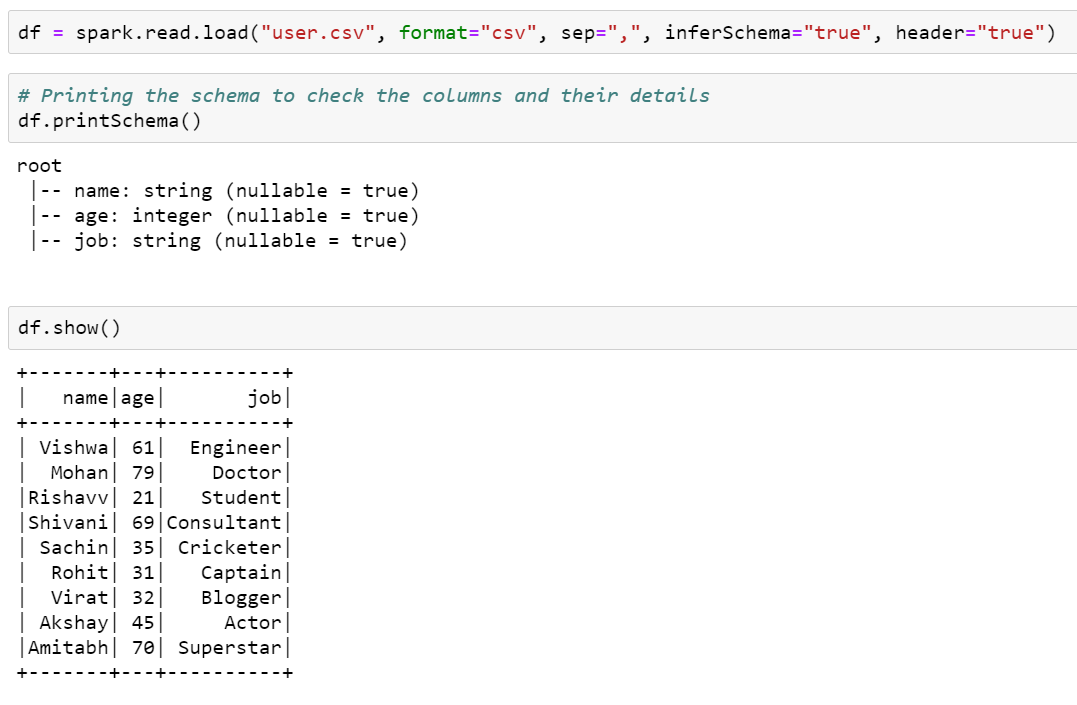
We demonstrated this recipe using a CSV file, "users.csv," in the HDFS.
The CSV file is first read and loaded to create a dataframe, and this dataframe is examined to know its schema (using printSchema() method) and to check the data present in it(using show()).
The filter() function selects specific data from the dataframe based on a given condition. Here, we selected only those columns from the users.csv file where the user's job is "Engineer."

You may also store this data that is selected based on a condition into a new dataframe, which may later be used for querying.

This is how data can be filtered from a dataframe using PySpark.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Abhinav Agarwal
I come from Northwestern University, which is ranked 9th in the US. Although the high-quality academics at school taught me all the basics I needed, obtaining practical experience was a challenge.... Read More