What are the different file formats supported in Sqoop
This recipe explains what are the different file formats supported in Sqoop
Recipe Objective: What are the different file formats supported in Sqoop?
In this recipe, we see the different file formats supported in Sqoop. Sqoop can import data in various file formats like “parquet files” and “sequence files.” Irrespective of the data format in the RDBMS tables, once you specify the required file format in the sqoop import command, the Hadoop MapReduce job, running at the backend, automatically takes care of it.
Yelp Dataset Analysis with Spark and Parquet
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure the following installations are done on your local EC2 instance.
- Single node Hadoop - click here
- Apache Sqoop -click here
- MySQL - click here
Steps to set up the environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance.
- To do this, type “<your public IP>:7180” in the web browser and log in to Cloudera Manager, where you can check if Hadoop and Sqoop are installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the “Add Services” in the cluster to add the required services in your local instance.
Importing data in different file formats:
Step 1: Log in to MySQL using
mysql -u root -p;
use <user name>
show tables
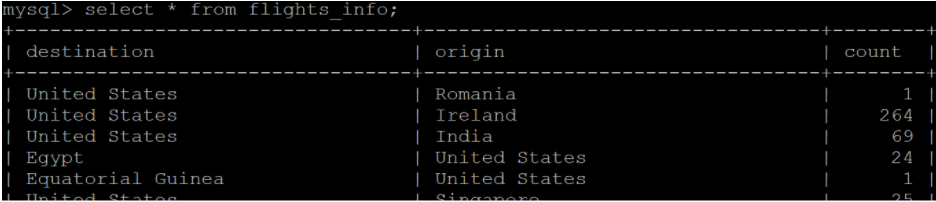
Enter the required credentials. And check tables in the database “test.” We used a “flights_info” table from the “test” database as an example and demonstrated this recipe.

Step 2:View the data in the “flights_info” table, which we further use to demonstrate controlling parallelism in sqoop.
select * from <table name>
Step 3:Before running the “sqoop import” command, make sure that the target directory is not already present. Otherwise, the import command throws an error. To check this, let us try deleting the directory that we wish to use as our target directory.
hadoop -rm -r <target directory>
Here, we are implementing two different file formats and checking how the data is stored in HDFS. We are checking for two directories: “flight_parquet_command” and “flights_sequence_command,” one for each file format.

Step 4: Importing the data into HDFS in “parquet file” format:
Parquet file format is one of the popular file formats used in Apache Hive. It is a column-oriented file format and optimizes the performance of Big Data tools by about 10x on average compared to standard text files.
sqoop import \
--connect jdbc:mysql://localhost/<database name> \
--table <table name> \
--username <username> --password <password> \
--target-dir <target location in HDFS> \
-m <no. of Mapper jobs you wish to create>
--as-parquetfile

Output:

The above command stores the data as a “parquet file” in the target directory.
Step 5: Importing the data into HDFS in “sequential file” format:
The sequence file format is a standard file format while working with Hadoop MapReduce jobs.
sqoop import \
--connect jdbc:mysql://localhost/<database name> \
--table <table name> \
--username <username> --password <password> \
--target-dir <target location in HDFS> \
-m <no. of Mapper jobs you wish to create> \
--as-sequencefile
Output:

The above command stores the data as a “sequence file” in the target directory.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Savvy Sahai
As a student looking to break into the field of data engineering and data science, one can get really confused as to which path to take. Very few ways to do it are Google, YouTube, etc. I was one of... Read More