Slowly changing dimensions SCD type 2 in spark SQL
This recipe explains implementation of SCD slowly changing dimensions type 2 in spark SQL. SCD Type 2 tracks historical data by creating multiple records for a given natural key in the dimensional tables. This notebook demonstrates how to perform SCD Type 2 operation using MERGE operation.
Recipe Objective: Implementation of SCD (slowly changing dimensions) type 2 in spark SQL
SCD Type 2 tracks historical data by creating multiple records for a given natural key in the dimensional tables. This notebook demonstrates how to perform SCD Type 2 operation using MERGE operation. Suppose a company maintains a table with the customers and their address, and they want to keep a history of all the addresses a customer had along with the date range when each address was valid. Let's define the schema using Scala case classes.
Build Log Analytics Application with Spark Streaming and Kafka
Implementation Info:
- Databricks Community Edition click here
- Spark-SQL
- storage - Databricks File System(DBFS)
Table of Contents
Step 1: Creation of Customers delta table
This is the slowly changing table that we want to update. For every customer, there many any number of addresses. But for each address, there is a range of dates, effectiveDate to endDate, in which that address was effectively the current address. In addition, there is another field current that is true for the address that is currently valid for each customer. There is only one address and one row for each customer where current is true; for every other row, it is false.
Here we have used the databricks display function to visualize data.
import java.sql.Date
import java.text._
import spark.implicits
case class CustomerUpdate(customerId: Int, address: String, effectiveDate: Date)
case class Customer(customerId: Int, address: String, current: Boolean, effectiveDate: Date, endDate: Date)
implicit def date(str: String): Date = Date.valueOf(str)
sql("drop table if exists customers")
Seq(
Customer(1, "old address for 1", false, null, "2018-02-01"),
Customer(1, "current address for 1", true, "2018-02-01", null),
Customer(2, "current address for 2", true, "2018-02-01", null),
Customer(3, "current address for 3", true, "2018-02-01", null)
).toDF().write.format("delta").mode("overwrite").saveAsTable("customers")
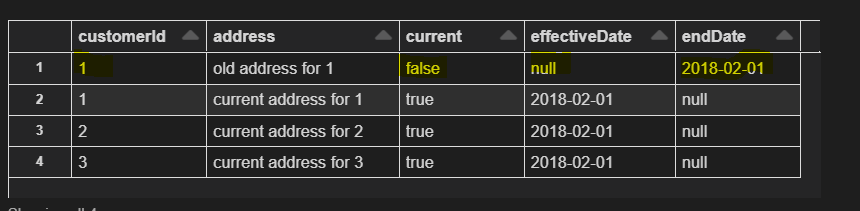
display(table("customers").orderBy("customerId"))
Refer to the image below to visualize customers table data
Step 2: Creation of Updates delta table
This is an updated table that has the new addresses. For each customer, it has the new address the date from which it is effective. We are using the same case class and ignoring the current and endDate; they are not used for convenience. This table must have one row per customer and the effective date correctly set.
We need to make sure that the effectiveDate is set in the source test data because this will be copied to the customers' table after SCD Type 2 Merge, and we need to be cautious there is only one row per customer. Here the "updates" acts as a temporary view created over DataFrame.
Seq(
CustomerUpdate(1, "new address for 1", "2018-03-03"),
CustomerUpdate(3, "current address for 3", "2018-04-04"), // new address same as current address for customer 3
CustomerUpdate(4, "new address for 4", "2018-04-04")
).toDF().createOrReplaceTempView("updates")
display(table("updates"))
Refer to the image below to visualize updated table data. If you observe data, a customer with ID 4 is a new record, and customers with ID 1 is getting updated with addresses.

Step 3: Merge Operation for SPARK-SQL
Merge statement to perform SCD Type 2
This merge statement simultaneously does inserts and updates both for each customer in the source table. Inserts the new address with its current set to true, updates the previous, current row to set current to false, and updates the endDate from null to the effectiveDate from the source.
val merge_query = """MERGE INTO customers
USING (
SELECT updates.customerId as mergeKey, updates.*
FROM updates
UNION ALL
SELECT NULL as mergeKey, updates.*
FROM updates JOIN customers
ON updates.customerid = customers.customerid
WHERE customers.current = true AND updates.address <> customers.address
) staged_updates
ON customers.customerId = mergeKey
WHEN MATCHED AND customers.current = true AND customers.address <> staged_updates.address THEN
UPDATE SET current = false, endDate = staged_updates.effectiveDate
WHEN NOT MATCHED THEN
INSERT(customerid, address, current, effectivedate, enddate)
VALUES(staged_updates.customerId, staged_updates.address, true, staged_updates.effectiveDate, null)"""
spark.sql(merge_query)
display(table("customers").orderBy("customerId"))
As a result, customer ID 1 got updated, and customer ID 4 was inserted newly. Whereas record with customer ID 3 doesn't undergo any changes. The output can be seen in the below image.

Conclusion:
In this example, we have done an SCD Type 2 merge operation using spark-SQL on the delta table in databricks. And we understood how the delta tables undergo the updates and inserts.
Download Materials
{kind=link}
{kind=link}
{kind=link}

What Users are saying..

Ameeruddin Mohammed
I come from a background in Marketing and Analytics and when I developed an interest in Machine Learning algorithms, I did multiple in-class courses from reputed institutions though I got good... Read More