How to work with analytic functions in Hive
This recipe helps you work with analytic functions in Hive
Recipe Objective: How to work with analytic functions in Hive?
In this recipe, we will work with analytic functions in Hive - CUME_DIST, DENSE_RANK, NTILE, PERCENT_RANK, RANK, ROW_NUMBER.
Access Source Code for Airline Dataset Analysis using Hadoop
Table of Contents
Prerequisites:
Before proceeding with the recipe, make sure Single node Hadoop and Hive are installed on your local EC2 instance. If not already installed, follow the below link to do the same.
Steps to set up an environment:
- In the AWS, create an EC2 instance and log in to Cloudera Manager with your public IP mentioned in the EC2 instance. Login to putty/terminal and check if HDFS and Hive are installed. If not installed, please find the links provided above for installations.
- Type "<your public IP>:7180" in the web browser and log in to Cloudera Manager, where you can check if Hadoop is installed.
- If they are not visible in the Cloudera cluster, you may add them by clicking on the "Add Services" in the cluster to add the required services in your local instance.
Working with analytics functions in Hive:
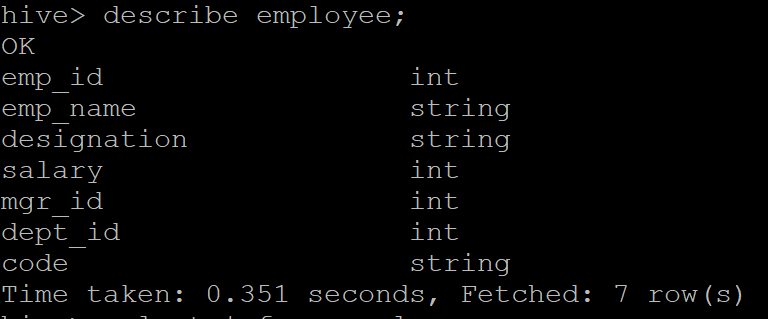
Throughout this recipe, we used the "employee" table present in our database. Following is the schema of the table.
CUME_DIST: Below is the sample output for the query that uses the CUME_DIST() window function to calculate each employee's cumulative distribution of salary.

DENSE_RANK: Below is the sample output for the query that uses the DENSE_RANK() window function to calculate each employee's cumulative distribution of salary.

NTILE: Below is the sample output that uses the NTILE window function to divide the employees' salaries into three groups and list the salary in ascending order.

PERCENT_RANK: Below is the sample output that uses the PERCENT_RANK window function to calculate the percentile rank for employees' salaries.

RANK: The following query uses the RANK() window function to rank the salary of all the employees.

ROW_NUMBER: The following query uses the ROW_NUMBER() window function to number the salaries for all the employees.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Anand Kumpatla
ProjectPro is a unique platform and helps many people in the industry to solve real-life problems with a step-by-step walkthrough of projects. A platform with some fantastic resources to gain... Read More