Convert XLSX file to CSV and store it into HDFS in NiFi
This recipe explains how to convert XLSX file to CSV and store it into HDFS in NiFi. Apache NiFi is used as open-source software for automating and managing the data flow between systems.
Recipe Objective: How to use GetFile to get XLSX file from local convert it to CSV and store it into HDFS in NiFi?
In most big data scenarios, Apache NiFi is used as open-source software for automating and managing the data flow between systems. It is a robust and reliable system to process and distribute data. It provides a web-based User Interface to create, monitor, and control data flows. Gathering data using rest API calls is widely used to collect real-time streaming data in Big data environments to capture, process, and analyze the data. In this scenario, we will fetch data from the MySQL database table, and We will do Query operation on FlowFile and store the result into the local.
Table of Contents
System requirements:
- Install Ubuntu in the virtual machine. Click Here
- Install NiFi in Ubuntu Click Here
- Install Hadoop in Ubuntu Click Here
Note: in this scenario, we tried to know How we configure the ConvertExcelToCSVProcessor and use it. We have the XLSX file in the local, and the data output looks as shown below.

Step 1: Configure the GetFile
Creates FlowFiles from files in a directory. NiFi will ignore files it doesn't have at least read permissions for. Here we are getting the file from the local directory.

Here we are ingesting the Employee.xlsx file from a local directory. For that, we have configured the Input Directory and also provided the file name.
Step 2: Configure the ConvertExcelToCSVProcessor
Consumes a Microsoft Excel document and converts each worksheet to CSV. Each sheet from the incoming Excel document will generate a new Flowfile that will be output from this processor. Each output Flow File's contents will be formatted as a CSV file where each row from the excel sheet is output as a new line in the CSV file.

As shown in the above image, we need to provide the value of the Sheets to Extract as Employees.
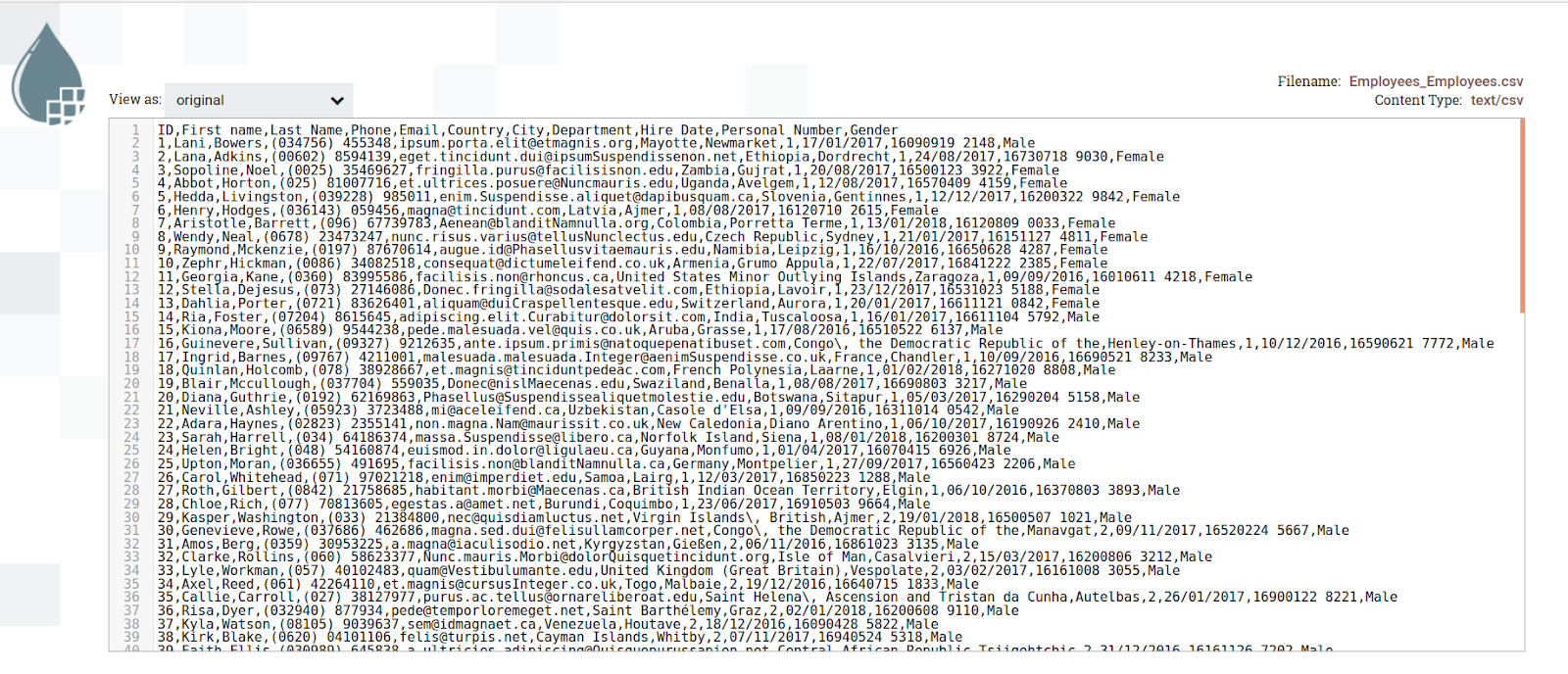
The output of the filename:

The output of the data looks as shown below:
Step 3: Configure the PutHDFS
Write FlowFile data to Hadoop Distributed File System (HDFS). Here we are writing parsed data from the HTTP endpoint and storing it into the HDFS to configure the processor as below.
Note: In the Hadoop configurations, we should provide the 'core-site.xml' and 'hdfs-site.xml' files because Hadoop will search the classpath for a 'core-site.xml' and 'hdfs-site.xml' file or will revert to a default configuration.

Here in the above image, we provided Hadoop configurations resources, and in the directory, we have given a directory name to store files. We have given value append for the conflict resolutions strategy append because it will append to it when new data comes.
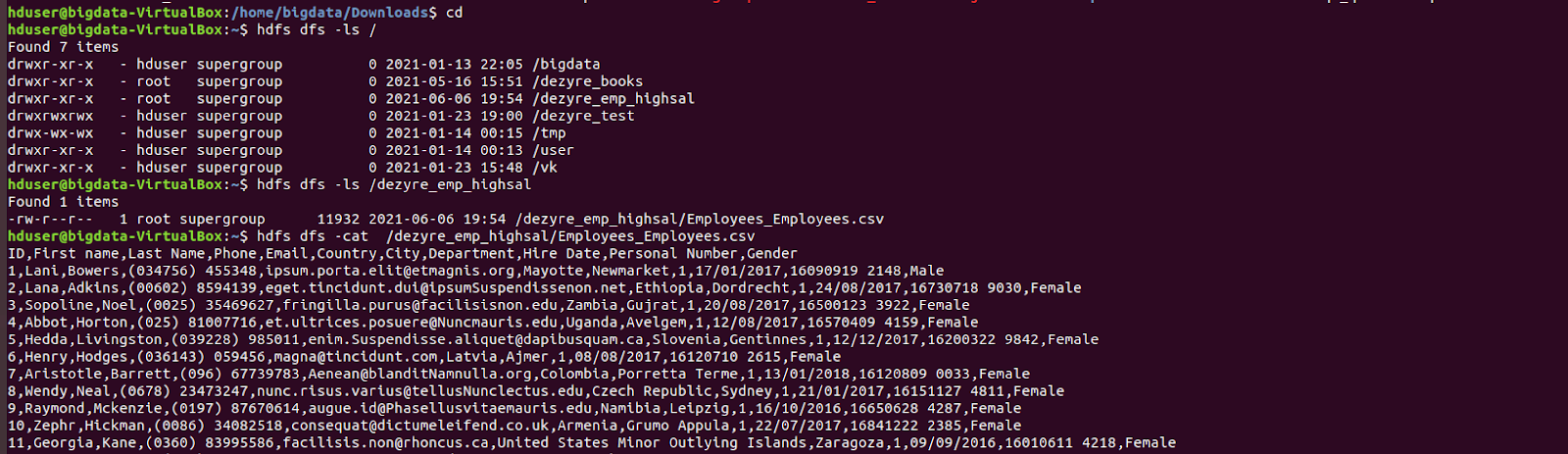
The output of the stored data in the HDFS and its file structure :
Note: if you get any errors on permissions to store through the HDFS, go to Hadoop installed folder and edit the hdfs-site.xml; add the below code:
dfs.permissions false
Conclusion
Here we learned to use GetFile to get XLSX files from local, convert them to CSV, and store them into HDFS in NiFi.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Savvy Sahai
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of... Read More